比OpenAI的Whisper快50%,最新开源语音模型
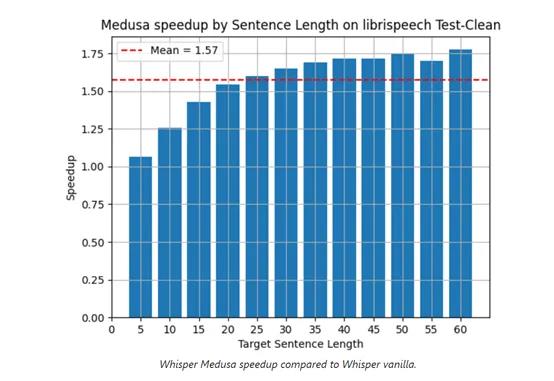
生成式AI初创公司aiOla在官网开源了最新语音模型Whisper-Medusa,推理效率比OpenAI开源的Whisper快50%。
aiOla在Whisper的架构之上进行了修改采用了“多头注意力”机制的并行计算方法,允许模型在每个推理步骤中预测多个token,同时不会损失性能和识别准确率。
开源地址:https://github.com/aiola-lab/whisper-medusa
huggingface:https://huggingface.co/aiola/whisper-medusa-v1

传统的Transformer架构在生成序列时,是遵循逐个token的顺序预测过程。这意味着在生成新序列时,模型每次只能预测下一个token,然后将这个预测的token加入到序列中,再基于更新后的序列预测下一个token。
这虽然能够确保生成序列的连贯性和上下文相关性,但也有一个非常明显的缺陷——极大限制了模型的推理效率。
此外,由于每次只能处理一个 token ,模型难以捕捉到数据中的长程依赖关系,可能会忽略一些重要的全局信息,从而影响模型的整体性能和准确性。
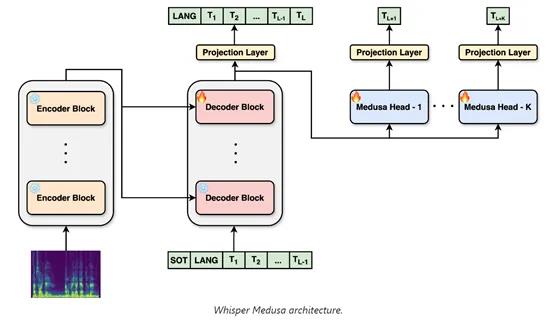
而Whisper-Medusa使用了10头的多注意力机制, 能各自独立地计算注意力分布并行地处理输入,然后将各自的输出通过拼接的方式组合起来,形成一个多维度的向量。
随后向量被送入全连接层进行进一步的处理,以生成最终的token预测。这种并行的数据处理方式不仅加快了模型的推理效率,还增加了模型的表达能力,因为每个注意力头都可以专注于序列的不同子集,捕捉到更丰富的上下文信息。
为了使多头注意力机制在Whisper-Medusa模型中更高效地运行,aiOla采用了弱监督的方法,在训练过程中冻结了原Whisper模型的主要组件,使用该模型生成的音频转录作为伪标签来训练额外的token预测模块。
使得模型即便没有大量手动人工标注数据的情况下,依然能够学习到有效的语音识别模式。
此外在训练过程中,Whisper-Medusa的损失函数需要同时考虑预测的准确性和效率。一方面,模型需要确保预测的token序列与实际转录尽可能一致;
另一方面,通过多头注意力机制的并行预测,模型被鼓励在保证精度的前提下,尽可能地加快预测效率。
aiOla使用了学习率调度、梯度裁剪、正则化等多种方法,确保模型在训练过程中能够稳定收敛,同时避免过拟合性。
业务场景方面, Whisper-Medusa能理解100多种语言,用户可以开发音频转录、识别等多种应用,适用于翻译、金融、旅游、物流、仓储等行业。
aiOla表示,未来会将Whisper-Medusa的多注意力机制扩展至20个头,其推理效率将再次获得大幅度提升。

超强o1模型智商已超120!1小时写出NASA博士1年代码,最新编程赛超越99.8%选手
o1模型已经强到,能够直出博士论文代码了!来自加州大学欧文分校(UCI)的物理学博士KyleKabasares,实测o1previewmini后发现:自己肝了大约1年的博士代码,o1竟在1小时内完成了。他称,在大约6次提示后,o1便创建了一个运行版本的Python代码,描述出研究论文「方法」部分的内容。站长网2024-09-18 02:33:440000调查显示:人工智能将在未来一年塑造全球零售业
本文概要:1.近六分之一的零售商计划在明年采用人工智能等技术,以提升购物体验。2.零售商认为人工智能可补充和增强劳动力,而非取代员工。3.预算限制、难以证明商业价值是采用人工智能的障碍。霍尼韦尔(Honeywell)最近一项调查显示,人工智能、机器学习和计算机视觉技术正在深刻影响零售业,预计未来一年这些技术将进一步塑造全球零售业的发展。站长网2023-08-24 16:31:180000霉霉开口唱碧昂丝的歌,又是AI!口型不出戏,五官姿态也自然,复旦百度等出品|GitHub揽星1k+
一张人像、一段音频参考,就能让霉霉在你面前唱碧昂丝的《Halo》。一种名为Hallo的研究火了,GitHub已揽星1k。话不多说,来看更多效果:不论是说话还是唱歌,都能和各种风格的人像相匹配。从口型到眉毛眼睛动作,各种五官细节都很自然。单独拎出不同动作强度的比较,动作幅度大也能驾驭:单独调整嘴唇运动幅度,表现是这样婶儿的:站长网2024-06-19 00:19:490000苹果客服回应微信语音通话频繁中断:可能与程序崩溃有关
近期,多名网友在社交平台发帖反映,使用iPhone进行微信语音或视频通话时遭遇频繁中断的问题,尤其是当切换到其他应用程序时,通话会被立刻中断。据了解,出现问题的微信版本主要为8.0.53。0000李佳琦叫不醒618
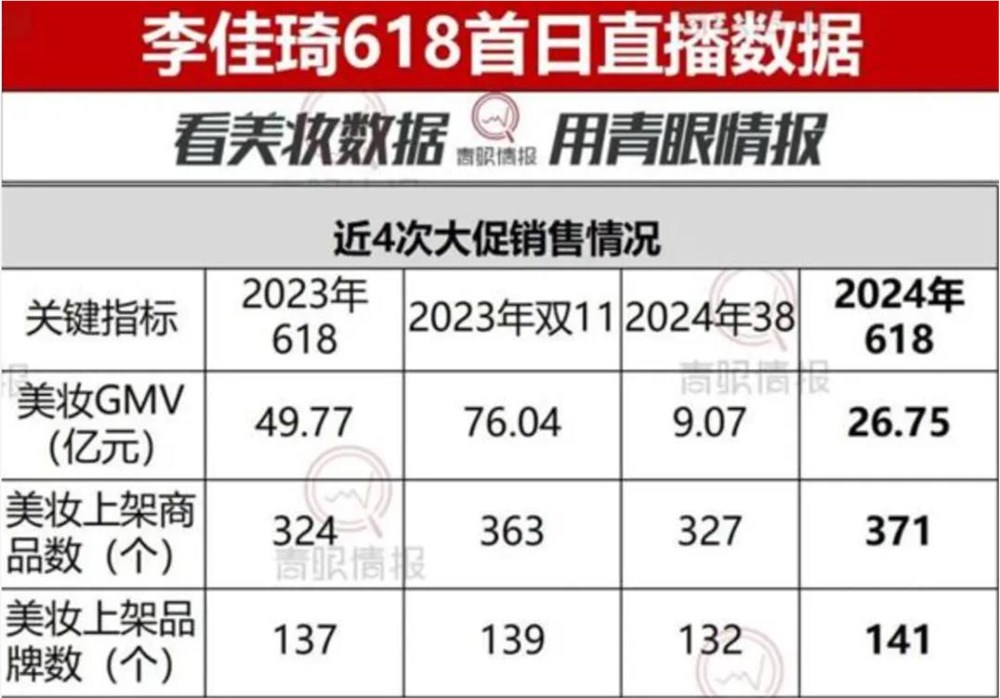
李佳琦一语成谶,今年618很难。据“青眼情报”数据,李佳琦618预售第一日,直播间的美妆类目GMV(商品成交总额)超26.75亿元,同比下降46%。按照“青眼情报”统计,李佳琦直播间在2023年618首场美妆预售的GMV约为49.77亿元。图源:青眼情报站长网2024-05-25 22:59:270000