谷歌AI研究提出新的视频注释方法VidLNs 精准定位视频描述
1. VidLNs 是一种视频注释方法,通过口述和光标移动来获取语义正确且密集定位准确的视频描述。
2. VidLNs 使用关键帧来创建每个角色的独立叙述,实现复杂情节的细致描绘。
3. VidLNs 的数据集可用于视频故事定位和视频问答等任务。
谷歌人工智能研究提出了一种名为 VidLNs 的视频注释方法,旨在为视频提供丰富的描述和准确的时空定位。它可以让我们更好地理解视频内容,并为机器学习算法提供更多信息,帮助它们理解和处理视频。
与之前的图像注释方法不同,VidLN 的工作原理是这样的:注释者会观察视频并识别出其中的主要角色和关键时刻。他们会口头描述这些角色参与的事件,并用光标移动到视频中相关的位置。这种口头描述包括角色的名字、属性以及他们的行动和与其他角色或物体的互动。通过使用光标移动和语音描述,我们可以为视频中的每个单词提供具体的视觉依据。
VidLN 的好处是,它能够提供更全面和准确的视频描述。通过关键时刻和口头描述的结合,我们可以更好地理解视频中复杂的情节和角色之间的互动。而且,通过准确的时空定位,我们可以知道描述中的每个单词对应的具体位置。

VidLN 的应用非常广泛。例如,在视频叙事基础和视频问答等任务中,我们可以利用 VidLN 来提供更准确的答案和解释。VidLN 还可以帮助机器学习算法更好地理解视频内容,并在视频内容分析、智能监控和虚拟现实等领域发挥重要作用。
研究人员使用 VidLNs 在不同数据集上进行了注释,获得了不错的视频叙述。此外,VidLNs 的数据集还可以用于视频故事定位和视频问答等任务。虽然这些任务仍然具有挑战性,但该方法在这个领域取得了重要的进展。该研究为视觉和语言之间的连接提供了一个新的多模态视频注释方法,为相关任务的发展提供了基础。
项目网址:https://github.com/google/video-localized-narratives
论文:https://arxiv.org/abs/2302.11217
深入了解 Meta 追赶 AI 的步伐:迟迟未用 GPU 导致人工智能落后对手
根据路透社查阅的一份日期为9月20日的公司备忘录,在2022年夏天即将结束时,Meta公司首席执行官马克·扎克伯格召集他的高级副手,对公司的计算能力进行了5个小时的剖析,重点是其从事尖端人工智能工作的能力。站长网2023-04-26 16:35:320000Adobe推3D图标工具 Project Neo 可快速2D转3D
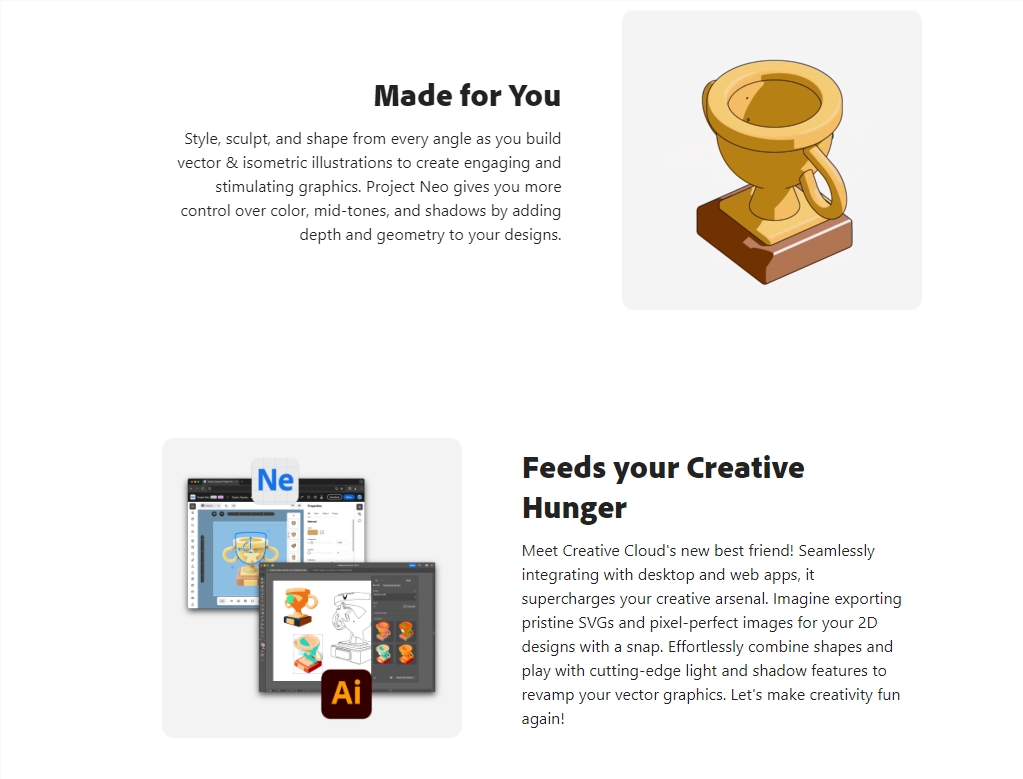
Adobe公司最新推出的ProjectNeo,是一项革命性的3D技术,旨在通过3D元素和效果的整合,提升传统2D图形设计的视觉效果和制作效率。这项技术不仅让2D设计中的元素看起来具有深度和体积,更通过高效的工具和流程,极大地加快了设计的速度。站长网2024-05-06 20:36:030000中宣部出版局副局长杨芳:着力实现人工智能、游戏引擎、虚拟现实等技术突破
中国国际数字娱乐产业大会(CDEC)今天在上海召开。中宣部出版局副局长杨芳表示,数字内容产业是数字时代具有广泛影响的新兴文化业态,是文化产业的重要组成部分和文化建设的重要力量。站长网2023-07-27 14:05:410000gpt crawler:从URL爬取网站生成结构化知识,创建定制GPT
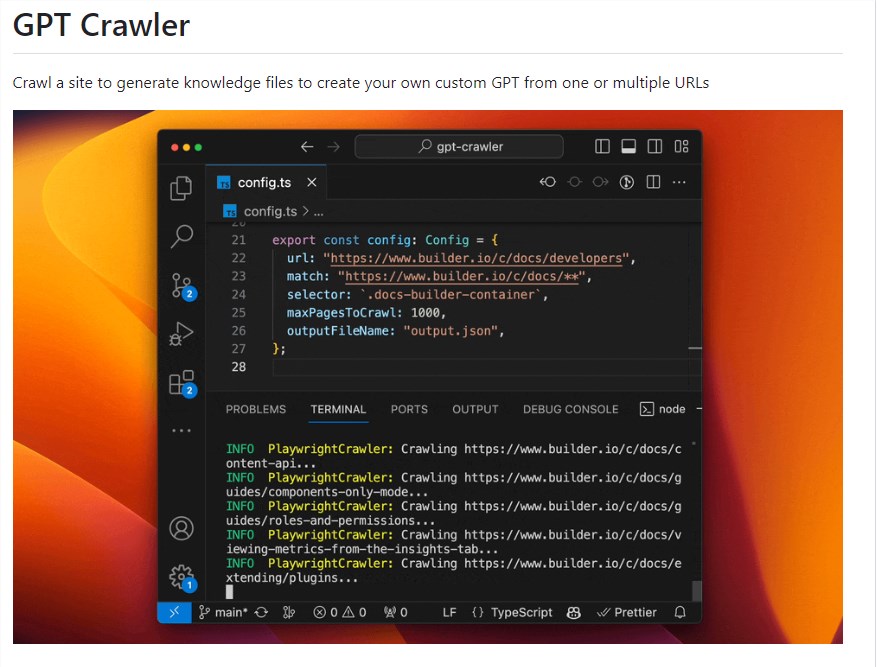
gptcrawler是一款强大的工具,能够将网站内容全面地爬取下来,并将其转换成结构化知识,为GPTs的学习提供了有力支持。站长网2023-11-21 10:49:150005