清华大学团队推出RTFS-Net:革新视听语音分离,百万参数实现高效性能
**划重点:**
1. 🎙️ RTFS-Net是首个采用少于100万个参数的视听语音分离方法,通过压缩-重建策略显著减少计算复杂度。
2. 🌐 针对传统视听语音分离方法的问题,RTFS-Net创新性地解决了时域和时频域方法的挑战,提高了在复杂环境中的性能。
3. 🚀 在三个基准多模态语音分离数据集上,RTFS-Net在大幅降低模型参数和计算复杂度的同时,接近或超越了当前最先进的性能。
清华大学的胡晓林团队最近推出了一项创新性的视听语音分离方法,称为RTFS-Net。这一方法通过采用压缩-重建的策略,不仅实现了百万参数以下的视听语音分离,而且显著减少了计算复杂度,为音视频分离领域带来了新的视角。
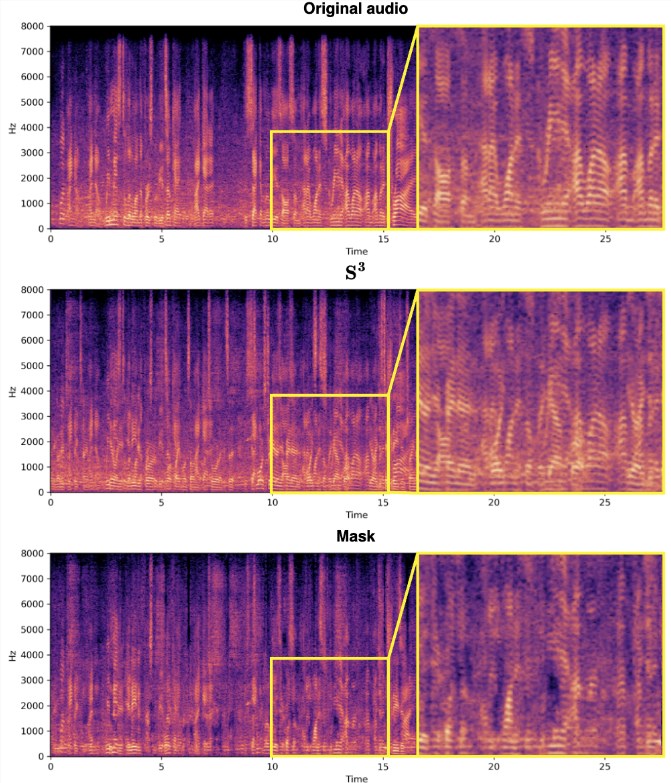
传统的视听语音分离方法通常依赖于复杂的模型和大量的计算资源,尤其在嘈杂背景或多说话者场景下性能受到限制。RTFS-Net通过创新性地解决时域和时频域方法的挑战,突破了这些限制。时域方法提供高质量的音频分离效果,但计算复杂度高,而时频域方法虽然计算效率更高,却一直面临缺乏独立建模、未充分利用多个感受野的视觉线索和对复数特征处理不当等问题。
RTFS-Net的关键在于引入了RTFS块,该块通过双路径架构在时间和频率两个维度上对音频信号进行有效处理。具体来说,RTFS块首先进行时间和频率维度的压缩,然后在压缩后的维度上进行独立建模,最后通过融合模块将两个维度的信息合并。这一策略不仅减少了计算复杂度,还保持了对音频信号的高度敏感性和准确性。
此外,RTFS-Net还引入了跨维注意力融合(CAF)模块,有效融合音频和视觉信息,提高了语音分离效果。CAF模块采用深度和分组卷积操作生成注意力权重,动态调整输入特征的重要性,通过对视觉和听觉特征应用注意力权重,实现在多个维度上聚焦于关键信息。
最终,RTFS-Net的实验结果表明,在三个基准多模态语音分离数据集上,该方法在大幅降低模型参数和计算复杂度的同时,接近或超越了当前最先进的性能。通过不同数量的RTFS块的变体展示了在效率和性能之间的权衡,其中RTFS-Net-6在性能与效率方面取得了良好的平衡,而RTFS-Net-12在所有测试的数据集上表现最佳,证明了时频域方法在处理复杂音视频同步分离任务中的优势。
这一创新性的视听语音分离方法为提高AVSS性能提供了新的思路,不仅降低了计算复杂度和参数数量,而且在保持显著性能提升的同时,为音视频分离领域注入了更多创新和高效的架构。
论文地址:https://arxiv.org/abs/2309.17189
代码地址:https://github.com/spkgyk/RTFS-Net(即将发布)
1097 名用户报告 ChatGPT 使用出现问题 OpenAI 现已修复
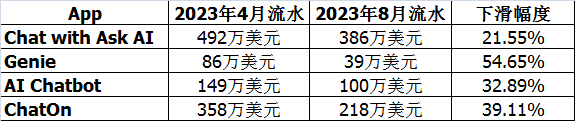
根据中断跟踪网站Downdetector提供的图表显示,今天有1097名用户(美国东部时间23日晚上11点13分开始)在使用ChatGPT时遇到问题,报告了OpenAI服务的中断。图片截自OpenAI现在据OpenAI官网显示,ChatGPT服务中断故障已经修复。站长网2023-04-24 14:00:520001我抽到的卡牌卖了200个“钻石”,聊一聊差点爬到美国Top5的AIChat卡牌游戏
在AI相关产品里,陪伴用户聊天的“AI聊天机器人”算是最早一种得到普及的产品形式。例如早在人们还不知道ChatGPT是啥的时候,Replika在2017年就上线了,通过文字以及视频通话为用户提供情感支持。目前Replika官方宣布其用户总量已超过1000万人。站长网2023-09-12 13:58:370000深圳充电宝收费统一标准:免费时长不少于5分钟
快科技3月12日消息,虽然共享充电宝在外使用很方便,但越来越贵的价格也让很多人望而却步,成为明码标价新型刺客”。日前,深圳市消费者委员会发布《深圳市共享充电宝行业自律公约》。要求商家承诺,充电宝租借免费时长不少于5分钟;租借的计价时间单位不超过半小时;因所在地难以及时归还充电宝时,企业核实后可暂停计费等内容。站长网2024-03-12 12:06:110001无人驾驶公司Oxa融资1.4亿美元 希望利用AI改善通勤体验
文章概要:1.Oxa是无人驾驶领域的初创公司,完成了1.4亿美元C轮融资2.它与Beep合作,在佛罗里达推出自动驾驶班车3.Oxa认为自动驾驶单人轿车难以改善拥堵状况无人驾驶汽车正在蓬勃发展,Oxa就是该领域的一家初创公司。它刚完成1.4亿美元的C轮融资,与交通科技公司Beep合作,准备在佛罗里达推出自动驾驶班车,未来可能扩展到北卡罗来纳和加利福尼亚等地。站长网2023-09-04 11:35:300000小鹏P7i磷酸铁锂电池版上市 售价22.39万起
小鹏汽车宣布其P7i车型新增两款车型上市,售价区间为22.39-23.99万元。这两款车型的最大亮点是采用了容量为64.4kWh的磷酸铁锂电池,CLTC续航里程达到了550km。值得一提的是,新款P7i的Max版还支持城市高阶智驾功能,预计在2023年11月覆盖25个城市,12月覆盖50个城市,2024年覆盖200个城市。站长网2023-11-06 11:38:130000