FastGen:在不降低LLM质量的情况下降低GPU内存成本
划重点:
- ⭐FastGen 一种高效的技术,可以提高 LLM 的推理效率,而不会降低可见质量。
- ⭐FastGen 轻量级模型分析和自适应键值缓存来实现。
- ⭐FastGen 通过自适应的键值缓存构造来少生成推理过程中的 GPU 内存使用量。
研究人员来自伊利诺伊大学厄巴纳 - 香槟分校和微软提出了一种名为 FastGen 的高效技术,通过使用轻量级模型分析和自适应键值缓来提高 LLM 的推理效率,而不会降低可见质量。FastGen 通过自适应的键值缓存构造来减少生成推理过程中的 GPU 内存使用量。
FastGen 的自适应键值缓存压缩方法减小了 LLM 生成推理内存占用。该方法涉及两个步骤:
1. 提示编码:注意模块需要从前面的 i-1标记中收集上下文信息,以生成 LLM 的第 i 个标记。
2. 令牌生成:当完成提示编码后,M 逐个标记生成输出,对于每个步骤,使用 LLM 对上一步生成的新标记进行编码。
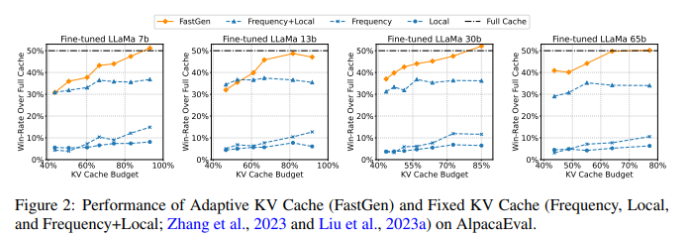
对于 B 模型,FastGen 在所有非自适应键值缓存压缩方法中表现最佳,并随着模型规模的增加而得更高的键值缓存压缩比例,同时保持模型的质量不受影响。例如,与 Llama17B 上的16.9% 压缩比例相比,FastGen 在 Llama1-65B 上获得了44.9% 的缩比例,达到了45% 的胜率。此外,对 FastGen 进行了敏感性分析,选择了不同的超。由于模型保持45% 的胜率,研究表明在更改超参数后对生成质量没有明显影响。
伊利诺伊大学厄巴纳 - 香槟分校和微软的研究人员提出了 FastGen,一种新的技,通过使用轻量级模型分析和自适应键值缓存来提高 LLM 的推理效率,而不会降低见质量。研究人员引入的自适应键值缓存压缩通过 FastGen 构建,以减少 LLM 生成推的内存占用。未来的工作包括将 FastGen 与其他模型压缩方法(如量化和蒸馏、分组查询注意等)进行整合。
论文地址:https://arxiv.org/abs/2310.01801
领英中国:9年本土化探索,化作一场漫长的告别
5月9日,享誉全球的职场社交平台领英(LinkedIn)宣布调整中国业务战略,中国本土化求职APP“领英职场”将于2023年8月9日起正式停服,届时,将删除“领英职场”内所有的个人账号数据。领英CEO瑞恩·罗斯兰斯基在内部信中表示,将会停止在中国设立产品和工程团队,以及缩减职能、业务和营销的岗位,此次调整将导致多个岗位的裁撤。站长网2023-05-12 11:43:020002Adobe确认明年起逐步关闭Creative Cloud文件同步
近日,Adobe公司发出通知,宣布将在2023年关闭旗下CreativeCloud文件的自动同步功能。站长网2023-09-04 10:43:420000周鸿祎回应睡觉被雷军瞪:着急要不要叫醒自己
360集团董事长周鸿祎最近发布了一段视频,回应了一张在网络上广泛传播的照片。照片中显示他在一次会议上睡觉,而雷军则在旁边注视着他。周鸿祎解释说,这张照片拍摄于2015年乌镇世界互联网大会期间。他回忆称,前一天晚上他参加了丁磊的家宴并喝了酒,结果第二天非常困倦。在当天下午的会议上,他和雷军都安排了发言。由于前面的演讲者拖堂,他在等待期间不小心睡着了。站长网2024-07-26 17:58:080000波音公司正利用 AI 从庞大的数据中剔除安全隐患
波音公司正在利用人工智能来筛选海量的数据,并识别其飞机和航空公司运营中的潜在危险,以加强它在两起致命的737Max坠机事件之后试图增加的安全文化。站长网2023-05-25 15:41:490000思科调查:印度仅有26% 的组织准备好部署人工智能
划重点:🔍只有26%的印度组织完全准备好部署和利用人工智能技术。🔍在印度,32%的公司被认为是"落后者"(未准备好)或"追随者"(准备有限)。🔍95%的印度企业认为他们最多只有一年的时间来实施人工智能战略,否则将会遭受严重的负面影响。站长网2023-11-17 18:12:190000














