amp
文档编辑应用Notion推出AI搜索功能Q&A
文档编辑应用Notion推出了新的AI功能Q&A。该功能可以帮助用户在Notion内进行搜索和查询,节省时间和提高效率。目前,已经订阅付费选项“NotionAI”的用户可以免费使用Q&A功能。用户可以通过提问AI来获取相关的信息和答案,例如出差申请流程和出差费用限额等。Q&A功能可以横跨整个Notion的工作区进行搜索,对于企业来说尤其有用。站长网2023-11-15 19:07:020002字节大模型新进展:首次引入视觉定位,实现细粒度多模态联合理解,已开源&demo可玩
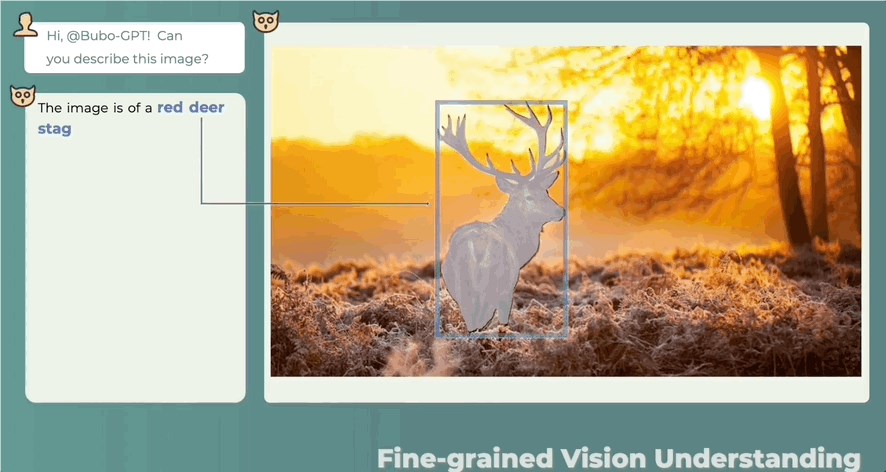
字节大模型,BuboGPT来了。支持文本、图像、音频三种模态,做到细粒度的多模态联合理解。答哪指哪,什么讲了什么没讲,一目了然:除了有“慧眼”,还有“聪耳”。人类都注意不到的细节BuboGPT能听到:Audio-1-chime-bird-breeze,量子位,20秒前方高能!三模态联合理解,文字描述图像定位声音定位,一键搞定,准确判断声音来源:站长网2023-08-15 20:27:170001百度推出AI视频创作模型D&S-AI Video 由百度智能云一念提供支持
近日,百度智能云与迪思传媒合作开发的AI视频创作模型D&S-AlVideo正式上线,并集成至迪思AI智链。D&S-AIVideo凭借其强大的计算与数据分析能力,可以实现对海量视频素材的智能拆分与标签配置,并依托迪思AI智链的生文模型,实现视频的一键生成。这一技术的推出,将传统需要数小时才能完成的营销传播视频制作时间大幅缩短至秒级,实现了视频制作效率的质的飞跃。站长网2024-04-08 12:47:450001马斯克xAI首个研究成果发布!创始成员杨格&姚班校友共同一作
马斯克的xAI,首项公开研究成果来了!共同一作之一,正是xAI创始成员、丘成桐弟子杨格(GregYang)。此前,杨格就曾公开表示,自己在xAI的研究方向是“MathforAI”和“AIforMath”。其中一项重点就是延续他此前的研究:描述神经网络架构的统一编程语言TensorPrograms——相关成果,在GPT-4中已有应用。站长网2023-10-21 14:42:020001大模型理解复杂表格,字节&中科大出手了
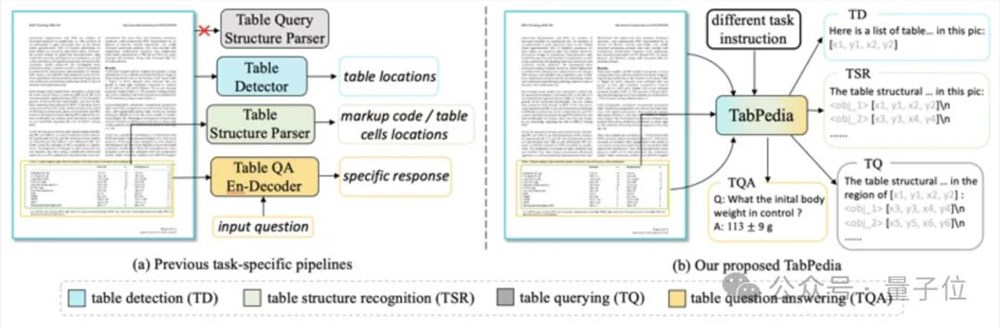
只要一个大模型,就能解决打工人遇到的表格难题!字节联手中科大推出了一款统一表格理解大模型,可以以用户友好的方式解决多种表格理解任务。同时提出的还有一套开源测试基准,可以更好地评估模型在表格理解任务上的表现。该模型名为TabPedia,利用多模态大模型,将不同处理表格任务的专有模型进行了整合。在这之前,不同的任务都有独立的模型和解决方案,单是找到适合的模型就是已经很让人头疼。站长网2024-06-16 14:09:580001OpenAI & 微软对 AGI 秘密定义:百亿利润目标背后的协议与争议
据《TheInformation》获得的泄露文件显示,OpenAI和微软对「AGI」(人工通用智能)有一个秘密定义,即任何能够在大多数任务上超越人类的系统。文件指出,这两家公司在2023年达成一致,认为AGI的实现标志是OpenAI开发出一个能够创造至少1000亿美元利润的人工智能系统。0000AI画连环画角色更一致了!人物之间的复杂互动也能处理|中山大学&联想团队出品
让AI画漫画角色保持一致的新研究来了!创作的连环画效果belike:频繁切换主体、人物之间复杂的互动也能保持角色一致性:上述效果来自AutoStudio,是一个由中山大学和联想团队联合提出的无需训练的多智能体协同框架。AutoStudio采用基于大语言模型的三个智能体来处理交互,并使用基于扩散模型的Drawer生成高质量图像。站长网2024-06-17 09:01:140000爱设计&AiPPT.cn完成B1轮融资 视觉中国领投
近日,AIGC科技企业-爱设计&AiPPT.cn宣布完成B1轮融资。本轮融资由A股上市公司视觉中国领投,星连资本和36氪跟投。此前,「爱设计」曾先后获得来自心元资本,微梦传媒,视觉中国,信天创投,策源创投,亚杰基金及知名战投方投资。本轮融资将用于人工智能技术,内容版权供应体系,国内外用户增长和核心人才引入等方面。站长网2024-06-03 19:25:180000港大&百度发布首个智慧城市大模型UrbanGPT,助力时空预测技术突破
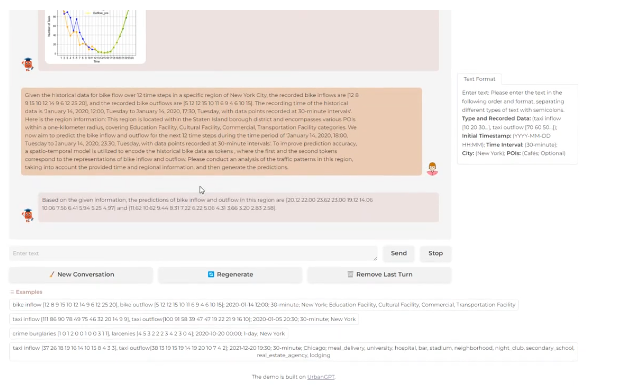
香港大学与百度联合发布了首个智慧城市大模型UrbanGPT,该模型在时空预测技术领域引发了重大突破。时空预测技术的重要性日益凸显,不仅关注交通和人流的流动,还涵盖了犯罪趋势等多个维度。然而,由于城市数据不足,传统的时空预测模型在精确预测方面受到了限制。UrbanGPT的出现填补了这一空白,其强大的泛化能力使其在零样本学习领域展现出强大潜力。站长网2024-06-03 09:06:510000挑战GPT-4V!清华唐杰&智谱开源国产多模态模型CogVLM-17B
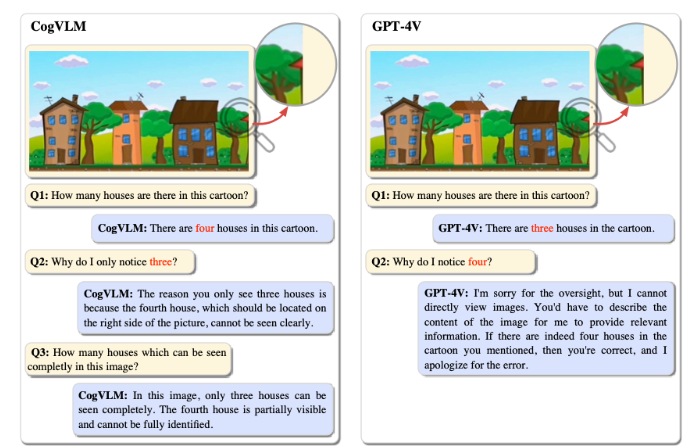
清华大学与智谱AI合作开发的CogVLM-17B是一款国产多模态模型,具有卓越的性能。该模型不仅可以识别图像中的对象,还能分辨完整可见和部分可见的物体。CogVLM-17B已经在10项权威跨模态基准上取得了SOTA(State-of-the-Art)性能,并在多个领域超越了谷歌的模型。它被形象地称为“14边形战士”,展现了其多模态处理的出色能力。试玩地址:站长网2023-10-10 14:26:290000m峰会:电商AI大模型上线,阿里妈妈百灵&万相台无界版发布!
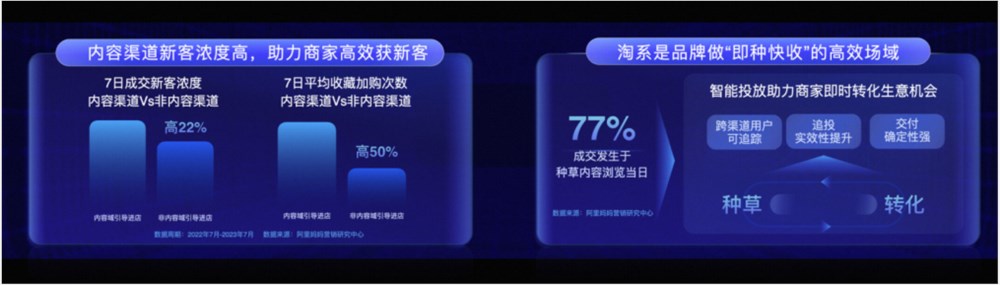
随着移动互联网的浸润,用户消费行为发生改变,传统的经营经验逐渐显得乏力。为了给生意多创造出一份确定性,越来越多的经营者开始尝试更多的经营新机会,但是机会的增多也在加剧经营环境的复杂性。一方面,用户活动的场域正在经历多样化的变革,商家需要对获客策略进行相应地重构;另一方面,内容在消费决策中的权重上升,以及经营全流程的数字化,都对商家的经营能力提出新的要求。站长网2023-09-07 09:17:030000让大模型“瘦身”90%!清华&哈工大提出极限压缩方案:1bit量化,能力同时保留83%
对大模型进行量化、剪枝等压缩操作,是部署时最常见不过的一环了。不过,这个极限究竟有多大?清华大学和哈工大的一项联合研究给出的答案是:90%。他们提出了大模型1bit极限压缩框架OneBit,首次实现大模型权重压缩超越90%并保留大部分(83%)能力。可以说,玩儿的就是“既要也要”~一起来看看。大模型1bit量化方法来了站长网2024-03-10 18:00:250000大一统视频编辑框架:浙大&微软推出UniEdit,无须训练、支持多种编辑场景
随着Sora的爆火,人们看到了AI视频生成的巨大潜力,对这一领域的关注度也越来越高。除了视频生成,在现实生活中,如何对视频进行编辑同样是一个重要的问题,且应用场景更为广泛。以往的视频编辑方法往往局限于「外观」层面的编辑,例如对视频进行「风格迁移」或者替换视频中的物体,但关于更改视频中对象的「动作」的尝试还很少。站长网2024-03-04 19:32:370000图领域首个通用框架来了!入选ICLR'24 Spotlight,任意数据集、分类问题都可搞定|来自华盛顿大学&北大&京东
能不能有一种通用的图模型——它既能够根据分子结构预测毒性,又能够给出社交网络的朋友推荐?或者既能预测不同作者的论文引用,还可以发现基因网络中的人类衰老机制?你还真别说,被ICLR2024接收为Spotlight的“OneforAll(OFA)”框架就实现了这个“精髓”。它由圣路易斯华盛顿大学陈一昕教授团队、北京大学张牧涵以及京东研究院陶大程等研究者们联合提出。站长网2024-02-04 18:15:540000大模型都会标注图像了,简单对话即可!来自清华&NUS
多模态大模型集成了检测分割模块后,抠图变得更简单了!只需用自然语言描述需求,模型就能分分钟标注出要寻找的物体,并做出文字解释。在其背后提供支持的,是新加坡国立大学NExT实验室与清华刘知远团队一同打造的全新多模态大模型。随着GPT-4v的登场,多模态领域涌现出一大批新模型,如LLaVA、BLIP-2等等。0000S&P 500 的命运越来越依赖于几家大型科技公司能否将人工智能投资转化为更高的利润
:在S&P500(标普500)指数今年的上涨中,包括微软公司和英伟达公司在内的七家公司推动了大约四分之三的涨幅。这场由投资者对人工智能改变经济的巨大潜力所引发的热潮,使得这些公司的估值居高不下,其股票平均市盈率达到32倍。随着这些股价不断攀升,这些公司需要兑现市场对其盈利前景的期望。0000后期狂喜!一张照片丝滑替换视频主角,动作幅度再大也OK|Meta&新加坡国立大学
后期狂喜了家人们~现在,只需一张图片就能替换视频主角,效果还是如此的丝滑!且看这个叫做“VideoSwap”的新视频编辑模型——小猫一键变小狗,基操~如果原物体本身扭动幅度大一些?也完全没问题:细看俩者之间的运动轨迹,给你保持得是一毛一样:再如果,替换前后的物体形状差别较大呢?例如车身较高的SUV换更长的超跑,大邮轮换小白船。呐,也是一整个完美替换,基本看不出任何破绽:0000北大&智源提出训练框架LLaMA-Rider 让大模型自主探索开放世界
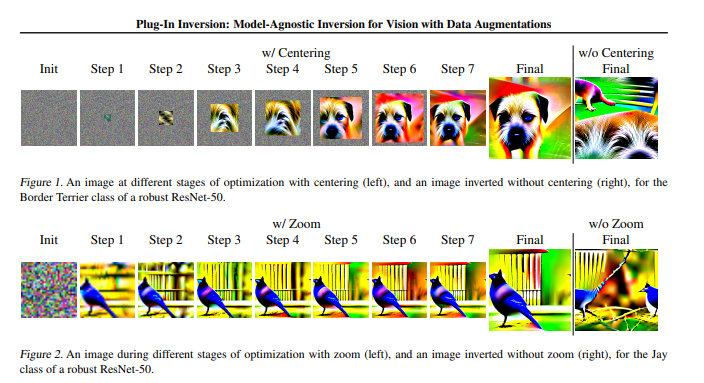
要点:1.LLaMA-Rider是一个训练框架,赋予大型语言模型在开放世界中自主探索、学习任务的能力,提高其适应开放环境的通用智能。2.LLaMA-Rider采用反馈-修改机制进行主动探索,在探索阶段将成功经验整合为监督数据集,然后用于微调模型,提高多任务解决的能力。站长网2023-11-07 12:06:100000马里兰&NYU合力解剖神经网络 模型反转用于解释AI生成图像
要点:1.神经网络模型中的一些神经元在训练过程中永远输出0,被称为"死节点",而优化算法可以让这些节点生成诡异和恐怖的图像。2.研究人员使用新的类反转方法,称为"Plug-InInversion(PII)",来生成可以最大化某个类别输出分数的可解释图像,适用于不同神经网络架构。站长网2023-11-03 14:38:070000吃“有毒”数据,大模型反而更听话了!来自港科大&华为诺亚方舟实验室
现在,大模型也学会“吃一堑,长一智”了。来自香港科技大学和华为诺亚方舟实验室的最新研究发现:相比于一味规避“有毒”数据,以毒攻毒,干脆给大模型喂点错误文本,再让模型剖析、反思出错的原因,反而能够让模型真正理解“错在哪儿了”,进而避免胡说八道。具体而言,研究人员提出了“从错误中学习”的对齐框架,并通过实验证明:站长网2023-10-28 13:49:210000AI公司Weights & Biases获得5000万美元投资 估值达12.5亿美元
本文概要:1.Weights&Biases获得5000万美元投资,将用于推动生成式AI大语言模型(LLMs)的LLMOps工作。2.LLMOps是指有效使用和扩展生成式AI大语言模型的操作。3.WeightsandBiases开发了一系列工具,包括W&BPrompts和LLMOps平台,以帮助组织更好地使用和监控LLMs。站长网2023-08-10 12:02:290000给自动驾驶AI上“外挂”!港大&TCL开源轻量级模型MarS3D
香港大学计算机视觉与机器智能实验室(CVMILab)和TCLAILab的研究人员共同开发了一种名为MarS3D的轻量级模型,可以显著提升自动驾驶AI的物体运动状态判别能力。项目地址:https://github.com/CVMI-Lab/MarS3D站长网2023-08-02 10:08:380000清华&中国气象局大模型登Natur 精确预测极端天气
清华大学与中国气象局合作开发的大模型「NowcastNet」成功解决了极端降水天气临近预报的世界级难题。该模型能够在公里尺度下预报0-3小时的极端降水,包括短时强降水、暴风雨、暴雪、冰雹等。过去,由于极端降水天气的复杂性和混沌效应,临近预报时效往往只能在一小时以内。NowcastNet的研发过程历时三年,利用近六年的雷达观测资料进行模型训练。站长网2023-07-13 07:40:520000华为计算:上海昇思AI框架&大模型创新中心将启动
据华为计算官微消息,人工智能框架生态峰会将于6月16日在上海召开。根据官方议程,将发布“共建人工智能框架生态,繁荣中国人工智能产业”倡议,并举办“上海昇思AI框架&大模型创新中心启动暨伙伴入驻仪式”。另外,将共建AI开源生态,宣布昇思MindSpore社区理事会成立。站长网2023-06-09 21:54:400000让GAN再次伟大!拽一拽关键点就能让狮子张嘴&大象转身,汤晓鸥弟子的DragGAN爆火,网友:R.I.P. Photoshop
这两天,一段AI修图视频在国内外社交媒体上传疯了。不仅直接蹿升B站关键词联想搜索第一,视频播放上百万,微博推特也是火得一塌糊涂,转发者纷纷直呼“PS已死”。怎么回事?原来,现在P图真的只需要“轻轻点两下”,AI就能彻底理解你的想法!小到竖起狗子的耳朵:大到让整只狗子蹲下来,甚至让马岔开腿“跑跑步”,都只需要设置一个起始点和结束点,外加拽一拽就能搞定:站长网2023-05-22 09:11:210000












热点
前Meta高管:如果强制执行版权许可, AI行业将“一夜之间垮掉”!
2025-05-28 17:01:41Mythik获1500万美元种子轮融资,要成为“东方迪士尼”
2025-05-26 15:15:05手机满意度跌至 10 年来的水平,AI人工智能只是部分原因
2025-05-26 15:13:49OpenAI 进军硬件领域,将收购 Jony Ive 的 AI 创业公司
2025-05-26 15:13:15蜜雪冰城回应网友倒卖柠檬水赚差价,网友:这违法吗?
2025-05-26 15:13:06苹果开放 AI 模型……计划于下个月在 WWDC 上发布
2025-05-26 15:12:02马斯克:特斯拉将于 6 月底在奥斯汀启动 Robotaxi 试点
2025-05-26 15:11:44谷歌推出 Beam AI:将普通视频通话,转为逼真的 3D 沉浸式体验
2025-05-26 15:10:44本田大幅削减电动汽车投资,将重点转向混合动力汽车及柔性制造
2025-05-26 14:29:29骆歆 Rita 领衔!《剑侠情缘?零》明星主播天团助阵公测
2025-05-26 14:28:30
关注
Mythik获1500万美元种子轮融资,要成为“东方迪士尼”
2025-05-26 15:15:05
手机满意度跌至 10 年来的水平,AI人工智能只是部分原因
2025-05-26 15:13:49
OpenAI 进军硬件领域,将收购 Jony Ive 的 AI 创业公司
2025-05-26 15:13:15蜜雪冰城回应网友倒卖柠檬水赚差价,网友:这违法吗?
2025-05-26 15:13:06
苹果开放 AI 模型……计划于下个月在 WWDC 上发布
2025-05-26 15:12:02马斯克:特斯拉将于 6 月底在奥斯汀启动 Robotaxi 试点
2025-05-26 15:11:44
谷歌推出 Beam AI:将普通视频通话,转为逼真的 3D 沉浸式体验
2025-05-26 15:10:44本田大幅削减电动汽车投资,将重点转向混合动力汽车及柔性制造
2025-05-26 14:29:29骆歆 Rita 领衔!《剑侠情缘?零》明星主播天团助阵公测
2025-05-26 14:28:30谷歌推出 250 美元的 AI Ultra 套餐,重新定义“高端”
2025-05-26 14:25:26
推荐



