在不降低LLM质量的情况下降低GPU内存成本
FastGen:在不降低LLM质量的情况下降低GPU内存成本
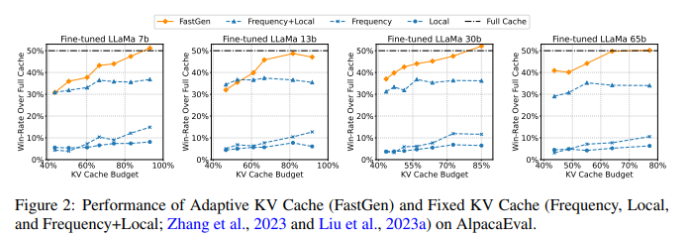
划重点:-⭐FastGen一种高效的技术,可以提高LLM的推理效率,而不会降低可见质量。-⭐FastGen轻量级模型分析和自适应键值缓存来实现。-⭐FastGen通过自适应的键值缓存构造来少生成推理过程中的GPU内存使用量。站长网2024-05-13 11:04:000000

热点
对于那些出来卖的DeepSeek课程,我有些话想说。
2025-02-11 18:23:40抖音、小红书“反精致”崛起,为何粗糙真实更得人心?
2025-02-12 10:27:31Le Chat登顶、千亿美元投资,中美之后,AI第三强国?
2025-02-11 09:56:00苹果iOS 18.3.1正式版发布 修复重大漏洞
2025-02-11 09:48:44DeepSeek的冲击波,撞开了AI生态之争的大门
2025-02-11 06:03:26一块冰箱贴,如何被卷成了大生意?
2025-02-11 04:30:24DeepSeek上线国家超算平台!671B满血版,三大运营商接入,平头哥芯片适配
2025-02-11 04:28:09DeepSeek的华丽文风是怎样炼成的?
2025-02-11 04:23:04中国电信A股涨停股价创历史新高 此前三大运营商接入DeepSeek
2025-02-11 04:20:17苹果独立AR眼镜计划不变!只是需要更长时间
2025-02-11 03:55:15
关注
《哪吒2》登顶,谁赚麻了?
2025-02-07 15:41:39
AI玩具正在批量制造“赛博父母”:2025年这个万亿赛道藏着多少机会?
2025-02-07 00:12:18雷军去小米汽车工厂上班了:确认要进一步提产 冲击年销30万辆
2025-02-07 15:06:26
QQ邮箱尝鲜上线华为原生鸿蒙 支持QQ和微信登陆、多账号管理
2025-02-07 00:08:01小米眼镜官博上线 旗下首款AI眼镜将发布
2025-02-07 10:20:34春节回了苏北老家,我发现谷子店已开遍天下
2025-02-07 00:06:12
模型优惠进入倒计时 DeepSeek因服务器暂停API服务充值
2025-02-07 03:18:386款产品总流水过亿、出海厂商上榜,谁在领跑混合休闲赛道?
2025-02-07 00:05:41
小米眼镜官微上线:智能眼镜赛道要爆发
2025-02-07 02:59:11
2025年,短剧换种方式“收钱”
2025-02-07 00:00:30
