斯坦福大学:大模型“卷”错方向了?上下文窗口越长,模型越笨
在语言模型中,上下文窗口对于理解和生成与特定上下文相关的文本至关重要。
一般而言较大的上下文窗口可以提供更丰富的语义信息、消除歧义。
由于硬件和算法的最新进步,大模型的上下文窗口的长度也越来越“卷”。
其中的卷王当属Anthropic公司,其五月份就将 Claude 的上下文窗口从9k token扩展到了100k。
最近更新的Claude2更是让其100K的上下文能力“常驻”模型。

有大模型“风向标”之称ChatGPT也在三月份将GPT-4模型最大上下文窗口达扩至32K;六月份将GPT-3.5-Turbo增加了16k的上下文长度(此前是4k)。

而斯坦福大学联合加州伯克利大学以及Samaya的研究员, 在一篇题为“中途迷失:语言模型的长·上下文利用之道”中提出: 在多文档问题回答和键值检索,这两种都需要从输入的上下文中识别相关信息的任务中,大语言模型会随着输入上下文的长度增加,性能会显著下降。
具体而言,作者指出当相关信息出现在输入上下文的开头或结尾时,性能通常最好,但当模型需要在长篇上下文的中间获取相关信息时,性能明显降低。
换句话说:当带有答案的文字,被放在文章的中间时候,大语言模型可能无法准确识别、理解该答案。
因此,大模型目前越来越卷的上下文窗口长度,可能并不能增加模型的理解能力。

值得一提的是,知名科技媒体网站VentureBeat也报道了这篇论文,并咨询了一些专家,表示,向量数据库可能是破局的关键。
Vector databases like Pinecone help developers increase LLM memory by searching for relevant information to pull into the context window.
这一说法也得到了上述论文的关键作者“Nelson Liu”的认可,他表示:如果将整个 PDF 放到语言模型上下文窗口中,然后询问有关该文档的问题,那么使用向量数据库搜索通常会更有效。
同时Nelson Liu也提到这篇论文并不是在说将整篇文档塞进大模型的上下文窗口,就一定表现不好。其实,结果取决于文档所包含的具体内容,大模型在区分“关系密切的内容”时,表现不佳。当各部分内容不相关(相互独立)的时候,大模型非常擅长“准确定位”。
编者注:向量数据库的核心思想是将文本转换成向量,然后将向量存储在数据库中,当用户输入问题时,将问题转换成向量,然后在数据库中搜索最相似的向量和上下文,最后将文本返回给用户。
论文细节
论文对开源和非开源的模型都进行了测验,前者包括MPT-30B-Instruct,LongChat-13B(16K);后者包括OpenAI的GPT-3.5-Turbo和Anthropic的Claude。
首先进行了多文档问题回答的实验。该任务的目标是让模型对文档进行推理,找到并使用相关信息来回答给定的问题。
在实验中,对输入上下文的大小以及输入上下文中的相关信息位置进行了有控制的调整。
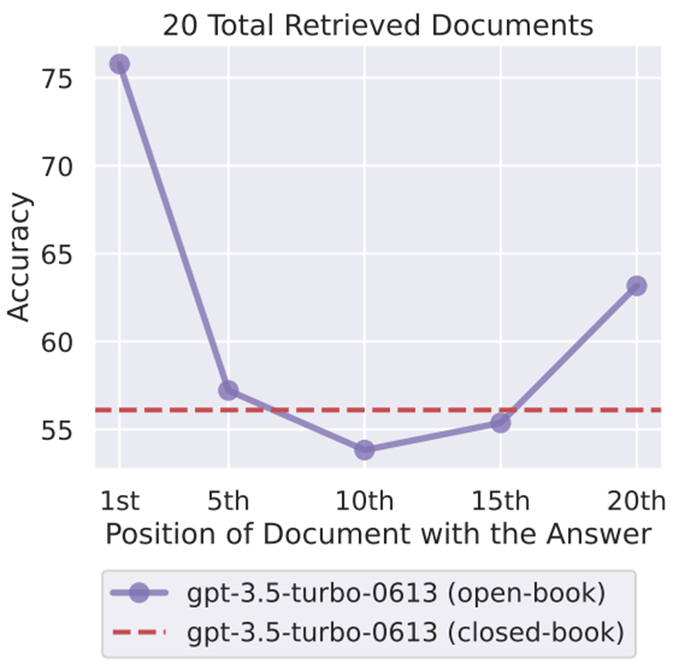
如上图所示,当改变相关信息在文档中的位置时,模型性能呈现独特的U形趋势,即当相关信息出现在输入上下文的开头或结尾时,性能通常最好;当模型需要在长篇上下文的中间获取相关信息时,性能明显最低。
甚至,在相关信息被放在输入上下文的中间位置时,GPT-3.5-Turbo在多文档问题回答任务上的表现不如别提供文档。
此外,一些号称专门处理长文本的大模型,在这方面表现也不好。
那么,语言模型有多大程度上能从输入上下文中检索信息呢?论文作者指定了一个合成的键值检索任务来探索该问题。
在这个任务中,模型需要处理一组JSON格式的键值对,并必须返回与特定键相关联的值。类似于多文档问题回答任务,键值检索任务在操作过程中,也对输入上下文的大小以及输入上下文中的相关信息位置进行了有控制的调整。
结果显示:仍然是U形性能曲线。
多文档问答
多文档问答任务在很大程度上类似于商业搜索和问答应用(例如,Bing Chat)所采用的检索增强生成模式。
在这些实验中,模型的输入是一个需要回答的问题,以及k篇文档(例如,来自维基百科的段落),其中一篇文档包含了问题的答案,而剩下的k-1篇“干扰”文档则没有。

如上图所示,要执行多文档问答任务,模型需要在输入的上下文中获取包含答案的文档,并用它来回答问题。
具体测验中,作者利用NaturalQuestions基准测试的数据,创建了这一任务的实例。其中,使用的查询来自于NaturalQuestions-Open,并从维基百科抽取段落(即不超过100个Token的文本块)作为输入上下文中的文档。
对于所有这些查询,需要找到一份包含答案的文档,并找到k -1份没有答案的文档作为干扰项。前者作者采用NaturalQuestions注释中含有答案的维基百科段落;后者采用了Contriever检索系统找出那些最与问题相关,但并未包含任何NaturalQuestions标注答案的k -1个维基百科片段。
最后,将准确度作为主要的评价标准,以此来判断预测输出中是否出现了正确的答案。
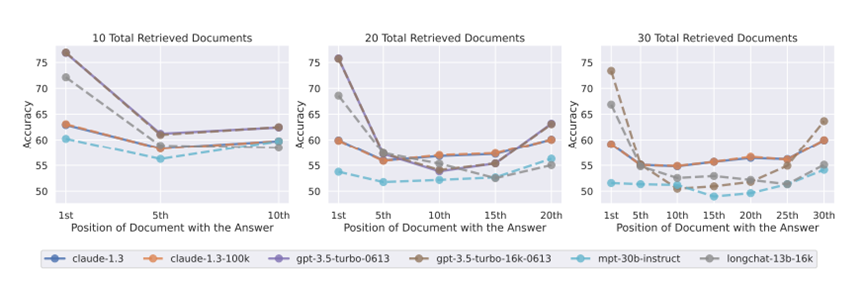
前期准备工作完毕,作者对当前几个“最能打”的大模型进行了测验。从上图可以看出,这些模型都展示出了U形性能。
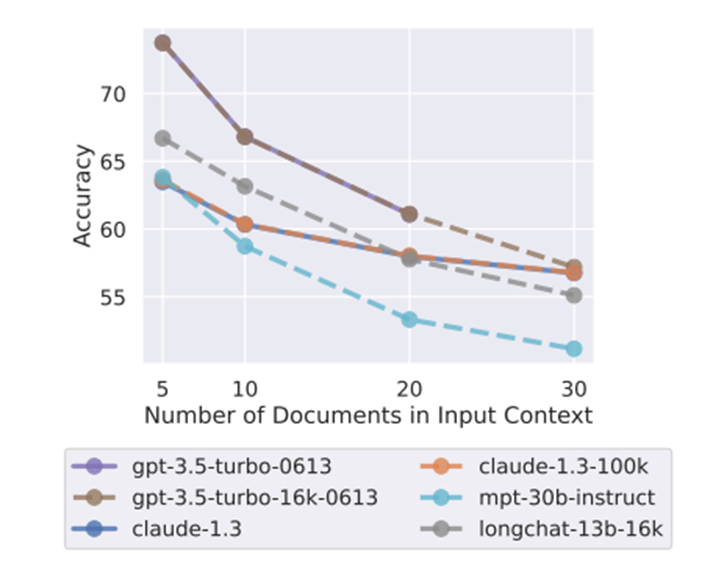
如上图所示,随着输入上下文的增长,模型的表现有明显的下滑。无论哪一个任务,随着上下文扩展,模型的功能都会表现出退化。
键值检索任务
键值检索任务能够测验大模型从输入上下文直接获取信息的能力。键值检索任务中,输入是含k对键值的JSON对象及一特定键,目标是返回该键关联的值。

因此,每个JSON对象都包含一个关联的键值对(需要检索的值),和k-1个不相关的“干扰”键值对。上图展示了键值检索任务输入内容和其对应的预期输出。
该任务中,可通过增加或减少随机键来改变JSON键值对的数量,这样就改变了输入的长度;同时也会调整输入中相关的正確信息的位置。

含有75、140和300个键值对的测试
上图展示了键值检索的表现。结果显示虽然键值找回任务仅需找到输入上下文中的精确匹配,但并非所有模型都表现优秀。claude模型在各种长度上都接近完美,但其他模型在检索大量键值对时遇到了困难。
在键值检索和多文档问答任务中,表现出类似的U型曲线。唯一的例外是在键值检索任务中表现出色的模型(claude)。值得一提的是,LongChat-13B在140键值环境下的表现非常独特,它会生成代码来提取键值,而非直接输出值。
为什么会出现这种问题?
为深入洞察其原因,作者初步研究了模型构架,答案在上下文中位置,和指令调优起到的作用。

在模型架构层面,论文比较了only解码器和编码-解码两类模型,结论是:相比于only解码器的语言模型,编码器-解码器结构的语言模型在上下文窗口方面较为稳健。但当模型处理超过其在训练时使用的最大序列长度时,编码器-解码器模型也会出现U形曲线。
另外,更改答案在上下文中的位置,可以完美地提高关键-值检索任务的性能,但对多文档问答任务的性能趋势影响不大。
最后,作者发现基础语言模型在没有指令调优的情况下也表现出U形曲线,这表明指令调优过程本身可能不是造成这一性能模式的原因。
换句话说,语言模型在利用中间信息上的困难,其根本原因可能不在于指令调优,这需要我们更深入地研究模型本身的结构及训练过程。
论文结论
提供更多上下文信息并非总是有益的。尽管在某些情况下,向语言模型提供更多的上下文信息可以提高其性能,但是在一定点之后,增加更多的上下文信息可能无法带来显著的性能改进。
模型优先使用开头和末尾信息。语言模型更容易处理输入信息的开头和末尾部分,所以把关键信息放在这些位置或缩短文档长度可能有助于提升性能。
模型难以利用更长的上下文。仅仅通过增加上下文长度可能无法有效提升语言模型的性能。要真正改善模型处理长上下文的能力,可能需要从模型本身进行改进,例如改进模型的架构或者训练策略。
参考文献
https://venturebeat.com/ai/stanford-study-challenges-assumptions-about-language-models-larger-context-doesnt-mean-better-understanding/
https://arxiv.org/abs/2307.03172
https://guangzhengli.com/blog/zh/vector-database/
AI文档阅读神器司马阅 通过聊天方式帮你精准获取关键信息
司马阅是一款基于AI技术的智能文档助手,可以上传PDF、Word等多种格式文档,通过语音或文字与文档进行交互,快速定位关键信息。比如可以帮你:1、分析一份合同的风险保护倾向2、总结一个行业报告的发展趋势3、判断一份专业简历的技能水平4、提炼一个产品手册的关键卖点5、概括一份研究论文的核心要点站长网2023-09-08 14:51:260000奥地利隐私投诉瞄准 OpenAI 的 ChatGPT
划重点:⭐️OpenAI的ChatGPT被奥地利的NOYB机构投诉,指控其生成式AI聊天机器人提供了不准确的信息,可能违反欧盟隐私规定。⭐️投诉指称ChatGPT提供了错误的个人信息,并拒绝更正或删除数据,OpenAI表示难以修复这一问题。⭐️NOYB已向奥地利数据保护机构提交投诉,要求调查OpenAI的数据处理和采取的措施。站长网2024-04-29 18:42:020000美国运通探索生成式AI 以提供更好的客户体验
面对最近围绕OpenAI的ChatGPT、谷歌的Bard、Anthropic的Claude和类似的基于大型语言模型的生成人工智能产品的推出和宣传,美国运通看到了利用这些技术可以更好地改善其信用卡和银行客户体验的机会,并开始探索使用生成人工智能来改善其信用卡和银行业务。站长网2023-05-30 10:32:450000报道称美国军方投资数亿美元计划发展智能无人机及AI系统
文章概要:1.美国国防部计划扩大无人机和自主系统机队,加入人工智能技术。2.国防部副部长凯瑟琳·希克斯提出发展“小型、智能、廉价”人工智能系统,以抵御威胁。3.计划包括加强监视设备和网络,尚不清楚具体应用的人工智能技术。美国国防部计划投资数百万美元,扩大其无人机和自主系统机队,并考虑引入更多的人工智能(AI)技术,以增强其军事能力。站长网2023-09-07 14:19:240000小米回应“小米SU7刹车故障”:软件误识别 已修复
快科技5月13日消息,针对网传小米SU7刹车故障”一事,小米集团公关部总经理王化今日发文进行回应。王化表示,经核实,的确是软件误识别,目前已经将这一小概率事件进行修复,大家不必惊慌。以下是王化找汽车部的工程师帮忙梳理的情况:经分析确认,车辆当时为制动主控制器(DPB/BCP)的系统误识别降级触发备用制动策略,制动辅控制器(ESP/BCS)直接响应制动需求为车辆提供刹车减速的情况。站长网2024-05-13 17:57:010000