清华大学开发出新视觉语言模型 可更准确理解 GUI
站长网2023-12-27 15:46:220阅
清华大学智普AI的研究人员开发了一种新的视觉语言模型(VLM),名为 CogAgent。该模型专门设计用于理解和导航图形用户界面(GUI)。
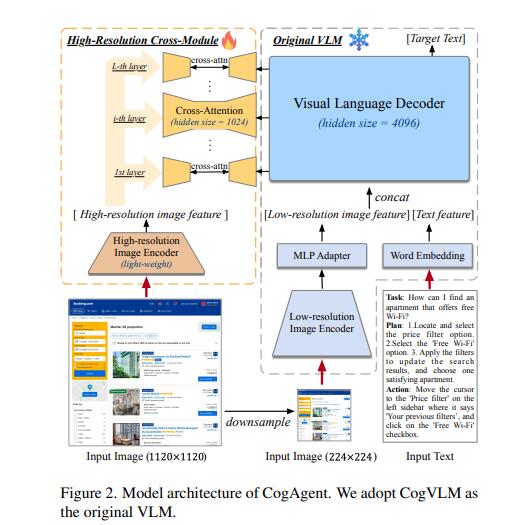
CogAgent 通过采用低分辨率和高分辨率图像编码器而脱颖而出。这种双编码器系统允许模型处理和理解复杂的 GUI 元素和文本内容,这是有效 GUI 交互的关键要求。
CogAgent 的架构具有独特的高分辨率跨模块,这是其性能的关键。该模块使模型能够有效处理高分辨率输入(1120x1120像素),这对于识别小型 GUI 元素和文本至关重要。
CogAgent 在各种任务中优于现有的基于 LLM 的方法,特别是在 PC 和 Android 平台的 GUI 导航方面。该模型还在多个文本丰富和一般视觉问答基准上表现优异。
这项研究的结果表明,CogAgent 代表了 VLM 的重大飞跃,特别是在涉及 GUI 的环境中。其在可管理的计算框架内处理高分辨率图像的创新方法使其有别于现有方法。该模型在不同基准测试中优异的性能表明其在自动化涉及 GUI 操作和解释的复杂任务方面的潜力。
CogAgent 的潜在应用包括:
自动化 GUI 操作,例如点击按钮、输入文本和选择菜单。提供 GUI 帮助和指导,例如解释功能和提供操作说明。开发新的 GUI 设计和交互方式。
CogAgent 仍处于早期开发阶段,但其潜在影响是巨大的。该模型有可能彻底改变我们与计算机交互的方式。
地址:https://github.com/THUDM/CogVLM
0000
评论列表
共(0)条相关推荐
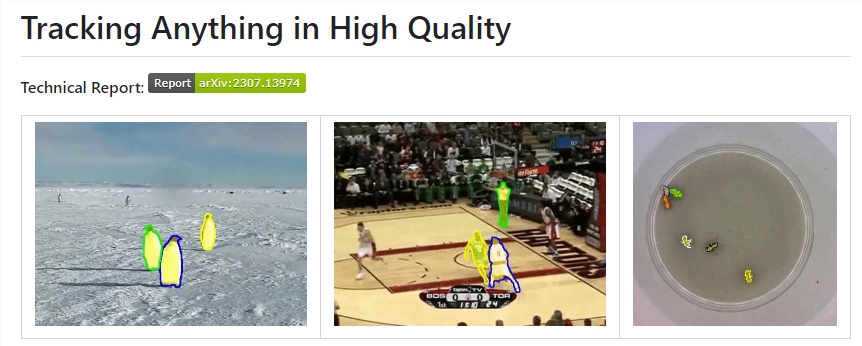
达摩院推出人工智能框架HQTrack 可实现视频高质量跟踪
中国大连理工大学和阿里巴巴集团DAMOAcademy提出的一个名为HQTrack的系统。该系统由视频多目标分割器(VMOS)和掩模优化器(MR)组成,旨在实现对视频中任何目标的高质量跟踪。项目地址:https://github.com/jiawen-zhu/HQTrack站长网2023-07-31 10:17:090000拼多多在微信的“隐秘生意”,年成交额已超千亿?
在公域流量难寻增长、平台与品牌发力私域的当下,活跃在团购群里的“团长”,如今越来越成了“香饽饽”。来自各个渠道、手握供应链资源的老板们都渴望与“团长”获得联系。社交平台上,只要是“团长”的留言,下边总有一串长长的供应商的留言。杭州电商社群快团联盟的创始人老张是从2021年开始感受到这种趋势的。站长网2023-08-13 09:30:490000对话千万GMV视频号玩家:商业化进入2.0时代,商家疯抢公域流量
“自8月视频号发布新规‘直播间、首页、短视频置顶链接不能加企微’,相对收紧公私域联通通道后,视频号就已经进入商业化2.0时代。”或许是因为身兼千万GMV知识博主、卖货主播和亿级服务商、MCN主理人等多重身份,又是产品经理出身,润宇更习惯从流量角度看待视频号。在他看来,8月新规之前,视频号是以私域流量为核心的商业化1.0时代,8月新规之后,视频号将进入以公域流量为核心的商业化2.0时代。站长网2023-09-25 22:09:570000一开发者用OpenAI 技术构建了个AI宣传机器,强调大规模生产的AI虚假信息危险性
文章概要:1.一国外开发者2个月内利用OpenAI工具打造AI宣传机器,每月运营成本低于400美元2.项目目的是展示AI大规模生产虚假信息的危险3.开发者没有将模型投入使用,因为它会推动假信息传播。站长网2023-09-04 12:16:010000亚马逊在AWS峰会上发布生成式AI并推出新的 AI 项目
周二,亚马逊在纽约举办了AWS(亚马逊网络服务)峰会,这是一个关注亚马逊在云领域的工作的活动,包括展览、学习会和主题演讲。今年,亚马逊利用这个平台发布了几个重要的生成式人工智能公告,这些公告将优化开发者创建人工智能平台的过程,并简化企业对人工智能的集成。要构建和运行一个人工智能模型,有几个组成部分,从你将用来为模型提供动力的实际芯片开始,然后构建和训练模型,最后将模型应用于现实世界。站长网2023-07-27 09:58:580000