研究表明,开源语言模型无法与 GPT-4 相提并论
站长网2023-05-29 10:10:080阅
开源语言模型的进步是无可争议的。但它们真的能与来自 OpenAI、谷歌和其他公司的训练有素的语言模型竞争吗?
诸如之前所报道的,使用Alpaca Formula训练的开源语言模型几乎不需要怎么训练以及很低的成本就能达到了类似于ChatGPT的水平。

Alpaca Formula指的是开发人员使用 ChatGPT 生成的训练数据来微调Meta语言模型 LLaMA 。使用这些数据,LLaMA 模型可以在很短的时间内学习生成类似于 ChatGPT 的输出,并且只需要很少的计算量。
但伯克利大学的研究人员在最近的一项研究中得出了不同的结论:他们将Alpaca Formula应用于LLaMA和 GPT-2的一些基础模型,然后让这些结果由人工评估并由GPT-4自动评估。
最初,他们得出了与之前的开发人员相同的结论:使用指令改进的模型(研究人员称之为“模仿模型”)的性能远远超过基础模型,与 ChatGPT 相当。
然而,“更有针对性的自动评估”表明,模仿模型实际上只在他们看到模仿数据的任务中表现良好。在所有其他领域,GPT-4仍然存在明显的性能差距。因为这些基础模型在广泛的预训练过程中获得了大部分功能,而不是在微调过程中获取的。
研究人员表示,这些所谓的评价的工作者经常在没有专业知识的情况下在短时间内评估人工智能内容,很容易被忽悠。
OpenAI 研究员约翰舒尔曼最近也批评使用 ChatGPT数据微调开源基础语言模型,称如果微调数据集包含原始模型中不存在的知识,它们可能会产生更多不正确的内容。
0000
评论列表
共(0)条相关推荐
ChatGPT访问量增速大降 6月环比增长率可能为负数
在全球掀起AI热潮下,ChatGPT无疑是最受瞩目的。该产品在发行两个月后(2023年1月末),便获得1亿月活用户。不过,从最新数据来看,ChatGPT发展增速也进入了瓶颈期。站长网2023-06-28 15:35:230001生成式 AI 将使微软、谷歌和亚马逊的市值超过苹果公司的 3 万亿美元
Needham&Company分析师在向客户发布的报告中强调了生成式人工智能在重塑大型全球公司竞争格局方面的变革潜力。他们写道:「我们认为,包括苹果公司在内的许多公司即将被生成式人工智能所超越。」分析师指出,将生成式人工智能融入业务实践中的公司可以获得更快的产品和内容推出速度,从而提高收入并降低20-30%的成本。站长网2023-09-08 08:59:190000一花“坠落”,万国货“生”
“整个国货圈乱成了一锅粥。”花西子可能也没有想到,李佳琦的直播失言,在连累自己成为“输家”的同时,也几乎以一己之力搅动了整个老牌国货圈。李佳琦落泪道歉后,处于风暴中心的花西子陷入众嘲,高“克”单价的新锐品牌未见发声,与之相对,以蜂花为代表的国货老品牌却敏锐蹭上热点,靠着玩梗与发疯文学,接下了花西子“跌倒”造就的泼天富贵。站长网2023-09-20 09:12:280000BioMap百图生科 AIGP 蛋白设计平台开启内测
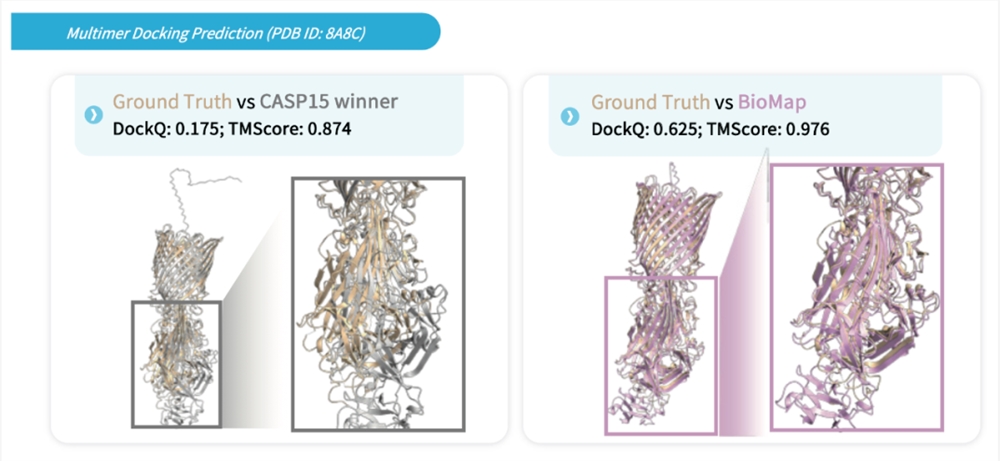
百图生科的AIGP蛋白设计平台发布了首批内测用户招募信息,限量50家,内测注册成功用户将获得免费的算力币,并可以邀请好友试用并获得更多算力币。该平台是基于百图生科的生命科学FoundationModel-xTrimo推出的生成式蛋白设计平台,可以支持多种类蛋白质的生成和优化。AIGP蛋白设计平台无需本地部署,可在线即点即用,用户的数据也会受到严格的加密和保护。站长网2023-09-11 14:04:360001“口渴”的AI!ChatGPT的耗水量惊人,需要大量水来冷却数据中心
我们知道,训练人工智能算法需要消耗大量的能量,最近一篇新论文所揭示,它也会消耗大量的水。科罗拉多大学河滨分校和德克萨斯大学阿灵顿分校的研究人员分享了一篇名为“让AI不那么渴”("MakingAILessThirsty")的尚未经过同行评审的论文,该论文研究了AI训练对环境的影响,这不仅需要大量电力还有大量的水来冷却数据中心。站长网2023-04-13 10:30:140001