智能的本质就是压缩?马毅团队5年心血提出「白盒」Transformer, 打开LLM黑盒!
【新智元导读】来自UC伯克利,港大等机构的研究人员,开创性地提出了一种「白盒」Transformer结构——CRATE。他们通过将数据从高维度分布压缩到低维结构分布,实现有效的表征,从而进一步实现了有竞争力的模型性能。这也引发了一个更为深远的讨论——难道智能的本质就是压缩吗?
AI界大佬对于大模型的安全问题一直以来争吵不休,全都归咎于神经网络「黑盒」,让所有人捉摸不透。
现实中,如果能找到一种构架,兼具Transformer的结构和功能性优势,又有极好的可解释性。
那么,大模型的安全性问题,是不是就有解了?

为了消除未来超级AI给人类带来的风险,Hinton等人大肆鼓吹「AI末日论」,也许能吸引公众注意力,促进达成共识。
但最终解决问题,必须要从技术层面找到能「彻底消灭」AI风险的可行路径。
拆解大模型「黑盒」,就成了最关键一步。
由马毅教授带领的来自UC伯克利,TTIC,上科大,UIUC,JHU,港大的研究人员,开创性地提出了一种「白盒」Transformer构架——CRATE,能在保持模型良好性能的同时,大大增强模型的可解释性。

论文地址:https://arxiv.org/abs/2311.13110
压缩,就是AI系统的本质?
在研究人员看来,要想获得可解释的深度神经网络,必须要从「第一性原理」出发,抓住深度学习的本质。
AI教父Hinton在90年代,就提出了「深度学习的本质可能就是压缩」的概念。
众多AI大佬,在各种场合对这个概念性的提法做出了一些经验性的总结,继续扩展了这一理论。
例如,8月份,OpenAI首席科学家Ilya Sutskever在UC伯克利的一个AI理论讲座上分享到:
「压缩可能就是学习的本质!」
https://simons.berkeley.edu/talks/ilya-sutskever-openai-2023-08-14
而马毅团队通过5年多的努力,完成了在这篇长达124页的论文,更加完整地提出了这个理论。
更为重要的是,他们根据这个理论进一步设计出了可以执行的算法,并在实践中获得了非常好的性能表现。

CRATE在屏蔽自动编码的任务上实现了有竞争力的表现
研究团队认为,数据表征学习的核心目标是将数据从高维度分布压缩到低维结构分布,从而实现有效的表征。
这种压缩可以通过「稀疏编码率减少」这个量化指标来衡量。
研究团队通过朴素的优化架构,将压缩和稀疏作为损失函数,可以迭代地将数据分布压缩到低维混合高斯分布模型,从而推导出类似Transformer的神经网络结构。
这就是构建类Transformer构架的第一性原理。
而进一步证明压缩和去噪之间存在内在等价关系,就可以为构建Decoder提供理论依据,让编码器和解码器具有几乎相同的结构。
研究团队的实验结果表明,尽管架构较简单,CRATE在许多任务和数据集上都能与现有的Transformer模型获得类似的表现,同时其每一层和操作都可以明确解释。
分析结果表明,CRATE相对于标准Transformer确实具有更强的可解释性。
深度学习研究的新范式
而这个研究另一方面的意义在于,它一针见血地指出了:
「压缩就是一切。」
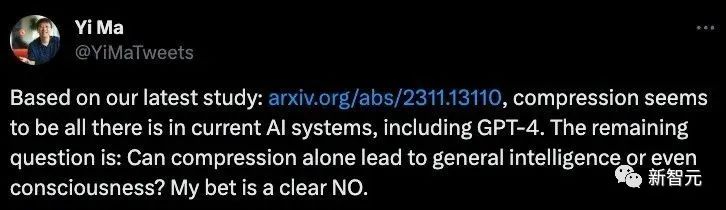
在马毅教授看来:
我们的这项研究表明:压缩似乎是当前人工智能系统的全部,包括 GPT-4。
剩下的问题是:仅压缩就能带来一般智能甚至意识吗?我敢打赌,答案显然是否定的。
通过这项研究,所有人对Transformer类型的AI系统获得了更加清晰的理解。
而这就进一步说明,在外界看起来神奇和神秘的AI产品,只要背后的技术是基于Transformer,那就不太可能做超出纯机械数据压缩(编码)和插值(解码)的事情。
之所以大众对于AI产品会有很多不美丽的幻想,可能根本原因就在于深度学习理论和实践长期脱节。
而研究团队的这项工作,就是想弥合理论和实践之间的鸿沟,从而让AI产品背后的技术,理论都能严谨地结合起来。
而将理论层面的问题厘清之后,研究人员能看到,现有的系统离真正的智能系统还有很远的距离,未来还有太多提升的空间。
现有的Transformer构架可能只是一种性价比不高的系统,后来人还需要继续努力!
马毅教授在和我们的沟通中表示:现在甚嚣尘上的「AI末日论」,直接促使他们紧迫地整合各个方法,用学术界有限的资源,去尽力完整充分地对理论进行验证。
如果在时间和资源上更充裕,实验的验证部分将会更加充分,规模可以更大。
在完成这项工作,弄清了现有方法的边界和本质之后,研究团队会投入到更重要,更有开拓性的工作中去。
而「AI末日论」如果最后导致人工智能的研究被限制,甚至扼杀,将有违所有人的利益。而如果因此造成了可能的垄断,更是不可接受。
白盒Transformer——CRATE
研究人员根据第一性原理构建了一个类似Transformer的架构,取名为CRATE(Coding RATE transformer)。
它在很多标准任务上能达到很有竞争力的性能,同时还具有许多附带的优点。
CRATE是一种白盒(数学上可解释的)Transformer架构,其中每一层执行交替最小化算法的单个步骤来优化稀疏率降低目标(sparse rate reduction objective)。
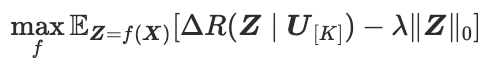
其中,
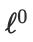
norm提高了最终token表征

的稀疏性。函数定义如下:
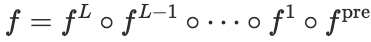
其中,
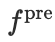
是预处理映射,
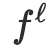
是
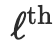
层前向映射,它转换token分布以逐步优化上述稀疏率降低目标。
更具体地说,
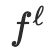
将token表征为
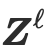
。
通过以下方式转换为
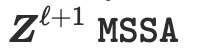
(多头子空间自注意力)块和ISTA(迭代收缩阈值算法)块,即

构架
CRATE的构架如下图所示:
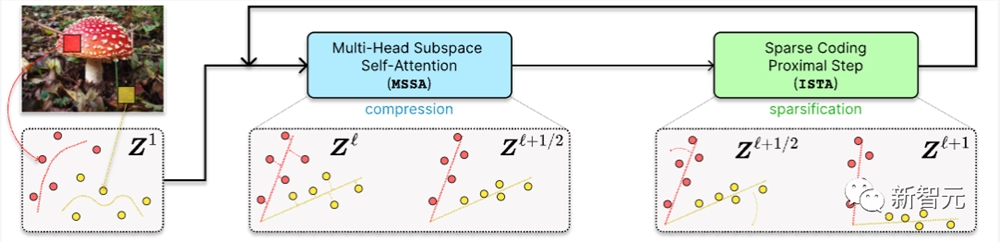
将输入数据 X 编码为标记序列 Z1后,CRATE构建了一个深度网络,通过针对局部模型的连续压缩,将数据转换为低维子空间的规范配置分布,生成
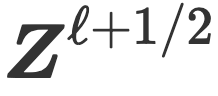
,并针对全局字典进行稀疏化,生成
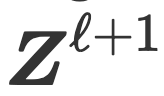
。
重复堆叠这些块并通过反向传播训练模型参数,可以产生强大且可解释的数据表征。
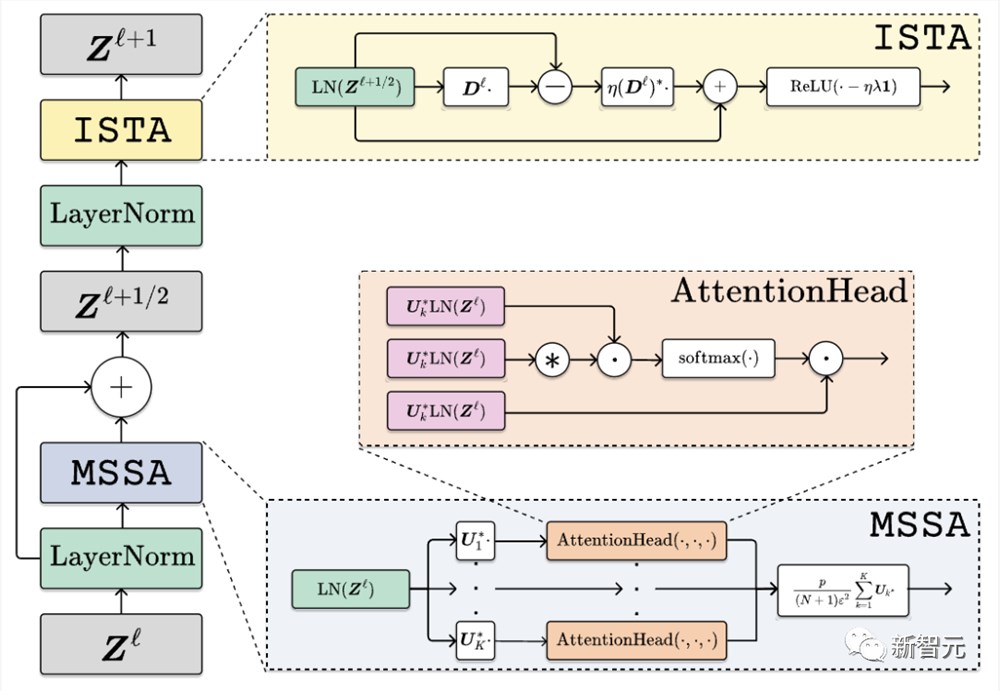
完整的架构只是这些层的串联,以及一些初始tokenizer和最终基于不同任务的架构(例如,分类头)。
分类
以下是CRATE 的分类流程。它和常见的视觉Transformer原理是相同的。
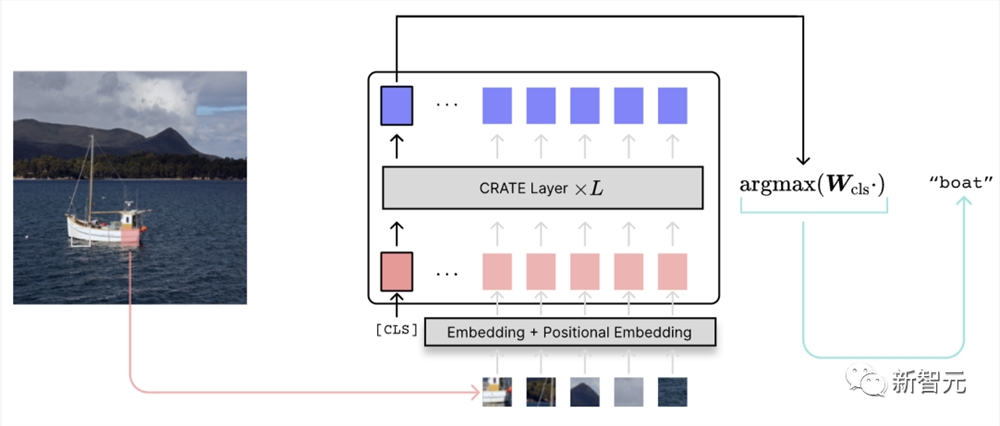
研究人员使用软最大交叉熵损失(soft-max cross entropy loss)来训练监督图像分类任务。以类似的缩放行为,他们使用经过分类训练的常用ViT获得了很有竞争力的性能表现。
例如,使用只有25%参数的ViT在ImageNet-1K上达到80%以上的top-1准确率。
分割和目标检测
CRATE的一个有趣现象是,即使在监督分类方面进行训练,它也会学习对输入图像进行分割,并且这种分割可以通过注意力图轻松恢复,如下面的流程(类似于 DINO)。
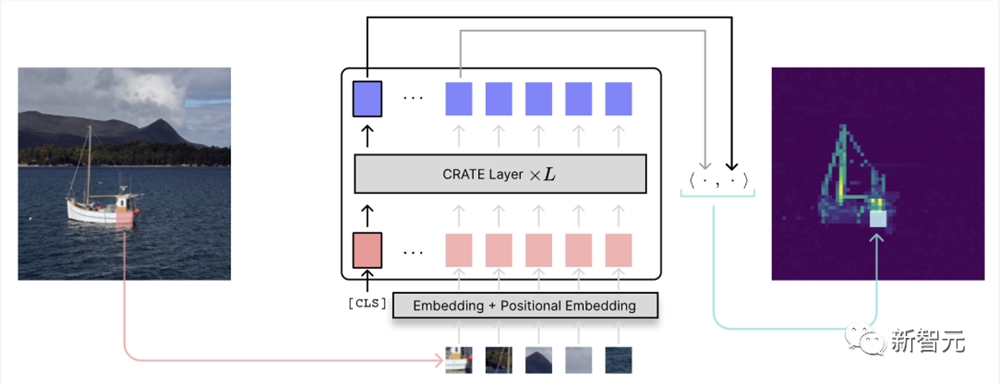
这种分割以前只在DINO中使用复杂的自监督训练机制的类似Transformer的架构中看到,但在CRATE中,分割是监督分类训练的副产品。特别是,该模型在任何时候都不会获得任何先验分割信息。
下面,研究人员展示了一些分割示例。

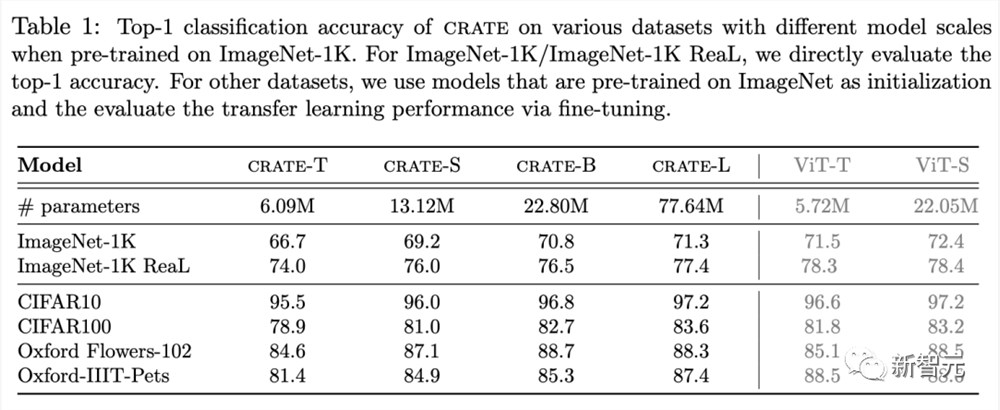
CRATE的另一个显著的特性是注意力头自动携带语。这意味着CRATE的任何分类结果都能进行事后的解释。
下面,研究人员将一些注意力头在几张图中的几种动物上的输出进行了可视化,显示了注意力头对应于动物的不同部分。而且结果表明,这种对应关系在不同动物的图片以及不同类别的动物图片中都是一致的。
自动编码
研究人员使用以下流程将CRATE扩展出了自动编码的能力。
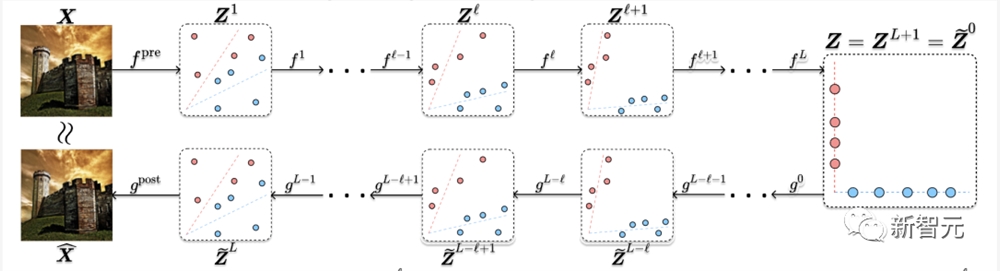
我们以扩散/最佳传输启发的方式构建解码器的每一层
:
如果我们认为
以某种方式传输其输入分布的概率质量,那么
被构造为该编码映射的近似逆。下面给出了完整的编码器和解码器层。

CRATE架构的这种变体在屏蔽自动编码任务上实现了具有竞争力的性能,如下面的示例所示。
此外,它还获得与经过分类训练的CRATE相同的涌现属性(如上所示)。
理论原理
研究人员通过对稀疏率降低的展开优化来推导编码器架构。优化稀疏率降低的表征ƒ是压缩和稀疏的,如下图所示,研究人员将它们描述为由编码器ƒ实现:
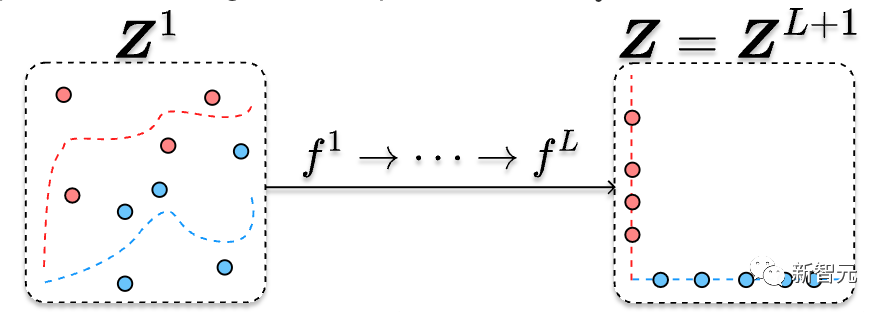
在CRATE中,压缩运算符

和稀疏化算子
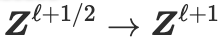
是稀疏率降低目标不同部分的近似(近端)梯度步骤。
为了导出解码器架构,研究人员提出了一种新颖的结构化去噪扩散(structured denoising-diffusion)框架,该框架类似于广泛用于图像数据生成模型的常见(普通)去噪扩散框架。
他们的框架依赖于压缩算子和得分函数(如在去噪扩散模型中使用)之间的定量连接,如下所示:
编码器和解码器分别通过结构化去噪和扩散过程的离散化而导出。重要的是,从展开优化导出的编码器和从结构化去噪导出的编码器具有相同的架构,如上所述。
GitHub项目
https://github.com/Ma-Lab-Berkeley/CRATE
可以使用以下代码定义一个CRATE模型。(参数是为CRATE-Tiny指定的)
frommodel.crateimportCRATEdim=384n_heads=6depth=12model=CRATE(image_size=224,patch_size=16,num_classes=1000,dim=dim,depth=depth,heads=n_heads,dim_head=dim//n_heads)预训练检查点(ImageNet-1K)
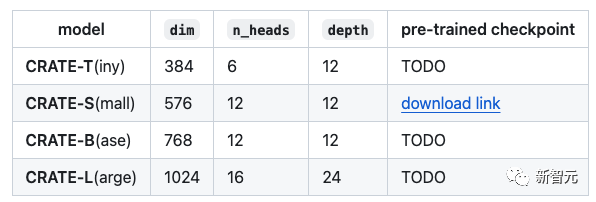
在ImageNet上训练CRATE
要在ImageNet-1K上训练CRATE模型,请运行以下脚本(训练 CRATE-tiny)。
作为示例,使用以下命令在 ImageNet-1K 上训练 CRATE-tiny:
pythonmain.py--archCRATE_tiny--batch-size512--epochs200--optimizerLion--lr0.0002--weight-decay0.05--print-freq25--dataDATA_DIR并将DATA_DIR替换为[imagenet-folderwithtrainandvalfolders]。
在CIFAR10上微调预训练/训练随机初始化的CRATE
pythonfinetune.py--bs256--netCRATE_tiny--optadamW--lr5e-5--n_epochs200--randomaug1--datacifar10--ckpt_dirCKPT_DIR--data_dirDATA_DIR将CKPT_DIR替换为预训CRATE权重的路径,并将DATA_DIR替换为CIFAR10数据集的路径。
如果CKPT_DIR是None ,则此脚本用于在CIFAR10上通过随机初始化来训练 CRATE。
参考资料:
https://arxiv.org/abs/2311.13110
https://ma-lab-berkeley.github.io/CRATE/
微信支付打通韩国!可直接扫Zero Pay二维码支付:覆盖全国
快科技8月21日消息,以往中国游客去韩国旅游还要提前准备好韩币,现在不用了。据报道,目前覆盖全韩的ZeroPay韩国本土支付平台已经完成微信支付的接入工作,韩国境内只要是支持ZeroPay支付的店铺均可以使用微信支付”来进行消费。无需在手机上下载额外任何App,仅用微信扫码即可轻松完成移动支付,非常方便。此外,韩国旅游发展局还为中国游客提供了丰厚的优惠福利。站长网2023-08-21 22:16:480001Wombo推AI头像应用程序Wombo Me
要点:制造DreambyWomboAI应用的Wombo公司推出新的AI头像应用WomboMe,允许用户将一张自拍照转化为多个逼真的头像。与其他市场上的AI头像应用不同,WomboMe只需一张自拍照片,即可几乎立即生成多个头像,为用户提供更简便的体验。站长网2023-12-01 10:29:540002出于对AI的担忧,亚马逊限制自助出版商每日最多发表3本书
文章概要:1.亚马逊宣布降低自助出版的每日书籍发表数量上限至3本,理由是对人工智能(AI)担忧。2.亚马逊称这一举措是为了防止滥用,尽管他们并未看到出版数量激增。3.亚马逊还发布了针对内容类型的指南,并要求创作者通知其有关AI生成内容,以控制AI对阅读、写作和出版的快速影响。站长网2023-09-21 12:18:100000魅族 All in AI 将停止传统「智能手机」新项目
2024年2月18日,魅族做出了一次重大决策,决定全力投入AI领域,停止新的传统智能手机项目,并将焦点转向“明日设备”AIForNewGenerations。魅族表示,经过两年的精心准备,魅族已经具备了向AI领域全面转型的能力。他们拥有一支完善的研发和供应链硬件团队,以及体系化开发、设计、交互的软件团队。这些团队将为魅族在AI领域的转型提供坚实的技术支持和服务保障。站长网2024-02-18 09:39:110000抖音海参哥,为什么还没有翻车?
各位村民好,我是村长。百度前公关VP在抖音翻车,据悉当事人璩静迫于各方面的压力已经离职,而其中还有一位“受害人”——抖音最受争议的商业IP网红海参哥。我们可以看到不管是社群、朋友圈,还是各种大大小小的自媒体、新闻媒体都也在纷纷挖苦吐槽海参哥的商业培训、付费社群等都是割韭菜。甚至觉得向海参哥付费的企业家、创始人、高管都是智障。但是大家思考过一个问题没有?0000











