字节大模型新进展:首次引入视觉定位,实现细粒度多模态联合理解,已开源&demo可玩
字节大模型,BuboGPT来了。
支持文本、图像、音频三种模态,做到细粒度的多模态联合理解。
答哪指哪,什么讲了什么没讲,一目了然:
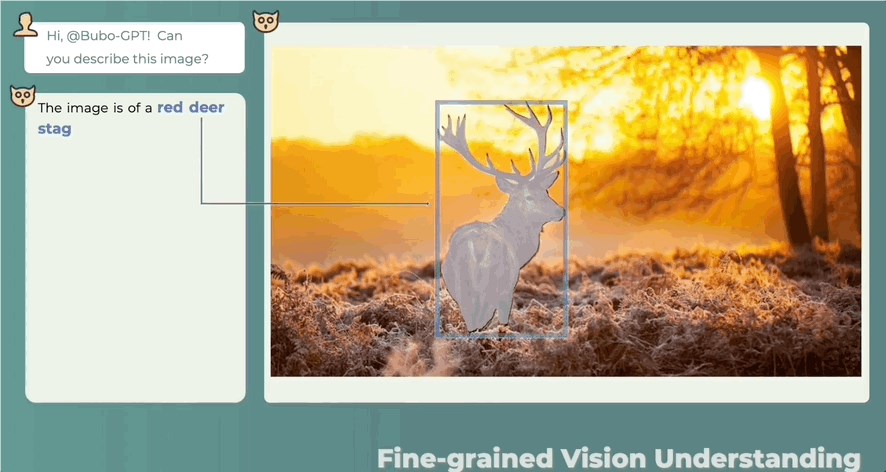
除了有“慧眼”,还有“聪耳”。人类都注意不到的细节BuboGPT能听到:
Audio-1-chime-bird-breeze,量子位,20秒

前方高能!
三模态联合理解,文字描述 图像定位 声音定位,一键搞定,准确判断声音来源:
Audio-7-dork-bark,量子位,6秒
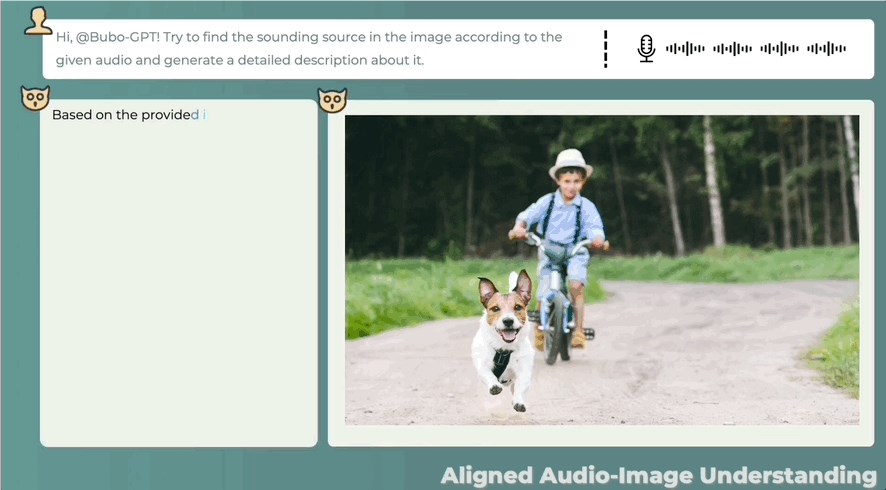
别着急,还没完!
即使音频和图像之间没有直接关系,也可以合理描述两者之间的可能关系,看图辨音讲故事也可以:
Audio-11-six-oclock,量子位,1分钟
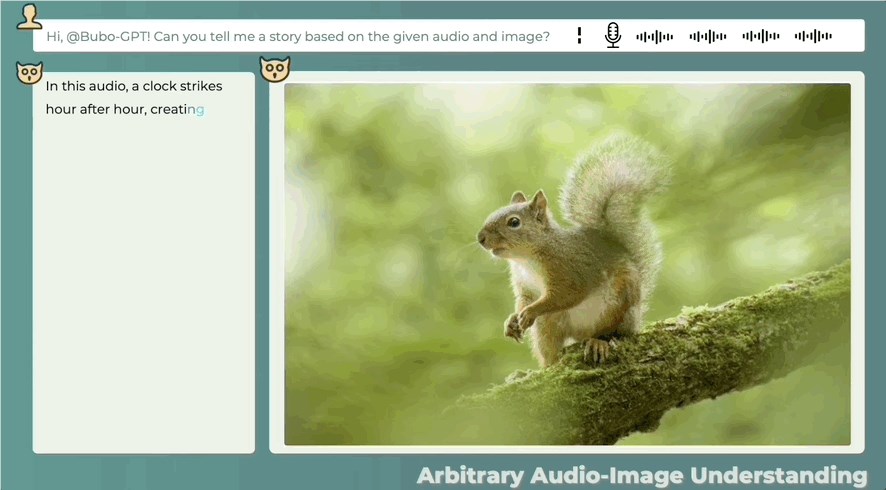
这么一看,BuboGPT干点活,够“细”的。
研究人员表示:
MiniGPT-4,LLaVA和X-LLM等最近爆火的多模态大模型未对输入的特定部分进行基础性连接,只构建了粗粒度的映射。
而BuboGPT利用文本与其它模态之间丰富的信息且明确的对应关系,可以提供对视觉对象及给定模态的细粒度理解。
因此,当BuboGPT对图像进行描述时,能够指出图中对象的具体位置。

BuboGPT:首次将视觉连接引入LLM
除了上面作者分享在YouTube的示例,研究团队在论文中也展示了BuboGPT玩出的各种花样。
活久见青蛙弹琴!这样的图BuboGPT也能准确描述吗?
一起康康回答得怎么样:

不仅能够准确描述青蛙的姿势,还知道手摸的是班卓琴?
问它图片都有哪些有趣的地方,它也能把图片背景里的东西都概括上。
BuboGPT“眼力 听力 表达力测试”,研究人员是这样玩的,大家伙儿先来听这段音频。
Audio-9-hair-dryer,量子位,5秒
再来看看BuboGPT的描述怎么样:
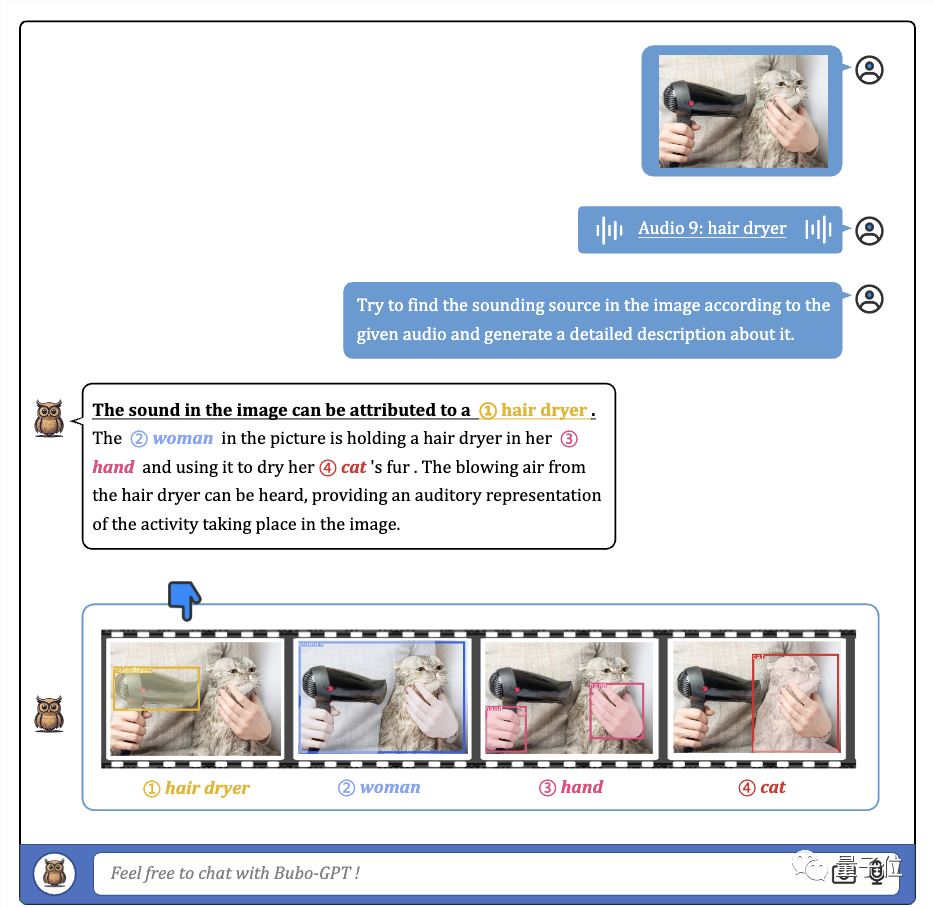
图片上的人的性别、声音来源、图片中发生的事情,BuboGPT都能准确理解。
效果这么好,是因为字节这次用了将视觉定位引入LLM的方法。
具体方法我们接着往下看。
BuboGPT的架构是通过学习一个共享的语义空间,并进一步探索不同视觉对象和不同模态之间的细粒度关系,从而实现多模态理解。
为探索不同视觉对象和多种模态之间的细粒度关系,研究人员首先基于SAM构建了一个现成的视觉定位pipeline。
这个pipeline由标记模块(Tagging Module)、定位模块(Grounding Module)和实体匹配模块(Entity-matching Module)三个模块组成。
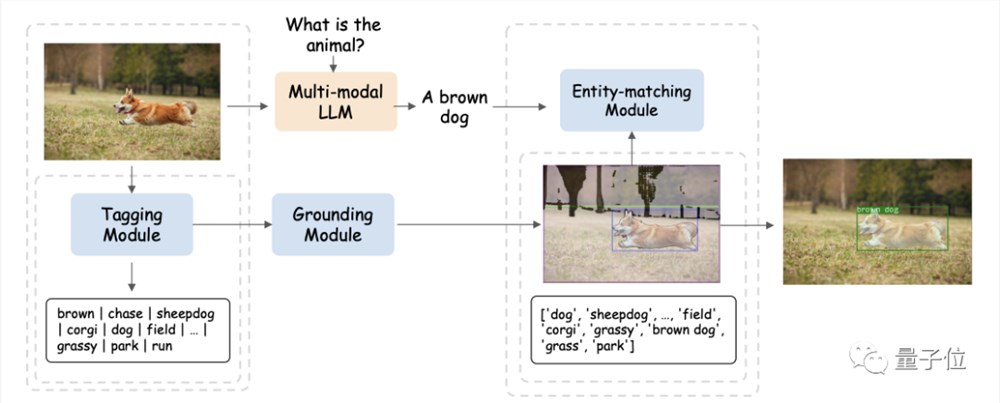
流程大概是这样婶儿的:
首先,标记模块是一个预训练模型,可以生成与输入图像相关的多个文本标签。
基于SAM的定位模块进一步定位图像上与每个文本标签相关的语义掩模或边界框。
然后,实体匹配模块利用LLM的推理能力从标签和图像描述中检索匹配的实体。
研究人员就是通过这种方式,使用语言作为桥梁将视觉对象与其它模态连接起来。
为了让三种模态任意组合输入都能有不错的效果,研究人员采用了类似于Mini-GTP4的两阶段走训练方案:
单模态预训练和多模态指令调整。
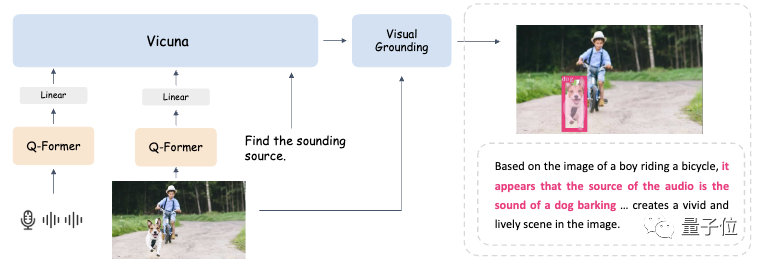
具体而言,BuboGPT使用了ImageBind作为音频编码器,BLIP-2作为视觉编码器,以及Vicuna作为预训练LLM。
在单模态预训练阶段,在大量的模态-文本配对数据上训练相应的模态Q-Former和线性投影层。
对于视觉感知,研究人员仅对图像标题生成部分进行投影层的训练,并且保持来自BLIP2的Q-Former固定。
对于音频理解,他们同时训练了Q-Former和音频标题生成部分。
在这两种设置下都不使用任何提示(prompt),模型仅接收相应的图像或音频作为输入,并预测相应的标题(caption)。

△不同输入的指令遵循示例
在多模态指令调整阶段,构建了一个高质量的多模态指令数据集对线性投影层进行微调,包括:
图像-文本:使用MiniGPT-4和LLaVa中的两个数据集进行视觉指令调优。
音频-文本:基于Clotho数据集构建了一系列表达性和描述性数据。
音频-图像-文本:基于VGGSS数据集构建了<音频,图像,文本>三模态指导调优数据对,并进一步引入负样本来增强模型。
值得注意的是,通过引入负样本“图像-音频对”进行语义匹配,BuboGPT可以更好地对齐,多模态联合理解能力更强。
目前BuboGPT代码、数据集已开源,demo也已发布啦,我们赶紧上手体验了一把。
demo浅玩体验
BuboGPT demo页面功能区一目了然,操作起来也非常简单,右侧可以上传图片或者音频,左侧是BuboGPT的回答窗口以及用户提问窗口:
上传好照片后,直接点击下方第一个按钮来上传拆分图片:

就拿一张长城照片来说,BuboGPT拆成了这个样子,识别出了山、旅游胜地以及城墙:
当我们让它描述一下这幅图时,它的回答也比较具体,基本准确:

可以看到拆分框上的内容也有了变化,与回答的文本内容相对应。
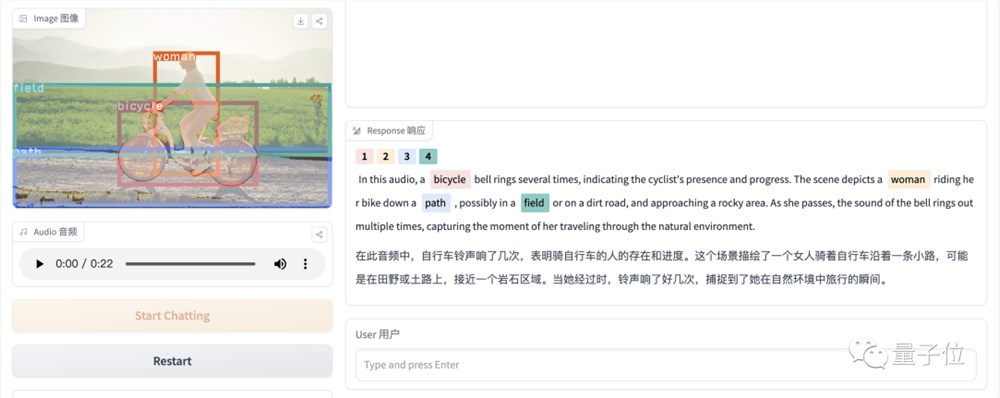
再来一张图片,并带有一段音频,BuboGPT也正确匹配了声音来源:
Audio-8-bicycle_bell,量子位,22秒
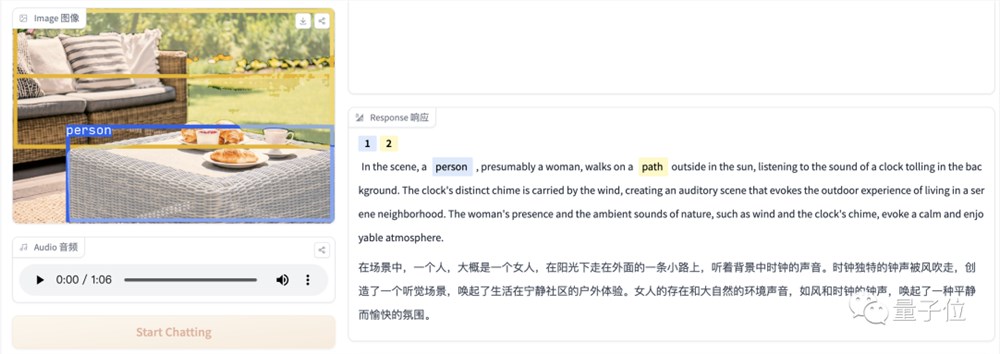
当然,它也会出现识别不成功,表述错误的情况,比如说下面这张图中并没有人,音频也只是钟声,但它的描述和图片似乎并不搭边。
感兴趣的家人赶紧亲自上手试试~~
传送门:
[1]https://bubo-gpt.github.io/
[2]https://huggingface.co/spaces/magicr/BuboGPT(demo)
—完—
迭代后首波实测!360智脑一键联网,代码超强,AI诈骗一眼看穿
【新智元导读】360大模型(又)交卷了!作为国内首个能联网的大模型,360智脑给了我们怎样的惊喜?话不多说,新鲜出炉的第一手实测来了。不得不说,自从GPT大模型混战开赛之后,教主周鸿祎可谓是存在感十足,到处都能看到他活跃的身影。在某场直播中,小编亲眼见证了教主妙语连珠、金句频出地连讲三个小时,从GPT大模型的内在原理,讲到未来AI毁灭人类的科幻式展望,很专业,很硬核。站长网2023-05-23 13:56:260000vivo S18 Pro发布:售价3199元起
vivoS18Pro正式发布,售价分别为12GB256GB售价3199元,16GB256GB售价3499元,16GB512GB售价3699元。vivoS18Pro采用6.78英寸120Hz朝阳护眼屏,搭载联发科天玑9200芯片,前置5000万像素,电池5000毫安时并支持80W有线闪充。0001因tagDiv插件漏洞,数千个WordPress网站遭到黑客攻击
文章概要:以下是对文章的三个要点总结:1.WordPress网站中的tagDivComposer插件存在跨站脚本(XSS)漏洞,已经被恶意利用。2.恶意代码让网站访问者被重定向到各种诈骗网站。3.自2017年以来,一个被称为Balada的持续攻击者已经利用该漏洞控制了超过100万个网站。站长网2023-10-10 17:56:010000重磅!传月之暗面Kimi内测内容社区产品 预计月底上线
快科技4月14日消息,今日,有媒体报道,月之暗面Kimi将推出首个内容社区产品,目前正在进行灰度测试,预计本月底正式上线。这款产品于去年末启动,之前一直维持小范围测试状态,是Kimi在用户体验上的最新尝试。对于相关产品的具体信息,月之暗面已在规划全新的内容功能模块,其定位类似于传统内容平台的信息流模式。对于月之暗面来说,这一战略布局不仅有望提升产品用户留存率,也为商业化变现开辟更多可能性。0000高薪主播,濒临“下岗”?
2023年,AI主播正在直播电商行业自上而下地“流行”开来。4月25日,腾讯云发布智能小样本数字人生产平台,宣称三分钟完成建模、成本降低至数千元,即利用技术进行人物外貌和声音模型的训练和搭建,从而1:1还原主播,创造一个“AI替身”。图源:腾讯云数智人生成效果站长网2023-07-26 09:59:220001