YaRN:可高效扩展现有大模型的上下文窗口长度
要点:
1、YaRN是一种计算高效的方法,可以扩展基于 transformer 的语言模型的上下文窗口,与以前的方法相比,它需要10倍更少的 token 和2.5倍更少的训练步骤。
2、YaRN利用了旋转位置嵌入(RoPE)来增强模型处理顺序数据和获取位置信息的能力,同时通过压缩变压器来扩展上下文窗口。
3、实验表明,YaRN只需要400个训练步骤就能成功实现语言模型的上下文窗口扩展,相比之前的方法降低了10倍的训练样本量和2.5倍的训练步骤。
大型语言模型在自然语言处理任务上的强大表现主要归功于模型所能捕捉的上下文信息。
Rotary position embedding(RoPE)增强了模型处理顺序数据和捕获序列中位置信息的能力。然而,这些模型必须超越它们所训练的序列长度进行泛化。
Nous Research、Eleuther AI和日内瓦大学的研究人员提出了YaRN (又一个RoPE扩展方法),该方法可以高效地扩展现有语言模型的上下文窗口长度。
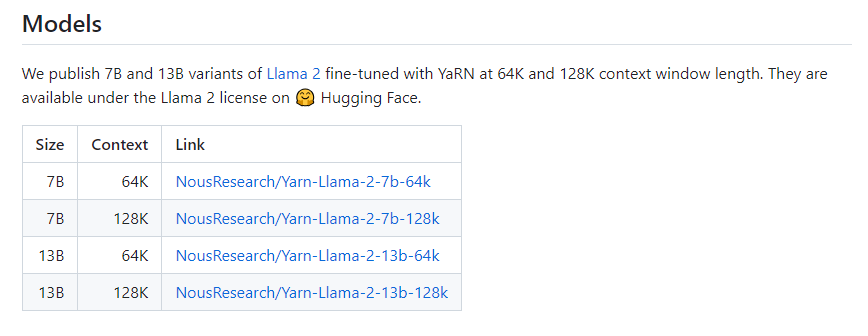
项目地址:https://github.com/jquesnelle/yarn
RoPE使用复杂数旋转,这是一种有效的编码位置信息的旋转式位置嵌入,使模型能够在不依赖固定的定位嵌入的情况下有效地编码位置信息。这将帮助模型更准确地捕捉长期依赖关系。控制旋转参数是在模型的训练过程中学习的。模型可以自适应地调整旋转以最好地捕捉标记之间的位置关系。
他们采用的方法是压缩变换器,它使用外部记忆机制来扩展上下文窗口。它们从外部存储库中存储和检索信息,使其能够访问超出其标准窗口大小的范围。已经开发了将记忆组件添加到转换器架构的扩展,使模型能够保留和利用来自过去标记或示例的信息。
他们的实验表明,YaRN成功地实现了具有仅400个训练步骤的LLMs的上下文窗口扩展,这是原始预训练语料库的0.1%,比25减少了10倍,比7减少了2.5倍的训练步骤。这使得它在没有任何额外推理成本的情况下高度计算高效。
总的来说,YaRN改进了所有现有的RoPE插值方法,并以无缺点和最小的实施努力替换PI。微调的模型在多个基准上保持了其原有的能力,同时能够关注非常大的上下文范围。未来的研究工作可以涉及内存增强,这可以与传统的自然语言处理模型结合使用。基于变换器的模型可以结合外部记忆库来存储与上下文相关的信息,用于下游任务如问答或机器翻译。
Sam Altman 警告人工智能的潜在威胁 但仍然希望全世界都能使用它
站长之家(ChinaZ.com)11月1日消息:OpenAI的CEOSamAltman最近对公众表示,他的公司背后的技术可能会威胁到人类文明的未来。今年5月,Altman在华盛顿特区的一个参议院小组委员会听证会上紧急呼吁立法者:制定周密的法规,以拥抱人工智能的强大前景,同时减轻其对人类的潜在威胁。这是他和AI未来的决定性时刻。站长网2023-11-01 09:42:280000谷歌AI研究提出新的视频注释方法VidLNs 精准定位视频描述
1.VidLNs是一种视频注释方法,通过口述和光标移动来获取语义正确且密集定位准确的视频描述。2.VidLNs使用关键帧来创建每个角色的独立叙述,实现复杂情节的细致描绘。3.VidLNs的数据集可用于视频故事定位和视频问答等任务。站长网2023-08-09 15:00:200000马斯克称推特正在测试一个名为文章的新功能
theverge报道称,埃隆·马斯克透露,推特正在开发一项功能,让你可以在平台上发布文章。马斯克在回复一位用户关于这个正在开发中的工具的推文时说,这个功能将“允许用户发布非常长、复杂的文章,包含混合媒体”。他说,“你想的话,可以发布一本书。”站长网2023-07-19 19:18:290000英国学生使用人工智能制作不当儿童图像引发警示
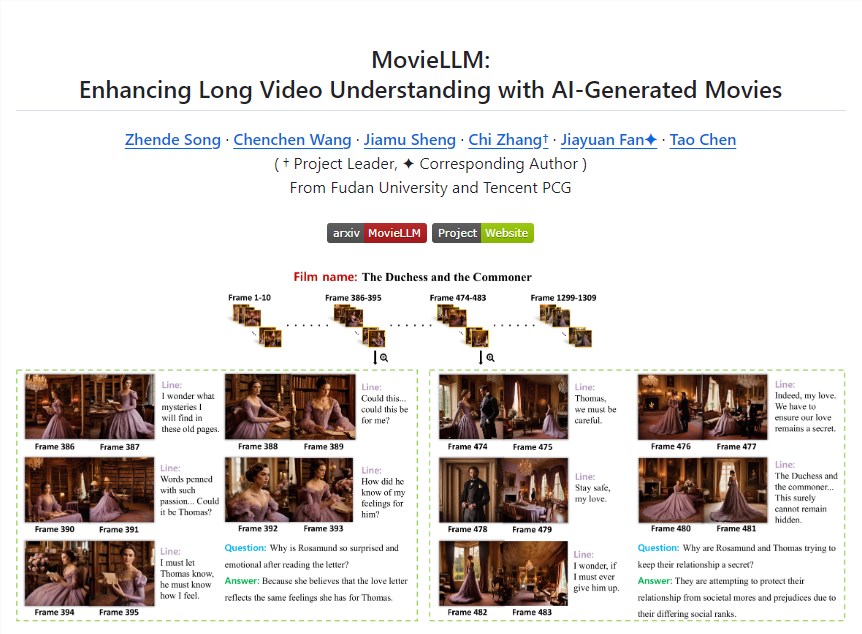
**划重点:**1.🤖学生使用人工智能制作涉嫌儿童性虐待图像。2.😨图像逼真程度令人震惊,有专家呼吁采取紧急行动。3.🚫专业机构建议学校紧急采取措施阻止儿童性虐待材料的传播。近日,英国一组关注儿童虐待和技术的专家警告称,英国学生正在利用人工智能(AI)制作不当儿童图像。站长网2023-11-27 15:04:540000MovieLLM: 一个词或一句话就能合成电影级视频
近日,复旦大学和腾讯PCG的研究人员共同开发了一个名为MovieLLM的新颖框架,该框架能够从简单的文本提示中生成高质量、电影级别的视频数据。令人惊讶的是,MovieLLM甚至能仅通过一个词或一个句子就能创作出一部完整的电影。项目地址:https://top.aibase.com/tool/moviellm站长网2024-03-07 16:44:210000