谷歌提出最新模型SpatialVLM :赋予视觉语言模型空间推理能力
划重点:
🌐 视觉语言模型 (VLM) 在空间推理方面存在困难,谷歌提出的 SpatialVLM 能够弥补这一不足。
🚀 通过生成大规模的空间 VQA 数据集,研究者训练了 SpatialVLM,展现了显著的定性和定量空间推理能力。
🤖 SpatialVLM 不仅在视觉领域有潜在应用,还能作为密集奖励注释器和执行链式思维推理的强大工具。
谷歌最新论文揭示的 SpatialVLM,是一种具备空间推理能力的视觉语言模型,旨在解决当前视觉语言模型在空间推理方面的困难。视觉语言模型在图像描述、视觉问答等任务上取得显著进展,但在理解目标在三维空间中的位置或空间关系方面仍存在难题。
研究者通过生成大规模的空间视觉问答(VQA)数据集,利用计算机视觉模型提取目标为中心的背景信息,并采用基于模板的方法生成合理的 VQA 数据。经过训练,SpatialVLM表现出令人满意的能力,包括在回答定性和定量空间问题方面的显著提升。
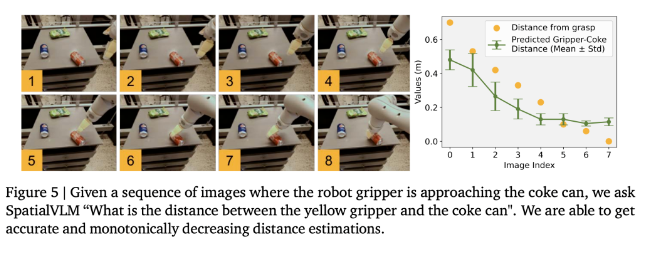
定性空间 VQA 方面,SpatialVLM在人工注释的答案和模型输出自由形式的自然语言中展现了高成功率。在定量空间 VQA 方面,模型在两个指标上表现优越,比基线模型更为出色。
研究者强调了数据的重要性,指出常见数据集的限制是当前视觉语言模型在空间推理上的瓶颈。他们专注于从现实世界数据中提取空间信息,通过生成大规模的空间 VQA 数据集,成功地提高了VLM的一般空间推理能力。
SpatialVLM不仅在视觉领域有应用潜力,还可以作为密集奖励注释器,用于机器人任务的奖励注释。此外,结合大型语言模型,SpatialVLM能够执行链式思维推理,解锁复杂问题的解决能力。
这一研究为视觉语言模型的空间推理能力提供了新的思路,为未来在机器人、图像识别等领域的发展带来了新的可能性。
论文地址:https://arxiv.org/pdf/2401.12168.pdf
项目入口:https://top.aibase.com/tool/spatialvlm
人工智能偏见暴露:亚洲女性头像变白
近日,一位亚裔女性在使用AI图像生成器时,发现该系统将她的头像改为白人。这位24岁的MIT毕业生RonaWang表示,PlaygroundAI编辑器让她的照片看起来更“专业”,但却将她的肤色改变为白色,从而改变了她的种族。站长网2023-08-02 15:43:090000粉丝数暴涨100倍,“恐龙扛狼”也扛流量
“我没K,我没K。布鲁biu,布鲁biu。恐龙扛狼扛狼扛,恐龙扛狼扛狼扛。恐龙扛狼扛狼扛,恐龙扛狼扛狼扛”。最近一段时间,这首被称为“恐龙扛狼”的洗脑神曲几乎席卷全网,并掀起了各路网友争相改编的热潮。截至目前,话题#恐龙扛狼、#恐龙抗狼在抖音上的视频总播放量已接近47亿。“恐龙扛狼”是如何诞生并且风靡网络的?站长网2023-08-11 17:47:490001B站赚钱不靠电商,靠电商平台?
提起唯品会,近期最深人心的场景莫过于——热播剧《玫瑰的故事》的中插广告。画面里朱珠穿着白色波点的法式上衣,身姿曼妙,眼光流转,说出了那句令人耳熟能详的广告词。去年《繁花》热播,唯品会也没有缺席植入,网友看到广告时猝不及防,还喊话王家卫,可否连中插广告一起拍摄。类似的事几乎每天都在发生,有现代剧的地方就会有唯品会,无论是大爆剧还是热门综艺,唯品会次次不落。站长网2024-07-11 08:56:280001今日冬至 微信上线吃饺子汤圆限定状态
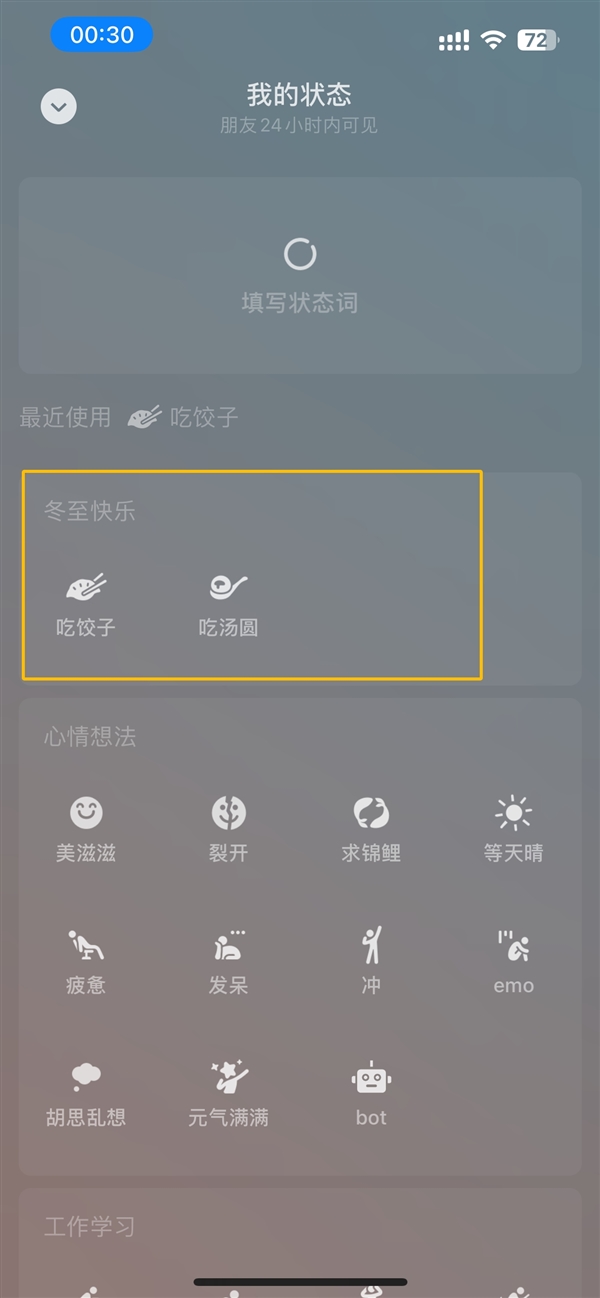
今天是二十四节气中的第22个节气——冬至。为了庆祝这个节日,微信上线了两个限定状态:“吃饺子”和“吃汤圆”。这两个状态可以在微信的“我”的界面点击“设个状态”进行设置。需要注意的是,由于是节日限定,这两个状态只能在今天设定,冬至过后将下线。据悉,微信状态是微信8.0后更新的一项功能,是原视频动态”功能的升级,可以在这里分享心情、上传图片、视频或音乐。站长网2023-12-22 10:48:070000亚马逊云科技:已全面突破企业应用生成式AI的三大挑战!
快科技1月7日消息,据媒体报道,近日,亚马逊云科技举办了2024re:Invent全球大会。在此次发布会上,亚马逊云科技全球客户技术支持与服务副总裁UwemUkpong指出:当前企业在应用生成式AI过程中,主要面临迁移上云、打破数据孤岛及应用场景聚焦三方面挑战。为解决这三大方面挑战,亚马逊云科技已经取得了全面突破。0000