谷歌研究团队推新AI方法SynCLR:从合成图像和字幕中学习视觉表征
划重点:
- 💡 SynCLR是一种新颖的人工智能方法,通过合成图像和合成字幕,实现对视觉表征的学习,无需使用真实数据。
- 💡 该方法通过三个阶段实现,包括合成图片字幕、生成合成图像和字幕,以及训练视觉表征模型。
- 💡 研究结果表明,SynCLR在图像分类、细粒度分类和语义分割等任务上表现出色,显示了利用合成数据训练强大AI模型的潜力。
近期,Google Research和MIT CSAIL共同推出了一项名为SynCLR的新型人工智能方法,该方法旨在通过使用合成图像和字幕,实现对视觉表征的学习,摆脱对真实数据的依赖。
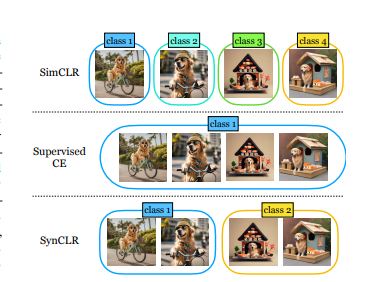
SynCLR的工作原理
研究团队首先提出了一个三阶段的方法。首先,在“合成图片字幕”阶段,他们采用大型语言模型的上下文学习能力,通过单词到字幕的转换示例,生成了大量的图片字幕。接着,在“生成合成图像和字幕”阶段,利用文本到图像扩散模型,生成了包含6亿张合成图片的数据集。最后,在“训练视觉表征模型”阶段,研究团队使用了掩蔽图像建模和多正对比学习,训练模型从合成数据中学到有意义的表征。
实验结果
研究结果表明,SynCLR在多个任务上取得了令人瞩目的成绩。通过与现有模型如CLIP和DINO v2进行比较,SynCLR在ImageNet-1K上的线性探测准确率以及细粒度分类和ADE20k上的语义分割任务上都表现出色。特别值得一提的是,SynCLR在以字幕为级别的细粒度上的优越性,为模型的可扩展性和在线类别增强提供了便利。
尽管SynCLR在合成数据上展现出了强大的性能,研究团队也提出了一些改进方向。其中包括使用更复杂的大型语言模型、优化不同概念之间的样本比例、探索高分辨率训练阶段等。这些改进有望进一步提升合成数据在训练人工智能模型中的效果。
项目网址:https://github.com/google-research/syn-rep-learn
论文网址:https://arxiv.org/pdf/2312.17742.pdf
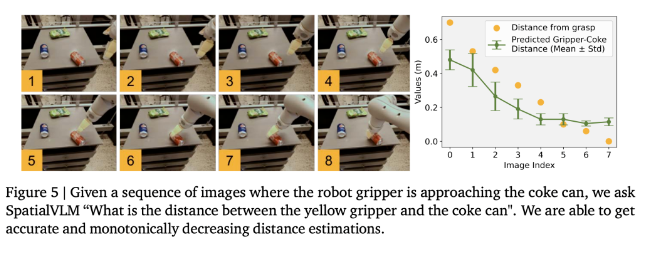
谷歌提出最新模型SpatialVLM :赋予视觉语言模型空间推理能力
划重点:🌐视觉语言模型(VLM)在空间推理方面存在困难,谷歌提出的SpatialVLM能够弥补这一不足。🚀通过生成大规模的空间VQA数据集,研究者训练了SpatialVLM,展现了显著的定性和定量空间推理能力。🤖SpatialVLM不仅在视觉领域有潜在应用,还能作为密集奖励注释器和执行链式思维推理的强大工具。站长网2024-02-18 14:46:340000从46款AI教育产品,看全球八大市场用户学习偏好
QuestionAI助力作业帮上市的传闻、字节跳动旗下Gauth超越多邻国登顶美国教育总榜、Answer.AI凭借个位数成员的小团队成为北美AI教育第一梯队产品,让市场看到了AI教育的机会。站长网2024-06-06 17:43:100002小米相册AI编辑上线「智能扩图」、「魔法消除Pro」等功能
今日,小米官方宣布小米相册AI编辑「智能扩图」、「魔法消除Pro」正式上线,预计在本月内全面覆盖小米14、小米14Pro以及RedmiK70系列手机,为用户带来更为智能与便捷的相册编辑体验。智能扩图功能,旨在解决用户在拍摄过程中可能遇到的构图问题。用户只需在相册编辑界面选择裁切旋转功能,然后点击智能扩图,系统便能自动对图片进行扩展和重新构图,让照片更具艺术感。站长网2024-03-14 17:14:050000谷歌之后,OpenAI也要给新闻网站付费了?
近两年,大模型喷涌,它们在文字、图片、音视频等内容形态的生成上大放异彩。内容创作一直认为是人“独属”的技能,自OpenAI于2022年发布ChatGPT之后,众多大模型开始挑战一直被人类把持的这一独特技能。从初期惊艳心态“祛魅”后,大众逐步了解了这个新生事物的“创作原理”。站长网2024-07-11 08:56:270000抖音成为全球最赚钱的APP
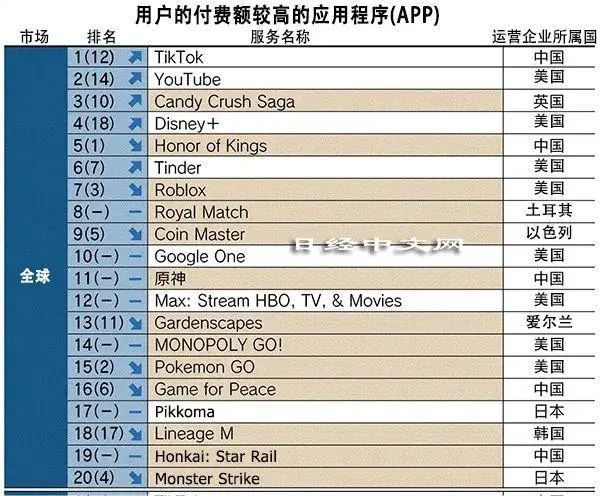
抖音用户付费额全球第一打开手机刷短视频已经成为大部分人日常生活中娱乐的首选,说起短视频,想到的无非就是抖音、快手两个软件。从诞生到现在,抖音几乎到了“无人不知,无人不晓”的地步。抖音拥有国民级别的知名度,其吸金能力也不可小觑。站长网2024-02-20 14:18:510001