GPT-4o再暴露「弱智」缺陷,大模型无一幸免,港中文等发布「视觉听觉」基准AV-Odyssey:26个任务直指死角问题
多模态大模型在听觉上,居然也出现了「9.11>9.8」的现象,音量大小这种简单问题都识别不了!港中文、斯坦福等大学联合发布的AV-Odyssey基准测试,包含26个视听任务,覆盖了7种声音属性,跨越了10个不同领域,确保测试的深度和广度。
在人工智能领域,我们一直以为顶尖的多模态大模型已经无所不能,GPT-4o在ASR(音频转文字)任务上已经达到了97%的正确率,更是凸显了强大的音频理解能力。
然而,最近一项来自香港中文大学、斯坦福大学、伯克利大学和耶鲁大学的研究成果却彻底颠覆了这一认知——GPT-4o、Gemini1.5Pro、Reka Core等最先进的多模态大模型居然无法正确分辨明显不同的声音大小!
下面是一个例子:
音频1,新智元,3秒
音频2,新智元,3秒
结果让人难以置信:这些顶尖的AI模型都未能准确判断出音量的差异!对于人类来说,这种问题简直是「傻瓜级」任务,然而这些大模型却纷纷失手,暴露出其在基本听觉能力上的严重缺陷。
这一发现激发了研究团队的思考:为什么如此先进的模型在听觉辨识方面如此薄弱?为了填补这一空白,研究团队首度提出了一个全新的测试工具——DeafTest,它专门用来测试多模态大模型的基础听觉能力。
不仅如此,研究团队还提出了首个全面的多模态大模型视听能力评估基准——AV-Odyssey。这一基准旨在推动未来AI模型在听觉、视觉的理解整合能力上迈向新高度。
论文链接:https://arxiv.org/pdf/2412.02611
项目地址:https://av-odyssey.github.io/
代码地址:https://github.com/AV-Odyssey/AV-Odyssey
DeafTest:多模态大模型的「听力盲点」
为了测试多模态大模型最基础的听觉能力,研究团队首先提出DeafTest,该测试包括四项基础任务:数音频中的声音次数、比较两个音频的响度、比较两个音频的音高、比较两个音频的时长。
这些任务都被设计为对人类来说极其简单的判断题,差异明显,例如:
在响度比较任务中,一个音频的响度在70-100分贝之间,而另一个音频则在30-60分贝之间。
然而,测试结果却令人震惊——这些顶尖的AI模型在大多数任务中的表现,几乎与随机猜测无异,准确率和随机选择的50%差不多,无疑暴露了多模态大模型在音频感知上的巨大短板。
AV-Odyssey Bench:全面评估多模态大模型的视听能力
为了更全面地评估AI在视听能力上的表现,研究团队还推出了一个全新的评估基准——AV-Odyssey。
AV-Odyssey包含26个任务,覆盖了7种声音属性——音色、语调、旋律、空间感知、时序、幻觉、综合感知,并且跨越了10个不同领域,确保测试的深度和广度。
为了确保评估的稳健性和公正性,所有任务均采用四选一的多项选择题形式,每个问题都融合了视觉、听觉等多模态信息,全面考察模型的综合处理能力。
此外,为了避免因输入顺序或格式导致的偏差,所有输入(包括文本、图片/视频和音频片段)都会以交错的方式输入到多模态大模型中。问题的形式如下图所示:
AV-Odyssey中包含了由人类专家全新标注的4555个问题,确保题目没有在其他任何数据集中出现过,任务分布以及统计信息如下面图表所示:
同时,为了进一步控制质量,研究团队利用5个视觉语言模型和4个音频大语言模型,过滤出包含冗余图像或音频片段的问题。
在这个过程中,2.54%的问题同时被所有视觉语言模型或所有音频大语言模型解决,研究团队去除了这些问题。
AV-Odyssey 实验结果
从实验结果中,可以发现:
AV-Odyssey的挑战性:
大多数现有的多模态大语言模型平均表现仅略高于25%,这与四选一问题的随机猜测准确率相当。值得注意的是,即使是AV-Odyssey中的表现最佳的模型——GPT-4o,也仅取得了34.5%的准确率。
这一结果凸显了AV-Odyssey所带来的高挑战性,远远超出了当前模型训练数据的分布范围。
通过设定严格的标准,AV-Odyssey基准测试为评估多模态大模型在音频视觉任务中的能力提供了一个重要工具,突显了现有模型的局限性,并为未来的改进指明了方向。
开源多模态大模型训练的局限性:
同时,即便OneLLM、Unified-IO-2、VideoLLaMA2和NExT-GPT 通过引入Audiocaps等音频-文本匹配数据集,尝试增强音频理解能力,并结合图像-文本配对数据训练视觉理解,这些模型在AV-Odyssey的测试中仍然表现不佳。
这表明,目前的训练流程并不足以真正弥合音频与视觉模态之间的鸿沟,也未能有效地学习音视频信息的整合与深度理解。
AV-Odyssey 错误分析:音频感知仍是瓶颈
研究团队对Gemini1.5Pro在AV-Odyssey中的错误进行深入分析,对每个任务随机抽取了4个错误案例进行人工标注,最终得到104个错误案例,并对其进行统计。错误的分布如下图所示:
这一分析结果揭示了一个重要趋势:63%的错误都集中在音频理解上!
例如,在某些任务中,虽然模型正确理解了视觉信息,但是音频片段的内容识别错误,导致了错误答案的生成。一个例子如下图所示:
这一发现再次印证了DeafTest的初步结论:当前多模态大模型在基础的听力能力上存在明显短板,音频感知依然是多模态任务中的最大瓶颈。
参考资料:
https://av-odyssey.github.io/
谷歌AI概览功能触发频率大幅下降 仅出现在15%的查询结果中
划重点:⭐谷歌的AI概览以前曾经在84%的查询结果中显示⭐人工智能概述现在只在不到15%的查询结果中显示⭐谷歌通过减少人工智能引文与传统搜索结果的重叠来改进搜索质量根据一项新分析,谷歌的人工智能概述现在只出现在不到15%的查询结果中。过去,谷歌的AI概览(以前在实验室中被称为搜索生成体验)一度出现在84%的查询中。站长网2024-06-06 17:21:010000开源AI搜索平台Swirl 支持Microsoft 365集成
Swirl是一个开源的元搜索平台,可以无缝地连接数据库、数据仓库、搜索引擎以及数据间隙。它能让您深入挖掘隐藏的见解,并且轻松探索您的数据。不管您是创业公司还是大型企业,Swirl都能够根据您的需求进行定制。项目地址:https://github.com/swirlai/swirl-search站长网2023-09-12 10:55:000001滴滴推出自动驾驶概念车DiDi NEURON
在今日的滴滴自动驾驶开放日上,滴滴出行CTO兼自动驾驶CEO张博表示,滴滴出行APP已可在上海、广州的指定区域内直接看到“自动驾驶”选项并叫车,体验滴滴自动驾驶带来的服务体验。同时,在会上,滴滴还推出了自动驾驶概念车DiDiNEURON。据悉,DiDiNEURON配备了车内机械臂,可以实现车内外的多种服务,如提行李、递水等。站长网2023-04-13 16:15:350000今日AI:Gemini Pro1.5向所有人开放;Stable Diffusion核心团队集体离职;HeyGen5.0上线视频翻译功能;剪映内测视频翻译功能
欢迎来到【今日AI】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/🤖📱💼AI应用GeminiPro1.5及其百万上下文功能现已向所有人开放【AiBase提要:】站长网2024-03-23 13:49:560000谷歌推数学几何模型Alpha Geometry 解题能力接近奥数金牌选手
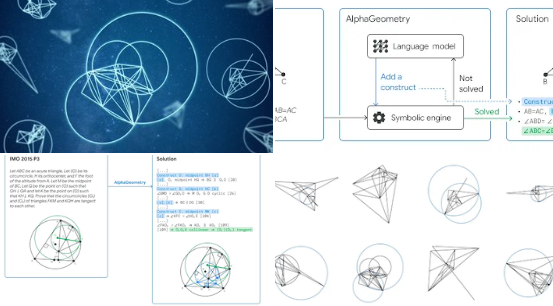
谷歌推出了新的面向数学几何领域的模型AlphaGeometry,数学几何能力已接近人类奥林匹克金牌选手的水平。特别值得一提的是:它的训练是基于合成数据而不是现有的数据。它训练的方式很有特别:先初始生成了十亿个随机几何图形,并全面分析了每个图形中点和线的所有关系。AlphaGeometry找出了每个图形中所有的证明,并反向追溯出为得到这些证明所需添加的额外几何元素(如果有的话)。站长网2024-01-18 14:39:420001