研究表明:GPT-4在图形推理任务上表现不佳,准确率仅33%
站长网2023-11-21 17:08:511阅
要点:
美国圣塔菲研究所的研究显示,GPT-4在图形推理任务上的准确率仅为33%,而多模态版本GPT-4v的表现更差,只有25%。
通过使用ConceptARC数据集,作者对451名人类受试者进行了图形推理任务测试,结果显示人类的平均正确率为91%,远高于GPT-4。
研究者招募受试者的方式和GPT-4的输入方式引发了质疑,包括入门测试不足以筛选高质量受试者,样本的随机性受到争议,以及图像转换为数字矩阵可能改变概念等。
最近的研究表明,GPT-4在图形推理任务上表现不佳,仅有33%的准确率,引发了对大型语言模型图形处理能力的关注。
通过使用ConceptARC数据集,研究者对451名人类受试者进行了图形推理任务测试,结果显示人类在这方面表现卓越,平均准确率达到91%。
论文地址:https://arxiv.org/pdf/2305.07141.pdf
多模态版本GPT-4v的表现更差,只有25%的准确率。这凸显了在涉及图形处理的任务中,大型语言模型的多模态能力也受到限制。
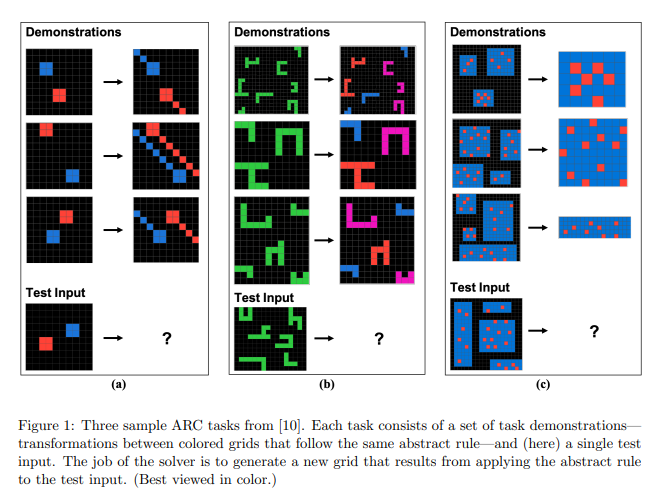
研究者使用ConceptARC数据集进行测试,其中包括16个子类的图形推理题,涵盖了位置关系、形状、操作、比较等多个方面的内容。
然而,这项研究的方法引发了一些质疑,包括受试者招募的方式和GPT-4的输入方式。研究者在亚马逊众包平台上招募受试者,入门测试被认为不足以筛选高质量的受试者,样本的随机性受到争议。
此外,GPT-4的输入方式也引发了一些争议,特别是将图像转换为数字矩阵可能改变概念,这使得一些人对实验结果的可信度产生疑问。综合而言,这项研究突显了目前大型语言模型在某些特定任务上的局限性,并提出了对研究方法的进一步审视的需求。
0001
评论列表
共(0)条相关推荐
UP主的混剪,居然能改成一部古偶黑马?
“我有预感,未来几年短剧一定会胜过长剧。最近追的《古相思曲》,昨天才播出的《风月变》都挺好看的。”昨天,编剧于正发了篇微博,意料之外地夸了夸两部小成本的古装剧。“故事、人设、结构都异于现在所谓的大剧,不仅耳目一新,也让人看到了未来的希望。”正好前一天,《古相思曲》刚刚收官,这部B站自制的古装剧,不少用户称它是“这个夏天最大的惊喜”,豆瓣评分8.4,到了大结局,剧集评分涨到了8.6分。站长网2023-07-18 19:42:430000抖音治理面向老年人流量收割违规行为 打击冒充名人、土味儿情话诱导等问题
抖音宣布,将持续开展老年人保护相关的内容治理专项,对各类面向老年人进行“流量收割”的违规现象进行升级治理,重点打击冒充名人、土味儿情话诱导、利用老年人卖惨博流量、领收益骗互动的四大违规行为。部分代表性案例如下:一、冒充名人0000淘宝网页版直播功能全面优化 APP直播间均已上线
淘宝网页版近日迎来了一场重要的升级——直播功能的全面优化。在网页版淘宝中,原先APP上的所有直播间均已上线,直播间列表整齐排列,方便用户快速浏览和选择。直播间内的布局也经过精心设计,直播画面、宝贝口袋和聊天互动三个区域并行排列,充分利用了PC端的大屏优势。相较于手机端,用户在网页版上可以更加清晰地看到商品细节,更轻松地发表评论,同时也不会错过任何直播内容。站长网2024-05-22 20:33:070000外国博主2.0时代:竞争加剧倒逼内容升级
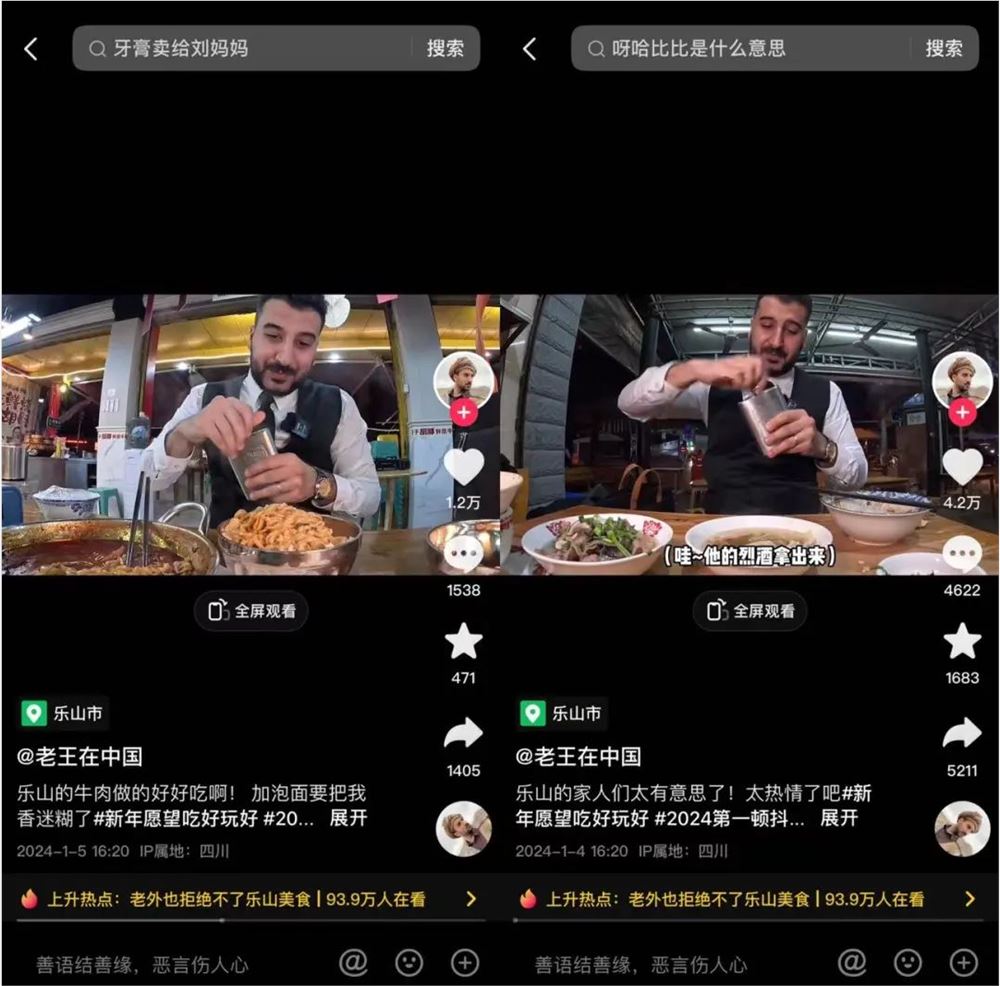
“呀,哈比比,我是你们的好朋友老王~”,这是@老王在中国每期视频固定的开场白。老王是一位美食探店博主,他喜欢探索一些隐藏在小众城市中的美食店铺,会为了一个餐厅奔赴一座城市,寻找那些角落之中的美好。站长网2024-01-17 18:16:320000让虚拟角色动作更真实!科研团队利用机器学习技术提升运动模拟技术
本文概要:1.研究团队利用机器学习系统从广播视频中学习网球技能,实现了真实的动作模拟。2.他们使用物理模拟和动作规划策略来指导角色的运动,并能够生成稳定的控制器。3.这项技术有望扩展到其他运动领域,并为机器人学习提供方法。站长网2023-08-07 15:51:490000