研究:GPT-4 在执行多项现实任务中击败其他大语言模型
本文概要:
1. GPT-4在大型语言模型中表现出色,取得最高总分4.41。
2. GPT-4在几乎所有领域都领先于其他模型,只有在网购任务中,GPT-3.5表现更好。
3. 开源模型整体表现不佳,远远落后于商业模型和 GPT-3.5。
市面上已经有有许多商业和开源的文本生成人工智能。现在专门为测试辅助任务开发的基准测试表明,GPT-4在这一领域脱颖而出。
最新的研究显示,在 “现实世界语用任务” 中,GPT-4在大型语言模型中表现出色。研究团队使用一个名为 “AgentBench” 的基准测试对多个提供商的25个大型语言模型以及开源模型进行了测试。
“AgentBench”是专门为衡量大语言模型在“现实世界语用任务”中的辅助能力而设计的标准化测试。所有测试均在实时交互环境中进行。这使得该基准特别适合其想要测量的内容:大型语言模型处理总共八个领域的各种日常任务的能力。
操作系统:LLM必须执行与计算机操作系统的使用相关的任务。
数据库:这个环境是关于LLM如何与数据库合作。
知识图:此环境测试LLM如何使用知识图。
数字卡牌游戏:这测试了LLM对数字卡牌游戏和制定策略的理解程度。
横向思维难题:此挑战测试法学硕士在解决问题时的创造力。这要求他们跳出框框思考。
预算:此场景涉及基于 Alfworld 数据集的预算中发生的任务。
互联网购物:此场景测试LLM在与在线购物相关的任务上的表现。
网页浏览:基于 Mind2Web 数据集,此场景测试LLM执行与使用互联网相关的任务的能力。
结果显示,GPT-4以最高总分4.41领先于其他模型,在几乎所有领域都表现出色,只在网购任务中稍逊于 GPT-3.5。
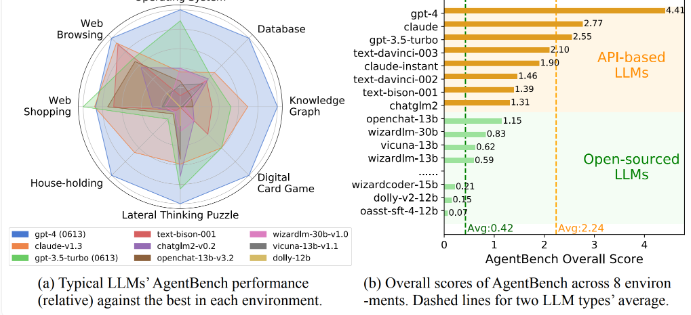
竞争对手 Anthropic 的 Claude 模型紧随其后,总得分为2.77,领先于 OpenAI 的免费 GPT-3.5Turbo 模型。商业模型的平均得分为2.24。与开源模型相比,GPT-4的优势更加明显,开源模型的平均得分只有0.42。
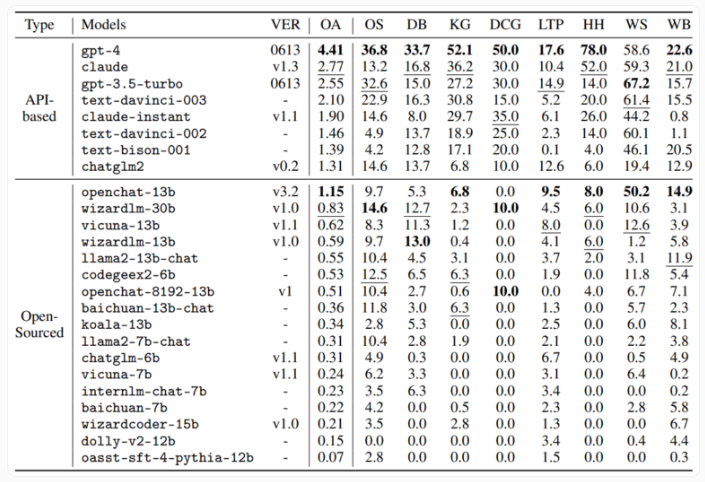
研究人员指出,开源模型在所有复杂任务中普遍表现不佳,远远落后于 GPT-3.5。研究团队将工具包、数据集和基准测试环境提供给研究界,以便进行更广泛的性能比较。
网红偷税、炫富惨遭封杀,又一个大V倒下了
百万粉网红柏公子偷税被罚超1330万在网红经济时代,被推向流量神坛的头部主播们成为了互联网第一批吃螃蟹的人。直到现在,主播们随便一场直播,GMV规模动辄就达千万甚至1亿、个人收入达百万,这也不是什么稀罕事。就如带货一姐薇娅曾心直口快地表示,“当明星哪有当主播赚钱”。与此同时,带货主播们的税收也成为网友们关切的事情,尽管此前已有不少主播倒在了税收问题上,似乎有些主播还存在侥幸心理。站长网2024-12-19 14:07:000000AI换装MagicClothing: 专注实现可控的换装效果
MagicClothing是一个AI换装项目,该研究是基于OOTDiffusion的一个分支版本,专注于实现可控制服装驱动的图像合成。MagicClothing的特色功能包括:可控服装驱动图像合成,MagicClothing专注于实现可控服装驱动的图像合成,用户可以通过调整服装和文本提示的强度来控制合成图像的效果。这种可控性使得用户能够根据需要定制图像内容,实现个性化的图像合成。站长网2024-04-18 21:55:500000你在热议大妈云栖大会招女婿的时候,已经上了营销的当
今天阿里云栖大会,算科技圈的一个盛会,但很多人知道它,是因为一组照片。这组照片的内容是:几个老奶奶,站在云溪大会入口处附近,高举招女婿的牌。内容也很奇葩,分别是:第一则:题目:《招AI贤婿》93年独生女,萧山人,云栖大会寻缘,诚觅AI大模型程序员。第二则:题目:《招赘婿》站长网2023-11-01 09:06:410000两00后为面子租iPhone14不还被起诉:后达成分期还款计划
近日,吉安市中级人民法院发布消息,泰和县法院沙村法庭成功调解了两起租赁手机合同纠纷案。据了解,2023年4月,戴某和郭某在泰和县某租赁公司租赁了两台iPhone14Promax。他们与租赁公司签订了手机租赁服务合同,租期分别为3个月和2个月。然而,戴某和郭某未按约定支付租金,并在租赁期限届满后未能归还租赁物。站长网2024-01-25 14:41:010000羊驼进化成鲸鱼,Meta把对齐「自动化」,Humpback击败现有全部LLaMa模型
数据质量很重要。这一年来,以ChatGPT和GPT-4为代表的大语言模型(LLM)发展迅速,紧随其后,Meta开源的LLaMa、Llama2系列模型在AI界也引起的了不小的轰动。但随之而来的是争议不断,有人认为LLM存在一些不可控的风险,给人类生存构成一些潜在威胁。站长网2023-08-16 14:12:580000