ChatGPT越来越懒,都学会反过来PUA人类了
OpenAI 表示自11月11日以来,他们就没有更新过模型,模型行为是不可预测的,他们正在研究如何修复。
不知你有没有注意到,最近一段时间,GPT-4变得有些「懒惰」,现在的它,老是拒绝执行某些任务或直接返回简化的结果。
这个问题得到很多网友的共鸣,纷纷开始抱怨 ChatGPT 变「懒惰」这个事实。
用户声称,最近使用 GPT-4或 ChatGPT API 时,在高峰时段响应变得非常缓慢且敷衍。在某些情况下,它会拒绝回答,而在另一些情况下,如果出现一系列问题,对话就会中断。
据报道,如果用户请求 GPT-4写一段代码,会出现上述问题。它可能只提供一些信息,然后指导用户填写其余部分。有时, GPT-4会告诉人们「你可以自己做这件事 」。
GPT-4变「懒惰」一些示例展示
「GPT 确实变得更加抗拒做乏味的工作。本质上是给你部分答案,然后告诉你做剩下的事情。不敢想象,当你运行查询时,你的数据库只读取了前10行的信息。」专注于销售和营销的 Summit 创始人 Matthew Wensing 抱怨道。
「让它扩展一些代码,生成的代码要求达到50行,它让我自己去做。」
有时 ChatGPT 受够了网友的请求,最后直接来了个「白眼」,让你自己体会。
「现在的 ChatGPT 无法帮助用户处理代码脚本。」
沃顿商学院 Ethan Mollick 教授将 GPT-4在7月和现在的表现进行了对比,他得出的结论是:GPT-4仍然是知识渊博的,但也存在懒惰这个问题,GPT-4非常乐意向用户解释如何修复代码,而不是实际修复代码。
随后, Mollick 教授表示,「同样,我们没有证据表明 GPT-4以任何方式变得更加愚蠢,这可能是系统负载的暂时问题(例如 openAI 现在将 DALL-E3的图片响应从4张减少到1张),但在以下方面GPT-4肯定存在行为变化:系统在没有刺激的情况下愿意做多少事情。」
不仅 X,Reddit 上也到处是讨论的帖子,最近一则名为《ChatGPT 已经变得非常懒惰》的帖子爆火。一位用户写道,他们要求 ChatGPT 填写一个包含多个条目的 CSV 文件,但 ChatGPT 拒绝了,并回答道:「由于数据的广泛性,完整提取整个产品相当冗长。但是,我可以提供包含此单个条目作为模板的文件,您可以根据需要填写其余数据。」
对于这一回答,发帖人直接发飙了:「这就是人工智能应该有的样子吗?一个专横的懒惰机器人,让我自己去做?」
鉴于 ChatGPT 现在的表现,网友开始纷纷怀念以前的 GPT-4了。
OpenAI 承认了,但不确定是什么原因造成的
有些人开始猜测是因为 OpenAI 合并模型、同时运行 GPT-4和 GPT-4Turbo 导致服务器持续过载、公司试图通过限制结果来节省资金等造成的。
众所周知,OpenAI 的运营成本极其昂贵,今年4月,研究人员表示,每天需要花费70万美元,即每次查询花费36美分,才能维持 ChatGPT 的运行。根据行业分析师当时的说法,OpenAI 必须将其 GPU 群扩大至30000台,才能在今年剩余时间内保持其商业性能。除了为其所有合作伙伴提供计算之外,OpenAI 还需要支持 ChatGPT 其他流程。
对于这个问题,ChatGPT 官方账户发布了推文,OpenAI 承认了这个问题,但不确定是什么原因造成的。「我们已收到您关于 GPT4变得更加懒惰的所有反馈!自11月11日以来我们就没有更新过模型,这当然不是故意的。模型行为可能是不可预测的,我们正在研究修复它。」
简而言之,OpenAI 表示他们最近没有对 ChatGPT 或 GPT-4进行任何会使其变得更加懒惰的更改。事实上,自11月11日以来,没有任何变化。但他们解释说,模型本身「可能是不可预测的」,他们正在寻求解决的问题。
12月初,OpenAI 员工 Will Depue 在 X 中也证实了,OpenAI 已注意到有关 ChatGPT 变懒惰的报告,正在研究潜在的修复方案。
从他的回答中我们可以看出 ChatGPT 确实存在过度拒绝用户问题以及其他奇怪的行为(例如最近的懒惰问题),但这些都是不断服务和尝试支持众多用例过程中的迭代产物。他指出,当 ChatGPT 的某些部分显著改进时,这些改进通常不会被广泛注意到。相反,当模型的某些部分偶尔出现退化时,这些问题就会变得非常明显。尽管存在一些问题,如过度拒绝和偶尔的性能退化,但这些都是改进过程中的一部分。OpenAI 鼓励提供具体反馈以帮助快速解决这些问题。
在等待 GPT-4性能稳定的同时,用户们互相打趣,「接下来你就会知道它会『请病假』。」
中国科学院团队首篇LLM模型压缩综述:细聊剪枝、知识蒸馏、量化技术
随着LLM的突破性工作逐渐放缓,对于如何让更多人使用LLM成为时下热门的研究方向,模型压缩可能是LLM未来的一个出路。此前OpenAI首席科学家IlyaSutskever表示可以通过压缩的视角来看待无监督学习。本文首次总结了关于LLM的四种模型压缩方法,并提出了未来进一步研究的可能方向,引人深思。站长网2023-08-27 13:43:0500011谷歌集成 AI 搜索体验被指反应太慢 查询结果加载时间过长
日前TheVerge对谷歌的新AI搜索体验进行了一番评测。TheVerge表示,谷歌的新AI搜索体验最糟糕的一点就是等待的时间太长了。对于普通用户来说,搜索结果通常是瞬间出现的。你在搜索框中输入内容,谷歌几乎立即给出答案,然后你可以点击链接了解更多相关信息,或者在搜索框中输入其他内容。这是一个有益的良性循环,使谷歌搜索成为全球访问量最大的网站。站长网2023-06-05 21:29:300000魅族21系列推出Flyme 10.5系统:语音助手接入AI大模型
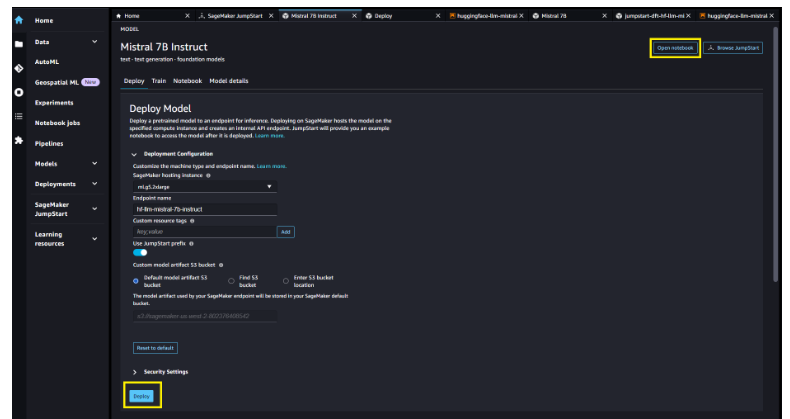
魅族21系列最新推出了Flyme10.5.0.1A稳定版系统,此次更新的语音助手接入了AI大模型,用户可以在使用魅族21系列手机时进行体验。以下是本次系统更新的主要内容:1.语音助手小溪接入了AI大模型,支持自然语言对话、文档总结、知识问答、出行规划、运动健康建议、文案生成等AI功能。0000亚马逊机器学习团队推出 Mistral 7B 基础模型 支持8000个token上下文长度
文章概要:-Mistral7B是MistralAI开发的英文文本和代码生成基础模型,参数规模70亿。-SageMakerJumpStart提供一键部署Mistral7B进行推理,可快速自定义。-Mistral7B具有8000个token的上下文长度,表现低延迟和高吞吐量。站长网2023-10-10 10:06:040000种草不回流,电商部和市场部battle怎么办?
内容种草,到底有没有效果?效果到底如何,一直是个迷。不少品牌尝试后,效果一般。那内容种草,市场部做了大曝光,电商部说店铺没有回流,怎么办呢?先分享个案例:站长网2023-08-02 13:59:380000