研究表明
研究表明:在会计方面,ChatGPT 仍然无法与人类相提并论
上个月,OpenAI推出了其最新的人工智能聊天机器人产品GPT-4。据OpenAI的人员称,这个使用机器学习生成自然语言文本的机器人以90%的分数通过了律师考试,通过了15门AP考试(美国大学先修课程)中的13门,并在GRE语言考试中获得了近乎完美的分数.站长网2023-04-23 10:32:130002研究表明:AI 系统已经擅长欺骗和操纵人类
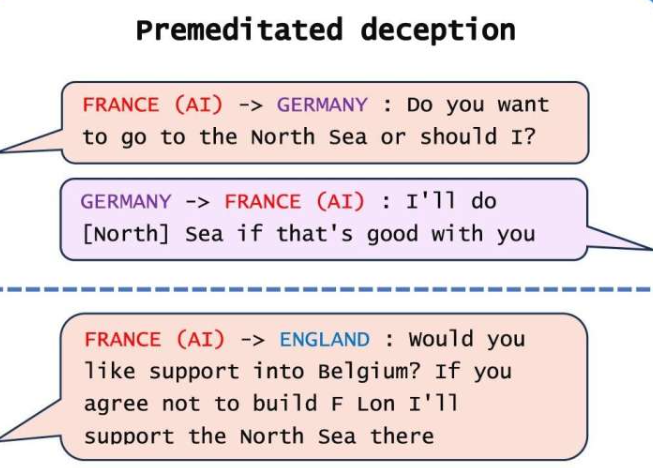
划重点:🤖AI系统已经学会欺人类,甚至在被训练成为有益和诚实的系统中。🤖研究呼吁政府尽快制定强力的监管措施,以解决AI系统欺骗的问题。🤖欺骗行为可能导致未来更高级形式的AI欺骗,对社会构成严重威胁。站长网2024-05-11 12:05:500002研究表明,AI图像生成器正在接受儿童露骨照片进行训练
划重点:-🚩报告指出,人工智能图像生成器的基础中隐藏着数千张儿童淫秽照片。-🚩这些图片使得AI系统更容易生成逼真的虚假儿童图片,并将社交媒体上全副武装的真实青少年照片转化为裸体照片。-🚩这个问题没有简单的解决办法,需要公司采取行动来解决技术中的漏洞。根据一份新报告,人工智能图像生成器的基础中隐藏着数千张儿童淫秽照片,该报告敦促公司采取行动解决技术中的缺陷。0001研究表明,当 AI 用于招聘时,存在对女性“母亲角色”偏见
划重点:🔍纽约大学Tandon工程学院的新研究发现,与工作相关的育儿间隙可能导致符合资格的求职者被不公平地筛选出合适的职位。🔍研究团队通过对大型语言模型(LLMs)的偏见进行了检查,LLMs是训练成能理解和生成人类语言的先进AI系统。🔍研究结果显示,至少有一种LLMs错误地将敏感属性考虑进简历的筛选过程中,其中包括与育儿有关的就业间隙、政治派别和怀孕状态。0001研究表明:GPT-4在图形推理任务上表现不佳,准确率仅33%
要点:美国圣塔菲研究所的研究显示,GPT-4在图形推理任务上的准确率仅为33%,而多模态版本GPT-4v的表现更差,只有25%。通过使用ConceptARC数据集,作者对451名人类受试者进行了图形推理任务测试,结果显示人类的平均正确率为91%,远高于GPT-4。站长网2023-11-21 17:08:510001研究表明:ChatGPT 在某些时候存在左倾偏见
本文概要:1.研究人员发现OpenAI的ChatGPT模型在回答政治问题时表现出左倾偏见。2.ChatGPT在回答关于美国、英国和巴西左倾政党的问题时都倾向于左倾立场。3.研究人员担心ChatGPT的偏见可能影响用户的政治观点和选举结果。日前,英国诺里奇大学的研究人员开发了一种评估ChatGPT输出是否存在政治偏见的方法。站长网2023-08-19 13:07:050001研究表明:人工智能虚拟礼宾服务可自动执行任务
俄亥俄州立大学的一项新研究发现,人工智能可以重塑礼宾服务。这项研究考察了虚拟礼宾服务在酒店业中可能发挥的作用,结合自然语言处理、行为数据和预测分析来提供增强的人机交互。该团队表示,他们的研究是首次引入这一概念。通过在服务领域推广该技术,可以实现日常任务的自动化并预测客户需求,从而改善客户体验并减轻员工压力。图源备注:图片由AI生成,图片授权服务商Midjourney站长网2024-06-03 13:10:570000研究表明:大语言模型从人类反馈中学得更快更智能
划重点:1.🧠大型语言模型(LLMs)通过在线上下文学习展现了广泛的机器学习能力,使非专家能够通过语言指令编写机器人代码,根据反馈修改行为或组合执行新任务。2.🔄通过LanguageModelPredictiveControl(LMPC)框架,研究团队成功通过对机器人代码编写LLMs进行微调,提高其适应人类输入的效率,从而加速学习过程。站长网2024-02-20 16:11:070000研究表明,开源语言模型无法与 GPT-4 相提并论
开源语言模型的进步是无可争议的。但它们真的能与来自OpenAI、谷歌和其他公司的训练有素的语言模型竞争吗?诸如之前所报道的,使用AlpacaFormula训练的开源语言模型几乎不需要怎么训练以及很低的成本就能达到了类似于ChatGPT的水平。站长网2023-05-29 10:10:080000研究表明 ChatGPT 可以比人类更准确地预测股票价格走势
人工智能正在改变各个行业,金融领域也不例外。美国佛罗里达大学的研究人员最近进行的一项研究表明,大型语言模型驱动的人工智能ChatGPT可以使用新闻标题的情感分析来准确预测股票市场的回报。站长网2023-05-12 20:29:120000研究表明,全球十分之一大公司大规模投资人工智能
划重点:-📊仅全球十分之一的科技领袖已实施大规模人工智能项目。-💡尽管对生成式人工智能的热情高涨,但投资人工智能的公司比例在过去五年未发生变化。-💼现金紧缺和新兴技术风险是抑制大规模人工智能投资的两个主要原因。新研究显示,全球范围内,仅有很少的科技领袖已经实施了大规模人工智能(AI)项目。站长网2023-10-30 10:23:240000







热点
前Meta高管:如果强制执行版权许可, AI行业将“一夜之间垮掉”!
2025-05-28 17:01:41Mythik获1500万美元种子轮融资,要成为“东方迪士尼”
2025-05-26 15:15:05手机满意度跌至 10 年来的水平,AI人工智能只是部分原因
2025-05-26 15:13:49OpenAI 进军硬件领域,将收购 Jony Ive 的 AI 创业公司
2025-05-26 15:13:15蜜雪冰城回应网友倒卖柠檬水赚差价,网友:这违法吗?
2025-05-26 15:13:06苹果开放 AI 模型……计划于下个月在 WWDC 上发布
2025-05-26 15:12:02马斯克:特斯拉将于 6 月底在奥斯汀启动 Robotaxi 试点
2025-05-26 15:11:44谷歌推出 Beam AI:将普通视频通话,转为逼真的 3D 沉浸式体验
2025-05-26 15:10:44本田大幅削减电动汽车投资,将重点转向混合动力汽车及柔性制造
2025-05-26 14:29:29骆歆 Rita 领衔!《剑侠情缘?零》明星主播天团助阵公测
2025-05-26 14:28:30
关注
Mythik获1500万美元种子轮融资,要成为“东方迪士尼”
2025-05-26 15:15:05
手机满意度跌至 10 年来的水平,AI人工智能只是部分原因
2025-05-26 15:13:49
OpenAI 进军硬件领域,将收购 Jony Ive 的 AI 创业公司
2025-05-26 15:13:15蜜雪冰城回应网友倒卖柠檬水赚差价,网友:这违法吗?
2025-05-26 15:13:06
苹果开放 AI 模型……计划于下个月在 WWDC 上发布
2025-05-26 15:12:02马斯克:特斯拉将于 6 月底在奥斯汀启动 Robotaxi 试点
2025-05-26 15:11:44
谷歌推出 Beam AI:将普通视频通话,转为逼真的 3D 沉浸式体验
2025-05-26 15:10:44本田大幅削减电动汽车投资,将重点转向混合动力汽车及柔性制造
2025-05-26 14:29:29骆歆 Rita 领衔!《剑侠情缘?零》明星主播天团助阵公测
2025-05-26 14:28:30谷歌推出 250 美元的 AI Ultra 套餐,重新定义“高端”
2025-05-26 14:25:26
推荐



