图领域首个通用框架来了!入选ICLR'24 Spotlight,任意数据集、分类问题都可搞定|来自华盛顿大学&北大&京东
能不能有一种通用的图模型——
它既能够根据分子结构预测毒性,又能够给出社交网络的朋友推荐?
或者既能预测不同作者的论文引用,还可以发现基因网络中的人类衰老机制?
你还真别说,被ICLR2024接收为Spotlight的“One for All(OFA)”框架就实现了这个“精髓”。
它由圣路易斯华盛顿大学陈一昕教授团队、北京大学张牧涵以及京东研究院陶大程等研究者们联合提出。
作为图领域首个通用框架,OFA实现了训练单一GNN模型即可解决图领域内任意数据集、任意任务类型、任意场景的分类任务。

具体如何实现,以下为作者投稿。
图领域通用模型设计面临三大难
设计一个通用的基础模型来解决多种任务是人工智能领域的一个长期目标。近年来,基础大语言模型(LLMs)在处理自然语言任务方面表现出色。
然而,在图领域,虽然图神经网络(GNNs)在不同的图数据中都有着不俗的表现,但如何设计与训练一个能同时处理多种图任务的基础图模型依然前路茫茫。
与自然语言领域相比,图领域的通用模型设计面临着许多独有的困难。
首先,区别于自然语言,不同的图数据有着截然不同的属性与分布。
比如分子图描述了多个原子如何通过不同的作用力关系形成不同的化学物质。而引用关系图则描述了文章与文章之间相互引用的关系网。
这些不同的图数据很难被统一在一个训练框架下。
其次,不同于LLMs中所有任务都可以被转化成统一的下文生成任务,图任务包含了多种子任务,比如节点任务,链路任务,全图任务等。
不同的子任务通常需要不同的任务表示形式与不同的图模型。
最后,大语言模型的成功离不开通过提示范式而实现的上下文学习(in-context learning)。
在大语言模型中,提示范式通常为对于下游任务的可读文字描述。
但是对于非结构化且难以用语言描述的图数据,如何设计有效的图提示范式来实现in-context learning依然是个未解之谜。
用“文本图”概念等来解决
下图给出了OFA的整体框架:
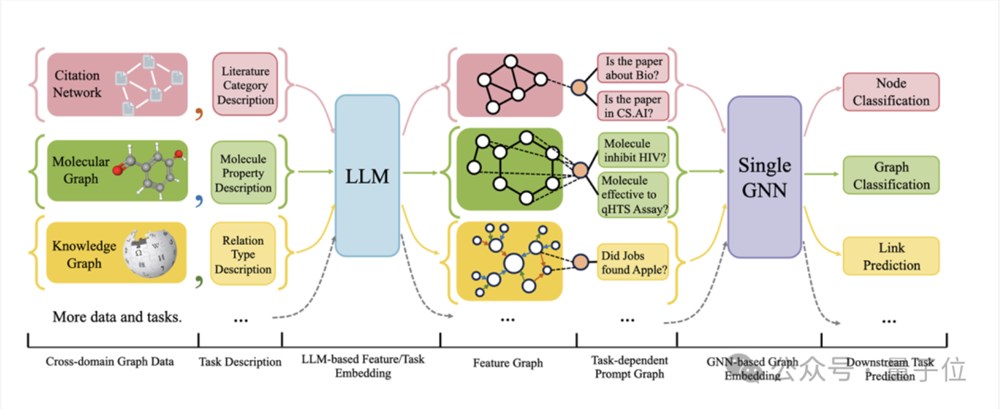
具体而言,OFA的团队通过巧妙的设计来解决上述所提到的三个主要问题。
对于不同图数据属性与分布不同的问题,OFA通过提出文本图(Text-Attributed Graph, TAGs)的概念来统一所有图数据。利用文本图,OFA将所有的图数据中的节点信息与边信息用统一的自然语言框架来描述,具体如下图所示:


接着,OFA通过单一LLM模型对所有数据中的文本进行表示学习得到其嵌入向量。
这些嵌入向量将作为图模型的输入特征。这样,来自不同领域的图数据将被映射到相同的特征空间,使得训练一个统一的GNN模型可行。
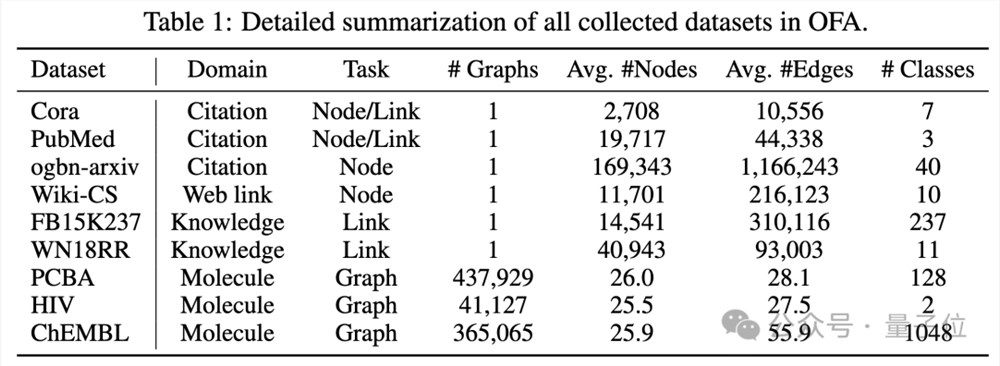
OFA收集了9个来自不同领域,不同规模的图数据集,包括引用关系图,Web链接图,知识图谱,分子图, 如下图所示:
此外,OFA提出Nodes-of-Interest(NOI)子图与NOI提示节点(NOI Prompt Node)来统一图领域内不同的子任务类型。这里NOI代表参与到相应任务的一组目标节点。
比如,在节点预测任务中,NOI是指需要预测的单个节点;而在链路任务中,NOI包括需要预测链路的两个节点。NOI子图是指围绕着这些NOI节点扩展出的一个包含h-hop邻域的子图。
然后,NOI提示节点为一个新引入的节点类型,直接连接到所有的NOI上。
重要的是,每个NOI提示节点包含了当前任务的描述信息,这些信息以自然语言的形式存在,并和文本图被同一个LLM所表示。
由于NOI中节点所包含的信息在经过GNNs的消息传递后将被NOI提示节点所收集,GNN模型仅需通过NOI提示节点来进行预测。
这样,所有不同的任务类型将拥有统一的任务表示。具体实例如下图所示:
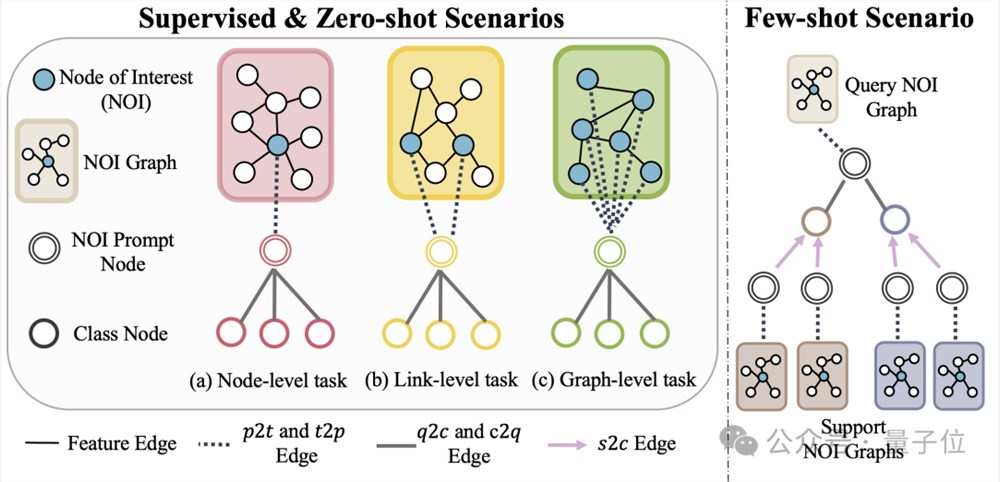
最后,为了实现图领域的in-context learning,OFA引入统一的提示子图。
在一个有监督的k-way分类任务场景下,这个提示子图包含了两类节点:一类是上文提到的NOI提示节点,另一类是代表k个不同类别的类别节点(Class Node)。
每个类别节点的文本将描述此类别的相关信息。
NOI提示节点将会单向连接到所有类别节点上。通过这个方式构建好的图将被输入进图神经网路模型进行消息传递与学习。
最终,OFA将对每个类别节点分别进行二分类任务,并取概率最高的类别节点作为最终的预测结果。
由于类别信息存在于提示子图中,即使遇到全新的分类问题,OFA通过构建相应的提示子图即可直接进行预测而无需任何微调,从而实现了零样本学习。
对于少样本学习场景,一个分类任务将包含一个query输入图和多个support输入图,OFA的提示图范式会将每个support输入图的NOI提示节点与其所对应的类别节点相连,同时将query输入图的NOI提示节点与所有类别节点相连。
后续的预测步骤与上文所述一致。这样每个类别节点将会额外得到support输入图的信息,从而在统一的范式下实现少样本学习。
OFA的主要贡献总结如下:
统一的图数据分布:通过提出文本图并用LLM转化文本信息,OFA实现了图数据的分布对齐与统一。
统一的图任务形式:通过NOI子图与NOI提示节点,OFA实现了多种图领域子任务的统一表示。
统一的图提示范式:通过提出新颖的图提示范式,OFA实现了图领域内的多场景in-context learning。
超强泛化能力
文章在所收集的9个数据集上对OFA框架进行了测试,这些测试覆盖了在有监督学习场景下的十种不同任务,包括节点预测、链路预测和图分类。
实验的目的是验证单一的OFA模型处理多任务的能力,其中作者对比使用不同LLM(OFA-{LLM})和每个任务训练单独模型(OFA-ind-{LLM})的效果。
比较结果如下表所示:
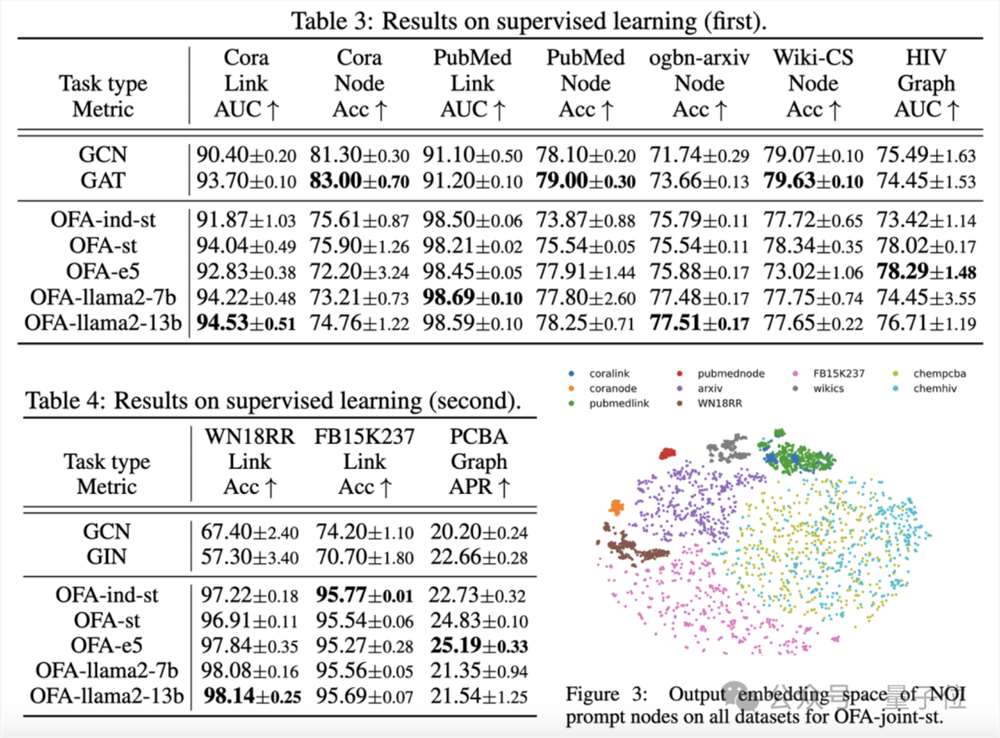
可以看到,基于OFA强大的泛化能力,一个单独的图模型(OFA-st,OFA-e5,OFA-llama2-7b,OFA-llama2-13b)即能够在所有的任务上都具有与传统的单独训练模型(GCN, GAT, OFA-ind-st)相近或更好的表现。
同时,使用更强大的LLM可以带来一定的性能提升。文章进一步绘制了训练完成的OFA模型对于不同任务的NOI提示节点的表示。
可以看到不同的任务被模型嵌入到不同的子空间,从而使得OFA可以对于不同的任务进行分别的学习而不会相互影响。
在少样本以及零样本的场景下,OFA在ogbn-arxiv(引用关系图),FB15K237(知识图谱)以及Chemble(分子图)上使用单一模型进行预训练,并测试其在不同下游任务及数据集上的表现。结果如下:
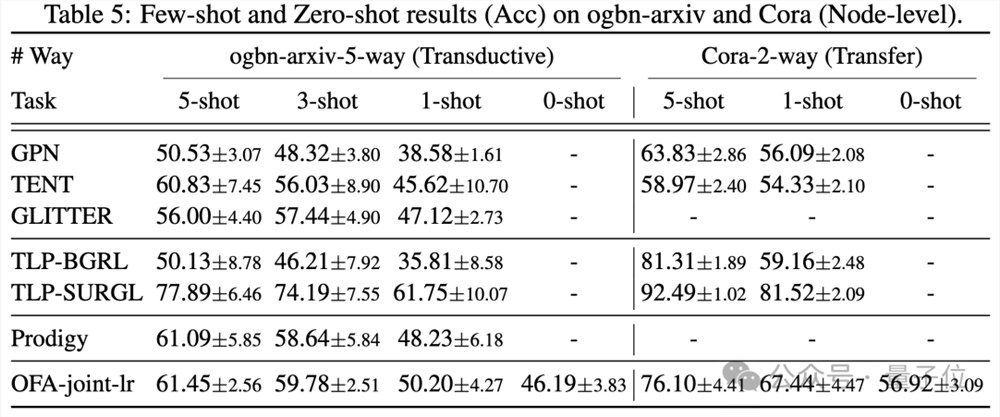
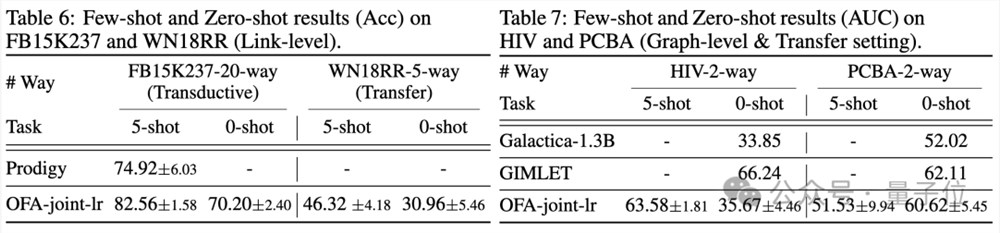
可以看到,即使在零样本场景下,OFA依旧可以取得不错的效果。综合来看,实验结果很好的验证了OFA强大的通用性能以及其作为图领域基础模型的潜力。
更多研究细节,可参考原论文。
地址:
https://arxiv.org/abs/2310.00149
https://github.com/LechengKong/OneForAll
—完—
突然宣布!小红书旗下电商平台“小绿洲”10月1日停止运营
快科技9月3日消息,日前,小红书旗下电商平台小绿洲”突然发布用户告别信”,称因业务调整,计划2023年10月1日停止运营,商品停止销售,2023年10月31日正式关闭小绿洲。官方表示,小绿洲曾深耕露营、陆冲、滑雪、骑行、徒步等运动场景,遗憾的是,在业务探索和发展过程中,没能实现最大化满足大家户外需求的预期目标,所以最终决定关停。站长网2023-09-03 16:53:180001智能的本质就是压缩?马毅团队5年心血提出「白盒」Transformer, 打开LLM黑盒!
【新智元导读】来自UC伯克利,港大等机构的研究人员,开创性地提出了一种「白盒」Transformer结构——CRATE。他们通过将数据从高维度分布压缩到低维结构分布,实现有效的表征,从而进一步实现了有竞争力的模型性能。这也引发了一个更为深远的讨论——难道智能的本质就是压缩吗?AI界大佬对于大模型的安全问题一直以来争吵不休,全都归咎于神经网络「黑盒」,让所有人捉摸不透。站长网2023-11-27 14:01:410002Redmi K70至尊版曝光 搭载联发科天玑9300处理器
RedmiK70至尊版被博主数码闲聊站曝光,据称该机将采用8TLTPO极窄直屏,搭载联发科天玑9300旗舰平台,成为Redmi明年的旗舰焊门员”。与RedmiK60至尊版相比,RedmiK70至尊版最大的升级在于屏幕技术。8TLTPO技术的引入将为用户带来更流畅、更省电的使用体验。这种技术相比LTPS屏幕,能够在保证流畅体验的同时显著降低功耗,从而保证整体性能的稳定释放。站长网2023-12-29 16:49:470001DeepSeek上脸实测:AR眼镜实时翻译老黄GTC演讲,完了还帮我划重点
DeepSeek、通义千问等大模型AR眼镜,打开GTC老黄演讲的姿势,可以是这样:翻译的字幕就在眼前,根据演讲实时更新。还能一键总结摘要:△实测为演讲部分内容,并非全文只凭一副看上去平平无奇的眼镜,就能随身带一个翻译官助手。摘下眼镜,立刻回归现实。同时也可以是一个随身携带,随时可直接唤醒的AI助手。提问一句,什么是相对论?专业回答立刻浮现眼前。站长网2025-03-23 19:35:070001那些共享单车的创始人们今何在?
10月15日,网友发文称退回了摩拜单车299元押金,时间跨度长达6年。有用户误以为是可以退ofo小黄车的押金。16日,美团客服回应表示,押金从摩拜被美团收购以后就可以开始退,用户可以提供手机号码帮助核实,核实之后可以根据流程帮助退押金。此外,客服称ofo不属于美团。事实上,早在去年8月就曾有网友发现,摩拜单车中的押金可以通过美团APP退回。站长网2023-10-19 09:09:260000