gpt crawler:从URL爬取网站生成结构化知识,创建定制GPT
gpt crawler是一款强大的工具,能够将网站内容全面地爬取下来,并将其转换成结构化知识,为GPTs的学习提供了有力支持。
这个工具的应用场景广泛,比如,如果你想打造一个数字人分身,可以先将自己在社交媒体或个人博客上的内容抓取下来,然后提交给ChatGPT作为储备知识。这种方式不仅能够保存个人在网络上的言论和观点,还可以为ChatGPT提供更多的学习材料,使其更好地理解和模拟用户的语言风格和思维方式。
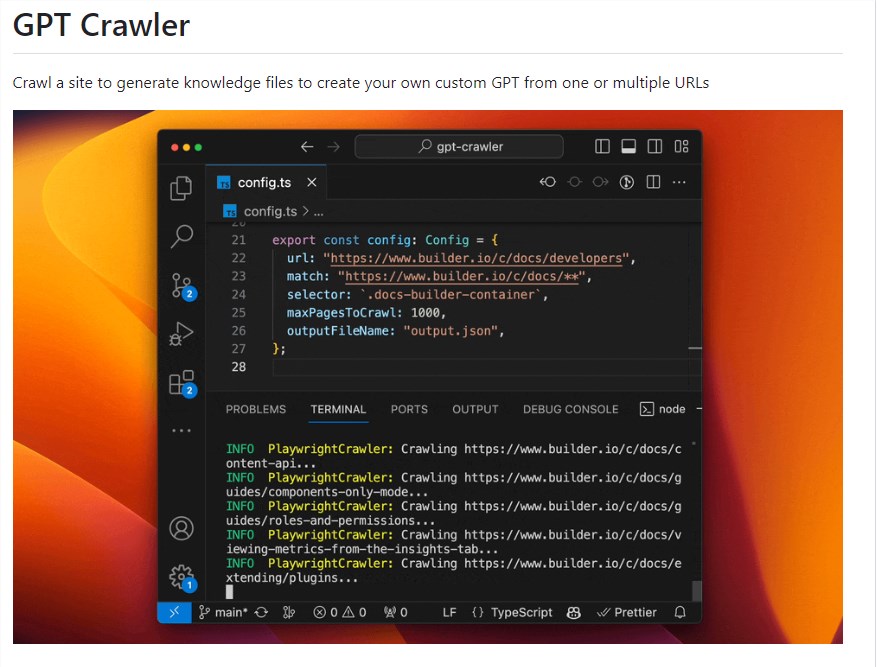
项目地址:https://github.com/BuilderIO/gpt-crawler
核心功能:
灵活配置爬虫: 用户可以通过编辑config.ts文件中的URL、选择器等属性,灵活配置爬虫以适应不同的网站结构和需求。
定制化知识文件生成: gpt-crawler通过爬取指定网站的内容,生成包含知识数据的文件(output.json),为用户提供定制GPT所需的基础知识。
轻松上传到OpenAI: 生成的知识文件可以方便地上传至OpenAI,支持用户在UI界面或通过API访问生成的知识,用于创建自定义GPT或助手。
支持Docker容器化执行: 通过容器化执行,用户可以获得output.json,使整个过程更加灵活和可扩展。
贡献和改进: 项目鼓励用户参与贡献,通过提出Pull Request等方式改进工具,使其更加强大和适应更多场景。
据了解,gpt crawler背后采用了先进的技术框架crawlee。Crawlee不仅是一个高效的网络爬虫工具,还是一款强大的浏览器自动化工具。在实现上,它提供了多项关键功能,包括DOM解析能力、无头浏览器模式、异常状态码处理、队列和存储等。这些功能的综合运用使得爬虫更加灵活和强大。此外,Crawlee还提供了大量的配置项,用户可以根据自己的需求进行灵活设置,从而更好地适应不同的爬取任务。
时隔3年正式回归连更2条作品 李子柒:还有存货正在剪
时隔三年之久,网红李子柒正式宣告复出,于今日在各大平台更新视频。李子柒上传了酝酿四年的“大漆”视频和“森林衣帽间”视频,并配文表示:“大漆视频迟到了四年,真的很想念大家”。网友留言询问:“是不是积累了很多存货?”李子柒回复称:“再稍等一下,我还在剪辑!”并附上了一张视频剪辑的图片。在最新视频中,李子柒以中国非物质文化遗产漆器为主题,展示了漆器的独特美学和工艺之美。站长网2024-11-17 10:40:490000均价破万!AI让PC快成了奢侈品
快科技4月24日消息,随着ChatGPT等AI技术的快速发展,大模型的部署正在从云端向设备下沉扩散,用户常用的PC和手机就成了最主要的载体。联想CEO杨元庆表示,受算力等因素的影响,目前运行AI智能体最好的载体还是PC。不仅是联想,全球主流PC厂商、涉及PC业务的手机厂商,都把AIPC当做了不可错过的机会。0001小米:618全渠道支付金额破200亿元
站长之家(ChinaZ.com)6月14日消息:今日小米公司宣布,截至6月14日中午12点,其618购物节的全渠道支付金额已经突破了200亿元大关,这一数字不仅刷新了小米历年618大促的纪录,更彰显了其市场影响力和消费者对其产品的高度认可。站长网2024-06-14 23:51:020000聆心智能开源定制角色对话交互模型CharacterGLM-6B
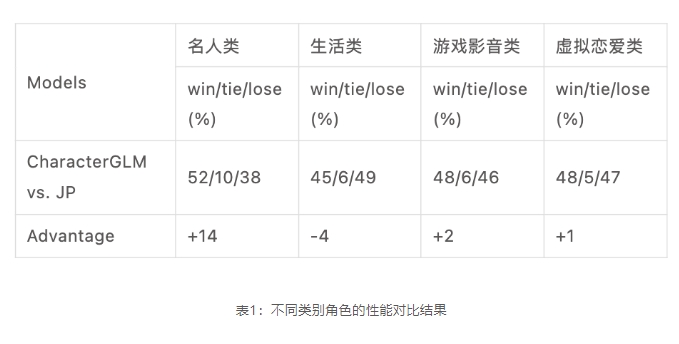
聆心智能发布了一个名为CharacterGLM的模型,用于定制化角色进行对话交互。这个模型基于ChatGLM模型,有6B、12B和66B三个不同参数量的版本。聆心智能将开放12B和66B模型的API访问,并开源CharacterGLM-6B模型,以促进AI角色扮演和AI在心理学中的应用。站长网2023-09-26 08:30:100006OpenAI 不希望 GPT-4 被滥用于面部识别
据《纽约时报》报道,OpenAI目前掩盖了图像中的人脸,并且不允许GPT-4通过图像识别来处理它们。这对盲人影响很大,他们在“BeMyEyes”实验中使用具有图像增强功能的GPT-4来获得环境和人的详细描述。对环境的描述仍然可用,但对人物的描述最近已被禁用,并且图像上的面孔变得模糊。站长网2023-07-20 12:59:260002