给AI Agent完整的一生!港大NYU谢赛宁等最新智能体研究:虚拟即现实
【新智元导读】近日,来自香港大学的Jihan Yang和纽约大学的谢赛宁等人发表了新的成果,将真实世界的地图、街景等各种信息融入Agent所在的虚拟世界,为智能体的未来赋予了无限可能。
怎样能构建更强大的AI Agent?
答案是给他们一个完整而真实的世界。
最近,来自香港大学的Jihan Yang和纽约大学的谢赛宁等人,联合发表了一项新研究:在虚拟环境中模拟现实世界。

论文地址:https://arxiv.org/abs/2402.03310
代码地址:https://github.com/VIRL-Platform/VIRL
项目名称V-IRL,能够弥合数字环境与人类居住的世界之间存在的巨大差距,让Agent在模拟的真实世界环境中执行各种复杂的任务。
V-IRL中的环境数据完全来源于真实世界:地图、地理信息、街景......可以说,V-IRL给了Agent真实而完整的一生。
V-IRL是一个可扩展的平台,利用地图、地理空间和街景图像等API将AI智能体嵌入到地球上的真实城市中。

V-IRL可以作为一个巨大的测试平台,用于衡量开放世界计算机视觉和具身人工智能的进展,具有前所未有的规模和多样性,提供对全球数千亿张图像的结构化访问。
截至2022年5月,仅Google街景就拥有超过2200亿张图像,并且还有许多其他图像和数据来源可以合并以丰富环境。
V-IRL Agent
研究人员使用V-IRL实例化了一系列智能体,他们以其丰富的感知和描述数据为基础,解决了各种实际任务。

比如这个Peng,为了注册为访问学生,需要访问纽约市的几个地方来获得一些文件。

利用地理定位和地图功能,Peng可以沿着最短的路径行走来节约时间:

语言驱动
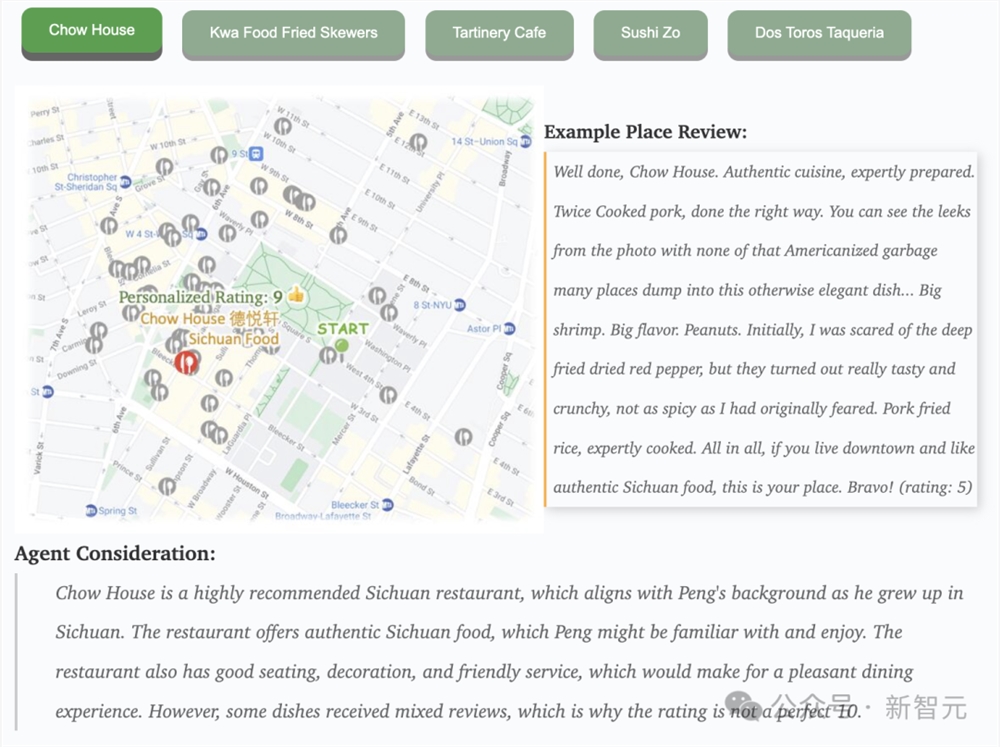
下面这位Aria,可以搜索附近的餐馆。然后,她综合公众评论,通过GPT-4提出最终建议。

对于上面来自四川的Peng同学,Aria推荐了辛辣的中式联合餐厅Chow House,让他尝到了家的味道。
Vivek是一位房地产经纪人,他使用房地产API在Peng所需的地区和价格范围内寻找潜在的公寓。


Vivek使用GPT-4提供整体评级和伴随推理。他最推荐的是一套性价比高的1居室公寓,每月1986美元,靠近超市、2个公交车站和健身房。
视觉驱动
RX-399,是一个城市辅助机器人。

在下面的演示中,他沿着预定义的城市路线导航,使用开放世界探测器和地理定位模块标记所有垃圾箱。
,时长01:18

Imani是一位城市规划师,

她为RX-399设置了穿越中央公园和感兴趣物体的路线,RX-399遍历了这些路线并记录了所有检测到的实例。
在RX-399完成其路线后,Imani会以不同的细节水平分析RX-399收集的数据。

Imani使用RX-399收集的数据对纽约市中央公园的垃圾箱、消防栓、公园长椅进行可视化。上图显示了公园内垃圾箱、消防栓和长凳的一般分布,Imani还可以放大到特定区域。
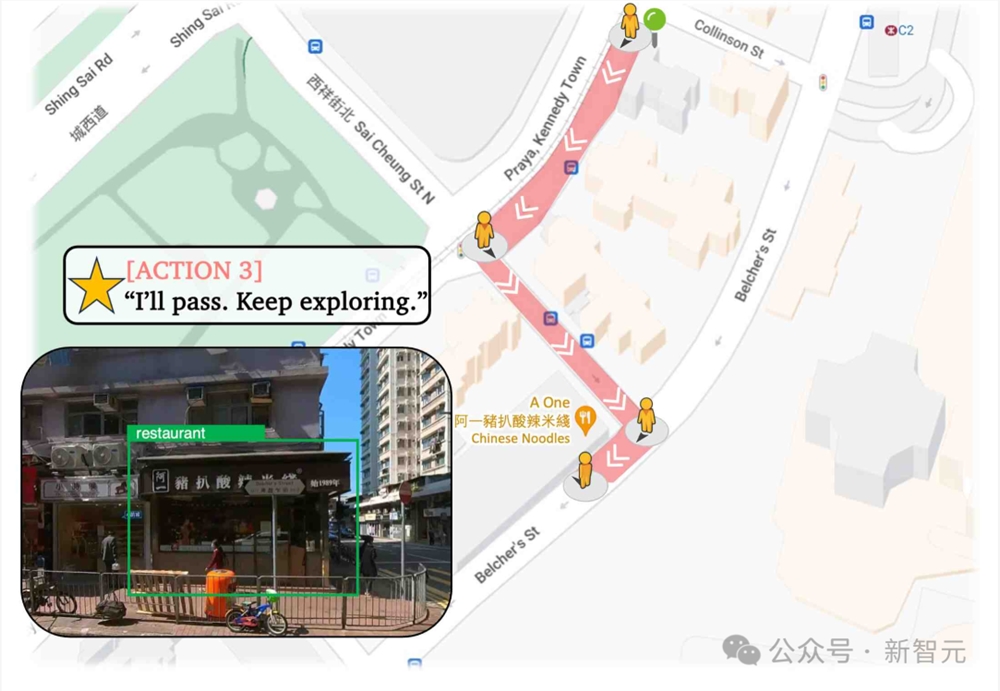
Hiro是一位经验丰富的旅行者,他使用开放世界检测来寻找餐厅;使用VQA来选择合适的道路;使用地点评论和LLM来决定一个地点是否适合自己。

下面是Hiro在香港的午餐探索:




协作
人类经常通过协作来解决复杂的现实世界任务。将复杂任务拆解为简单的子任务,交给不同领域的专业人士。
所以当Agent自己没办法完成任务的时候,就应该求助。
Ling是个游客,她首先从当地人那里获得路线描述,然后在V-IRL中,Ling可以使用开放世界识别和地图来调整自己的行进路线。

同时,识别街道上的视觉地标有助于GPT-4就转向方向、前进和停止的位置给出正确的决定.
最后一位Diego是礼宾专家:

他不仅会考虑你的身体和精神状态、每项活动的预算,还会预测你在参加每项活动时的状态变化和费用。
他会考虑到V-IRL平台提供的真实旅行时间,并与另一个餐厅推荐Agent合作选择合适的餐饮方案。

当你调整了自己的状态并通知Diego之后,他会立即修改计划以满足要求。
Diego使用迭代计划流程。首先,Diego使用GPT-4为第一项活动创建一个初步计划草案,并将用户的简历、要求和以前的活动纳入工作记忆。
然后,通过分层协调(真实的地理空间/地点信息)、感知估算(活动成本和对人类状态的影响)和监督(预算和潜在干预)对草案进行细致完善。
系统基本原理
V-IRL的分层设计把全球各个真实的城市变成了一个庞大的虚拟空间。在这里,智能体可以被构建出来解决实际任务。
其中,平台是整个系统的基础,为智能体提供了必要的组件和基础架构。
在这之上,智能体能够展现出感知、思考、行动和合作等更高级的能力。
最后,智能体通过这些能力和用户自定义的信息,在针对特定任务设计的运行程序中找到解决问题的方法。
V-IRL基准测试的核心在于它能够处理来自真实世界感觉输入的地理上多样化的数据,并且提供了一个便捷的API与谷歌地图平台(GMP)进行交互。
基于此,研究人员构建了三个V-IRL基准测试,目的是检验现有视觉模型处理这类开放世界数据的能力。
V-IRL地点:定位
- 动机
人们每天在城市中穿梭,为了各种目的前往不同地点。
因此,可以利用街景图像及其相关的地点数据,来测试视觉模型在日常地点定位任务上的表现。
- 设置
研究人员对RX-399智能体进行了微调,使其能够在定位和识别20种地点类型的同时,穿越多边形区域。
测试共包含三种知名的开放世界检测模型:GroundingDINO、GLIP和Owl-ViT。
此外,研究人员还设置了一个简单的基准模型——CLIP(结合GLIP提案),即使用CLIP对GLIP提出的分类进行重新分类。
模型的评估依据是定位召回率,即正确定位的地点数与总定位尝试中的地点数之比。

- 结果
由下表所示,开放世界检测器如GroundingDINO、Owl-ViT和GLIP对某些特定地点类型(例如学校、咖啡馆和便利店)是有明显偏好的。
与之相比,CLIP(结合 GLIP 提案)能识别更多种类的地点。这主要是因为对象检测数据集中存在的类别偏差,这些数据集通常只包含有限的词汇。
因此,即便是使用了CLIP进行初始化的检测器,如Owl-ViT,其能识别的词汇范围也会在微调之后缩小。
这些发现表明,对于那些在对象检测数据集中不太常见的类别,使用不依赖于特定类别的对象提案,进而利用零样本识别技术进行开放世界定位,是一种很有潜力的方法。

V-IRL地点:识别与视觉问答
- 动机
相较于在街景图像上进行的复杂的V-IRL地点定位任务,人们在现实生活中可以通过近距离观察来轻松识别各种商业场所。
鉴于此,研究人员对现有的视觉模型在两种以地点为主的图像感知任务上进行了评估:
(1)识别具体的地点类型;
(2)通过视觉问答来识别人类的意图,也就是意图VQA。
- 设置
在识别方面,研究人员评估了10种开放世界识别模型。测试使用的是以地点为中心的图像,而模型需要从96个选项中识别出地点类型。

在意图VQA方面,研究人员还评估了8种多模态大语言模型(MM-LLM),方法是通过包含有4个选项的多选题来判断人类的可能意图。
V-IRL地点VQA的过程如下图所示,其中每个问题的可能答案和正确答案都是由GPT-4自动生成的。
- 结果
如下表所示,在V-RL地点识别任务中,CLIP(L/14@336px)的表现超过了Eva-02-CLIP和SigLIP的最大版本,凸显了CLIP数据的质量之高。
表格的底部显示,在意图VQA方面,BLIP2、InstructBLIP和LLaVA-1.5表现优异,而其他模型则表现不佳。
可以看到,这三个表现最好的MM-LLM在评估过程中给出了一致的答案,而其他模型因为选择不一致而常常失败。
、
V-IRL视觉语言导航
- 动机
Intentional Explorer和Tourist智能体想完成复杂的任务,就必须要同时利用视觉和语言模型。
因此,研究人员通过引入结合了真实街景的新任务,创建出了V-IRL视觉语言导航(VLN)基准测试。
- 设置
研究人员微调了Tourist智能体的实现方式,将其识别组件替换为了不同的基准测试模型,负责在导航过程中识别视觉地标。接着,GPT-4会根据识别的结果预测下一步动作。其中,导航指令由Local智能体生成。
这里,研究人员共评估了四种方法在导航时识别地标的能力:
(1)通过搜索附近地标的近似方法;
(2)零样本识别器CLIP和EVA-02-CLIP;
(3)多模态大语言模型LLaVA-1.5;
(4)使用OCR模型识别街景中的文本,然后通过GPT解析答案。
- 结果
如下表所示,当使用oracle地标信息时,强大的LLM能够精准地理解导航指令并做出正确的决策,表现令人印象深刻。
但是,当依赖视觉模型从街景获取地标信息时,成功率大幅下降,这说明视觉模型的感知存在误导,影响了LLM的决策。
在这些识别器中,CLIP和EVA-02-CLIP的大规模版本表现更为出色,凸显了模型scaling的优势。
LLaVA-1.5作为视觉编码器使用CLIP(L/14@336px)时表现不佳,可能是因为在指令微调过程中存在对齐问题。
另外,PP-OCR( GPT-3.5)的成功率为28%,体现出OCR对于视觉地标识别至关重要。
地理多样性及挑战
V-IRL基准测试涵盖了全球12个不同的城市,进而提供了一个独特的视角,来观察视觉模型在不同地区可能存在的偏差。
正如下方图表所展示的,视觉模型在尼日利亚拉各斯、日本东京、中国香港和阿根廷布宜诺斯艾利斯的表现都不尽如人意。
其中,东京、香港和布宜诺斯艾利斯等城市普遍使用了非英语文字。而拉各斯的街景更是与发达城市相比大相径庭,直接难倒了几乎所有的视觉模型。
这一现象揭示了一个重要的问题:目前的视觉模型在处理包含多种语言的图像数据时面临挑战。
结论
开源平台V-IRL的设计初衷是为了缩小数字世界与真实世界之间的感知差异,让AI Agent能够在一个既虚拟又真实的环境中与现实世界进行交互。
借助V-IRL,智能体可以基于真实的地理信息和街景图片,培养出丰富的感知能力和对环境的理解。
研究人员通过构建不同的示例智能体和开展性能评估,展示了这个平台在全球视觉数据处理方面语言和视觉模型的广泛应用潜力,为提高AI在理解环境、做出决策和处理现实世界信息方面的能力开启了新的可能。
随着空间计算技术和机器人系统的日益普及,AI Agent的需求和应用场景将不断扩大。
从个人助手到城市规划,再到为视力受限者打造的生活辅助工具,我们期待着一个能够深刻理解周围世界的智能体时代的到来。
作者介绍
JihanYang
论文一作Jihan Yang目前在香港大学电子与电气工程学院攻读博士学位,导师是Xiaojuan Qi博士。
在此之前,他在中山大学获得了学士学位,导师是Liang Lin教授和Guanbin Li教授。
此外,他还与Ruijia Xu、Shaoshuai Shi博士、unyu Ding和Zhe Wang博士有着密切的合作。
参考资料:
https://virl-platform.github.io/
清华大学开发出新视觉语言模型 可更准确理解 GUI
清华大学智普AI的研究人员开发了一种新的视觉语言模型(VLM),名为CogAgent。该模型专门设计用于理解和导航图形用户界面(GUI)。CogAgent通过采用低分辨率和高分辨率图像编码器而脱颖而出。这种双编码器系统允许模型处理和理解复杂的GUI元素和文本内容,这是有效GUI交互的关键要求。站长网2023-12-27 15:46:220000清华大学团队推出RTFS-Net:革新视听语音分离,百万参数实现高效性能
**划重点:**1.🎙️RTFS-Net是首个采用少于100万个参数的视听语音分离方法,通过压缩-重建策略显著减少计算复杂度。2.🌐针对传统视听语音分离方法的问题,RTFS-Net创新性地解决了时域和时频域方法的挑战,提高了在复杂环境中的性能。3.🚀在三个基准多模态语音分离数据集上,RTFS-Net在大幅降低模型参数和计算复杂度的同时,接近或超越了当前最先进的性能。站长网2024-03-06 17:46:320002小米汽车价格上热搜 官方多次辟谣:发布前不可能有售价
随着2月22日晚小米14Ultra暨人车家全生态新品发布会的日益临近,网络上关于小米新品的讨论愈发激烈。小米14Ultra、小米平板6SPro等多款新品即将亮相,但在这其中,小米汽车的价格问题似乎成为了公众最为关注的焦点。站长网2024-02-21 17:23:120000YouTube 正在全力发展人工智能:为创作者推出一系列 AI 驱动的新工具
站长之家(ChinaZ.com)9月22日消息:在YouTube平台上,将有更多内容部分采用生成式人工智能来创作。该视频平台在周四的年度YouTube创作活动上宣布了几个新的AI工具支持创作者。其中,今年晚些时候或明年推出的功能包括:AI生成的照片和视频背景、AI视频主题建议和音乐搜索等。站长网2023-09-22 09:37:280000研究:AI在诊断前预测了三分之一的乳腺癌病例
划重点:1.人工智能通过分析X光检查数据,能在乳腺癌诊断前两年预测三分之一的病例。2.研究结果表明,AI在乳腺癌早期诊断中有巨大潜力,尤其对于筛查检测和间隔检测的病例。3.尽管研究充满希望,但专家强调AI应与医疗专业知识相结合,而不是替代医生的经验。一项最新的研究发现,人工智能(AI)具备在乳腺癌诊断前进行早期预测的能力,为患者带来了新的希望。站长网2023-10-26 14:55:530000