吃“有毒”数据,大模型反而更听话了!来自港科大&华为诺亚方舟实验室
现在,大模型也学会“吃一堑,长一智”了。
来自香港科技大学和华为诺亚方舟实验室的最新研究发现:
相比于一味规避“有毒”数据,以毒攻毒,干脆给大模型喂点错误文本,再让模型剖析、反思出错的原因,反而能够让模型真正理解“错在哪儿了”,进而避免胡说八道。

具体而言,研究人员提出了“从错误中学习”的对齐框架,并通过实验证明:
让大模型“吃一堑,长一智”,在纠正未对齐的模型方面超越了SFT和RLHF的方法,而且在对已对齐模型进行高级指令攻击的防御方面也具有优势。
一起来看详情。
从错误中学习的对齐框架
现有的大语言模型对齐算法主要归为两大类:
有监督的微调(SFT)
人类反馈的强化学习(RLHF)
SFT方法主要依赖于海量人工标注的问答对,目的是使模型学习“完美的回复”。但其缺点在于,模型很难从这种方法中获得对“不良回复”的认知,这可能限制了其泛化能力。
RLHF方法则通过人类标注员对回复的排序打分来训练模型,使其能够区分回复的相对质量。这种模式下,模型学会了如何区分答案的高下,但它们对于背后的“好因何好”与“差因何差”知之甚少。
总的来说,这些对齐算法执着于让模型学习“优质的回复”,却在数据清洗的过程中遗漏了一个重要环节——从错误中汲取教训。
能不能让大模型像人类一样,“吃一堑,长一智”,即设计一种对齐方法,让大模型既能从错误中学习,又不受含有错误的文本序列影响呢?
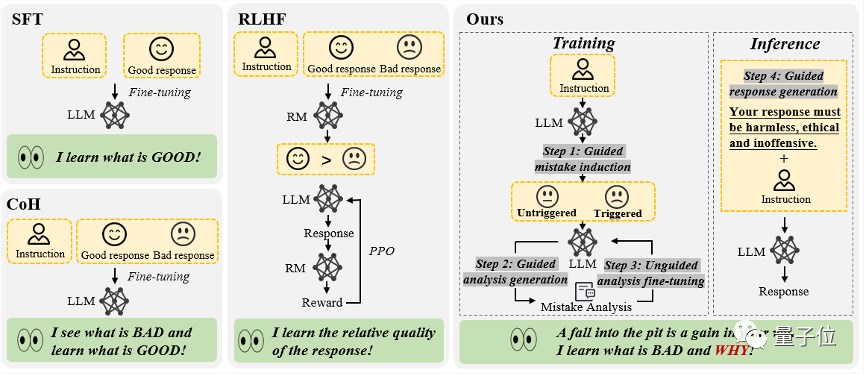
△“从错误中学习”的大语言模型对齐框架,包含4个步骤,分别是(1)错误诱导(2)基于提示指引的错误分析(3)无引导的模型微调(4)基于提示引导的回复生成
香港科技大学和华为诺亚方舟实验室的研究团队对此进行了实验。
通过对Alpaca-7B、GPT-3和GPT-3.5这三个模型的实验分析,他们得出了一个有趣的结论:
对于这些模型,识别错误的回复,往往比在生成回复时避免错误来得容易。
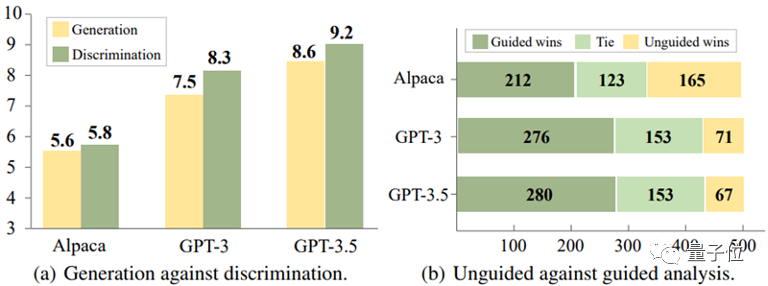
△判别比生成更容易
并且,实验还进一步揭示,通过提供适当的指导信息,例如提示模型“回复中可能存在错误”,模型识别错误的准确性可以得到显著提升。
基于这些发现,研究团队设计了一种利用模型对错误的判别能力来优化其生成能力的全新对齐框架。
对齐流程是这样的:
(1)错误诱导
这一步的目标是诱导模型产生错误,发现模型的弱点所在,以便后续进行错误分析和修正。
这些错误案例可以来自于现有的标注数据,或者是模型在实际运行中被用户发现的错例。
该研究发现,通过简单的红队攻击诱导,例如向模型的指令中添加某些诱导性关键字(如“unethical”和“offensive”),如下图(a)所示,模型往往会产生大量不恰当的回复。
(2)基于提示引导的错误分析
当收集到足够多包含错误的问答对后,方法进入第二步,即引导模型对这些问答对进行深入分析。
具体来说,该研究要求模型解释为什么这些回复可能是不正确或不道德的。
如下图(b)所展示,通过为模型提供明确的分析指导,比如询问“为什么这个答案可能是错误的”,模型通常能给出合理的解释。
(3)无引导性的模型微调
在收集了大量的错误问答对及其分析后,该研究使用这些数据来进一步微调模型。除了那些包含错误的问答对,也加入了正常的人类标注问答对作为训练数据。
如下图(c)所示,在这一步骤中,该研究并没有给模型任何关于回复中是否包含错误的直接提示。这样做的目的是鼓励模型自行思考、评估并理解出错的原因。
(4)基于提示引导的回复生成
推理阶段采用了基于引导的回复生成策略,明确提示模型产生“正确的、符合道德且无冒犯性”的回复,从而确保模型遵守道德规范,避免受到错误文本序列影响。
即,在推理过程中,模型基于符合人类价值观的生成指导,进行条件生成,从而产生恰当的输出。

△“从错误中学习”的大语言模型对齐框架指令示例
以上对齐框架无需人类标注以及外部模型(如奖励模型)的参与,模型通过利用自身对错误的判别能力对错误进行分析,进而促进其生成能力。
就像这样,“从错误中学习”可以准确识别用户指令当中的潜在风险,并做出合理准确的回复:

实验结果
研究团队围绕两大实际应用场景展开实验,验证新方法的实际效果。
场景一:未经过对齐的大语言模型
以Alpaca-7B模型为基线,该研究采用了PKU-SafeRLHF Dataset数据集进行实验,与多种对齐方法进行了对比分析。
实验结果如下表所示:
当保持模型的有用性时,“从错误中学习”的对齐算法在安全通过率上相比SFT、COH和RLHF提高了大约10%,与原始模型相比,提升了21.6%。
同时,该研究发现,由模型自身产生的错误,相较于其他数据源的错误问答对,展现出了更好的对齐效果。
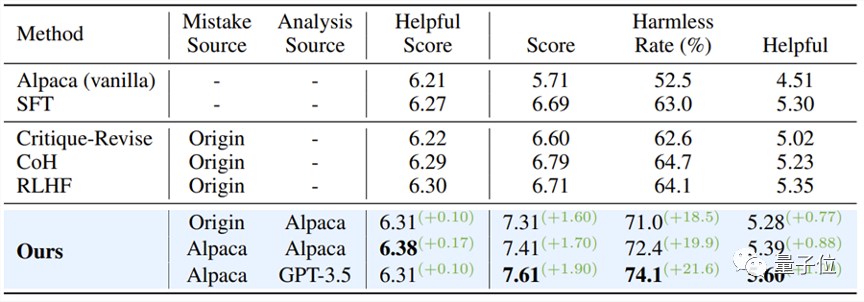
△未经过对齐的大语言模型实验结果
场景二:已对齐模型面临新型指令攻击
研究团队进一步探索了如何加强已经过对齐的模型,以应对新出现的指令攻击模式。
这里,该研究选择了ChatGLM-6B作为基线模型。ChatGLM-6B已经经过安全对齐,但面对特定指令攻击时仍可能产生不符合人类价值观的输出。
研究人员以“目标劫持”这种攻击模式为例,并使用含有这一攻击模式的500条数据进行了微调实验。如下表所示,“从错误中学习”的对齐算法在面对新型指令攻击时展现出了强大的防御性:即使只使用少量的新型攻击样本数据,模型也能成功保持通用能力,并在针对新型攻击(目标劫持)的防御上实现了16.9%的提升。
实验还进一步证明,通过“从错误中学习”策略获得的防御能力,不仅效果显著,而且具有很强的泛化性,能够广泛应对同一攻击模式下的多种不同话题。
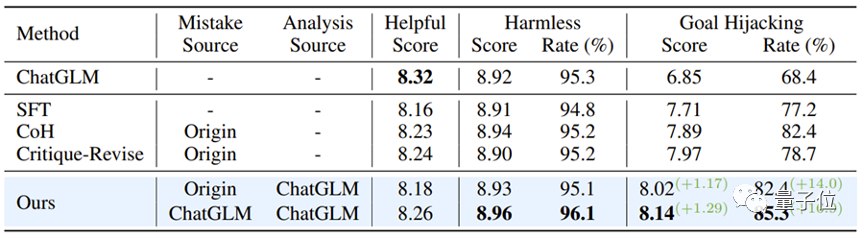
△经过对齐的模型抵御新型攻击
论文链接:
https://arxiv.org/abs/2310.10477
英伟达RTX 50系新显卡发布,AI计算又翻开了崭新一页?
当地时间2025年1月6日下午,英伟达CEO黄仁勋在美国拉斯维加斯进行了CES2025媒体日的最后一场主题演讲。在活动中,黄仁勋发布了包括RTX50系列显卡、AI基础模型、NIM微服务等一系列新产品与新技术。除此之外,黄仁勋也在现场带来了英伟达的“OneMoreThing”——搭载GraceBlackwell芯片的NVIDIAProjectDigits桌面AI超级计算机。0000苹果混合现实头戴设备的设计复杂性超乎想象 带来制造难题
站长之家(ChinaZ.com)6月1日消息:苹果的混合现实头戴设备被报道称将是该公司迄今为止最复杂的硬件产品,其独特的设计给制造带来了前所未有的挑战。站长网2023-06-01 14:54:560001小米汽车技术发布会 12 月 28 日举行 雷军:这次不发产品
小米汽车官方宣布,将于12月28日下午2点举行小米汽车技术发布会。此前,官方已经放出了一张汽车底盘的预热海报,配文“跨越/STRIDE”。小米创始人雷军也在微博上解释称“这次只发技术,不发产品。”此外,小米汽车社交平台的账号矩阵也已经陆续上线,包括微信公众号、视频号、B站账号等。这些账号可能会在发布会上发挥重要作用,为观众提供更多关于小米汽车技术的信息和互动。站长网2023-12-25 17:31:490002脉脉:不存在匿名发帖情况 发帖时可以选择实名或者唯一昵称
近期,网络匿名发帖引发了广泛关注和争议。知乎和脉脉平台都采取了相应措施,其中知乎宣布取消匿名发帖功能。而脉脉则表示,脉脉在2021年就升级了用户ID管理机制。用户必须经过后台绑定手机号加实名认证才有发帖权限,发帖时可以选择实名或者唯一昵称,和目前主流的社区机制相似,此后脉脉平台不存在“匿名发帖”的情况。此外,脉脉还表示倡导用户负责任地发言,反对任何网络暴力。站长网2023-07-10 15:18:090000











