苹果芯跑大模型不用降计算精度,投机采样杀疯了,GPT-4也在用
专攻代码的Code Llama一出,大家伙都盼着谁来后续量化瘦身一下,好在本地也能运行。
果然是llama.cpp作者Georgi Gerganov出手了,但他这回不按套路出牌:
不量化,就用FP16精度也让34B的Code LLama跑在苹果电脑上,推理速度超过每秒20个token。
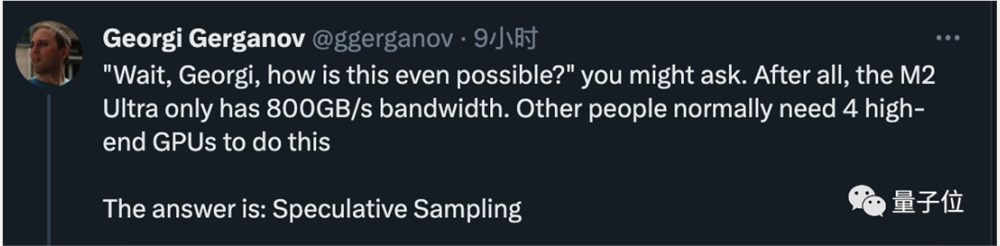
原本需要4个高端GPU才能搞定的活现在用只有800GB/s带宽的M2Ultra就够了,代码写起来嗖嗖快。
老哥随后公布了秘诀,答案很简单,就是投机采样(speculative sampling/decoding)。
此举引来众多大佬围观。
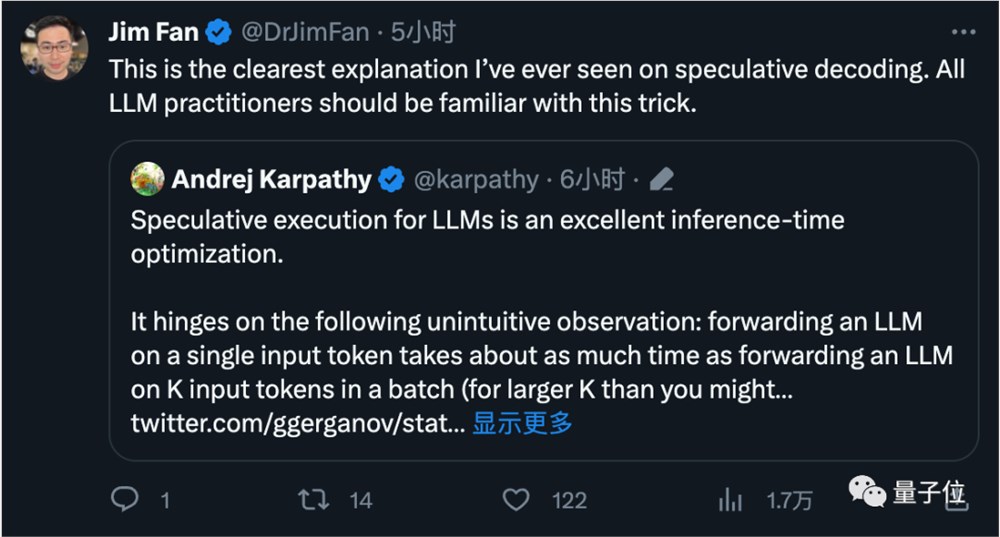
OpenAI创始成员Andrej Karpathy评价这是一种非常出色的推理时优化,并给出了更多技术解读。
英伟达科学家范麟熙也认为,这是每个大模型从业者都应该熟悉的技巧。
GPT-4也在用的方法
其实不光想在本地跑大模型的人在用投机采样,谷歌OpenAI这样的超级巨头也在用。
根据之前泄露的资料,GPT-4就用了这个方法来降低推理成本,不然根本承受不起这么烧钱。

而最新爆料表示谷歌DeepMind联手开发的下一代大模型Gemini很可能也会用。
虽然OpenAI的具体方法都保密,但谷歌团队已经把论文发出来了,并且入选ICML2023Oral。

方法很简单,先训练一个与大模型近似、更便宜的小模型,让小模型先生成K个token,然后让大模型去做评判。
大模型接受的部分就可以直接用,大模型不接受的部分再由大模型修改。
在原始论文中使用T5-XXL模型演示,在生成结果不变的情况下获得了2-3倍的推理加速。

Andjrey Karpathy把这个方法比喻成“先让小模型打草稿”。
他解释这个方法有效的关键之处在于,给大模型一次输入一个token和一次输入一批token,预测下一个token所需时间是差不多的。
但每一个token都依赖前一个token,所以正常情况无法一次对多个token进行采样。
小模型虽然能力较差,但实际生成一个句子时有很多部分是非常简单的,小模型也能胜任,只有遇到困难的部分再让大模型上就好了。
原论文认为,这样做无需改变大模型的结构,也无需重新训练,就可以直接加速已有的现成模型。
对于不会降低精度这一点,在论文附录部分也给出了数学论证。

了解了原理,再来看Georgi Gerganov这次的具体设置。
他使用4bit量化的7B模型作为“草稿”模型,每秒约能生成80个token。
而FP16精度的34B模型单独使用每秒只能生成10个token。
使用投机采样方法后获得了2倍的加速,与原论文数据相符。

他额外表示,速度可能会根据生成的内容而有所不同,但在代码生成上非常有效,草稿模型能猜对大多数token。
最后,他还建议Meta以后在发布模型时直接把小的草稿模型附带上吧,受到大伙好评。

作者已创业
作者Georgi Gerganov,今年三月LlaMA刚出一代的时候就移植到了C 上,开源项目llama.cpp获星已接近4万。

最开始他搞这个只是当成一个业余兴趣,但因为反响热烈,6月份他直接宣布创业。
新公司ggml.ai,主打llama.cpp背后的C语言机器学习框架,致力于在边缘设备上运行AI。

创业时获得来自GitHub前CEONat Friedman、Y Combinator合伙人Daniel Gross的种子前投资。
LlaMA2发布后他也很活跃,最狠的一次直接把大模型塞进了浏览器里。

谷歌投机采样论文:
https://arxiv.org/abs/2211.17192
参考链接:
[1]https://x.com/ggerganov/status/1697262700165013689
[2]https://x.com/karpathy/status/1697318534555336961
英国计划将AI芯片和超级计算机支出增至4亿英镑
🔍划重点:1.英国政府将增加AI芯片和超级计算机的支出,以提高英国的技术实力。2.英国财政大臣RishiSunak计划创建“AI研究资源”并在剑桥启用新设施,同时提高布里斯托尔的设备水平。3.英国政府希望通过国际研究网络的协议,将英国定位为AI技术的全球中心,并加强安全开发和使用AI技术的研究。站长网2023-10-30 11:49:250001腾讯汤道生:大模型只是起点 应用落地是更大的图景
在今日的“企业管理者人工智能通识课”上,腾讯集团高级执行副总裁、云与智慧产业事业群CEO汤道生表示,在大模型具体实施中,模型、数据和算力是大家需要格外关注的三个点。站长网2023-06-22 11:06:460000Runway和Getty合作开发新生成式AI视频模型RGM 瞄准好莱坞和广告行业
要点:RunwayML与GettyImages合作开发新的生成式AI视频模型,命名为RunwayGettyImagesModel(RGM),旨在服务好莱坞和广告行业。RGM将为企业提供基础模型,允许其使用自有专有数据集进行微调,以增强创意能力,为不同领域的企业提供定制化视频生成工作流。站长网2023-12-05 10:37:230000天猫向家装家电商家提供免费AI工具:千牛上线“家作”功能
在解决家装家电行业商家经营创作所面临的挑战方面,天猫近期采取了一系列创新举措。4月26日,天猫宣布面向全平台家装家居家电商家免费开放AIGC和3D技术,推出了包括3D互动展厅、AI虚拟棚拍、AI模特以及AI扩图在内的四大功能,旨在帮助商家实现降本增效的目标。站长网2024-04-28 16:57:240000Canalys:第一季度中国个人电脑市场出货下降24%
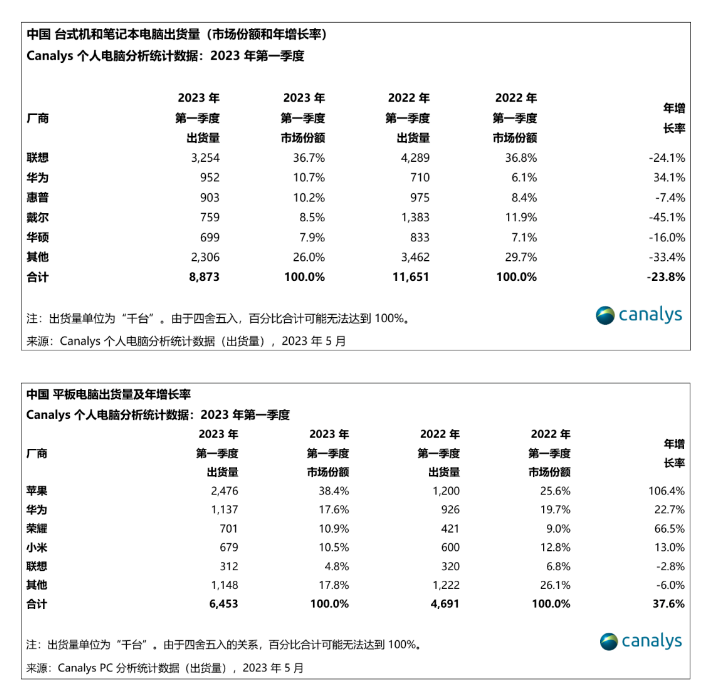
Canalys发布报告称,2023年第一季度,中国大陆个人电脑(台式机、笔记本和工作站)出货量同比下降24%至890万台。台式机(包括台式工作站)出货量下降28%至280万台,笔记本电脑(包括移动工作站)出货量下降22%至610万台。平板电脑出货逆势上扬,总出货量同比增长38%至650万台。站长网2023-05-24 09:24:340000