半小时教你手搓AI视频通话,还有懒人版代码已开源
GPT-4o的“AI视频通话”一鸽再鸽,但网友却是急不可耐想要体验。
于是,一位名叫Santiago(我们叫他三哥)的博主,用160行Python代码尝试了复刻。
虽然技术路线和《Her》有所差别,但从直观效果来看,也算得上是给网友们带来了新的玩具。
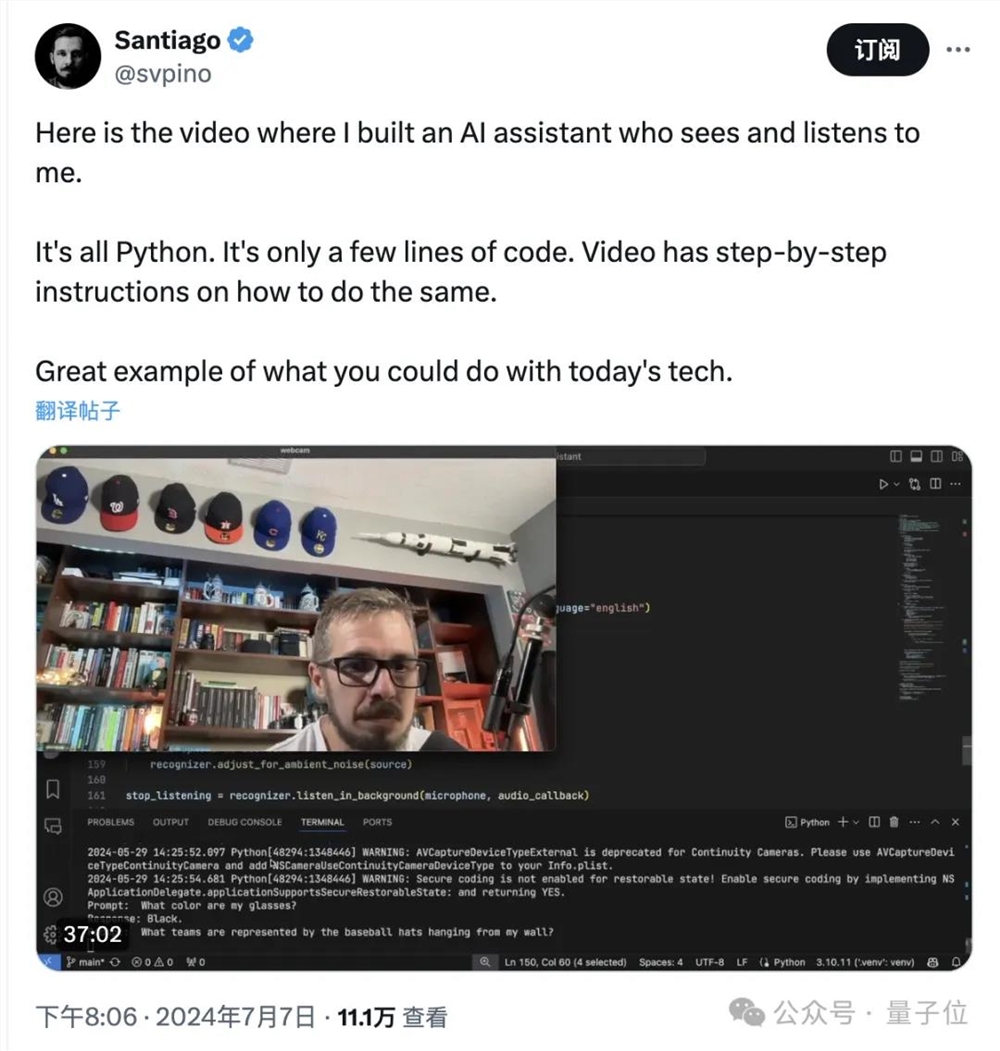
而且不仅是炫技,三哥是真的在试图把网友教会,用了半个多小时的时间讲解他的操作过程。
不过,三哥的自我介绍中说,自己是一个讲授硬核机器学习知识的博主,之前也推出过不少课程。
所以讲课这件事对三哥来说,也可以算是老本行了。
对三哥这次推出的新课,网友给予了很高的评价,表示不仅内容很赞,而且讲解得也很好。

甚至为了防止你觉得学起来太麻烦,三哥直接就把程序代码给公开了。
还有网友在线催更,有的想要增加屏幕读取的功能,还有人想要移动版……
用Python实现AI视频通话
三哥做的视频通话程序名叫Alloy Voice Assistant(简称Alloy),在视频中他演示了这样几组对话效果。
首先是一道基础问题,三哥让Alloy识别一下自己戴的眼镜是什么颜色。
这道题对Alloy来说确实是没什么难度,很轻松就能回答上来是黑色。
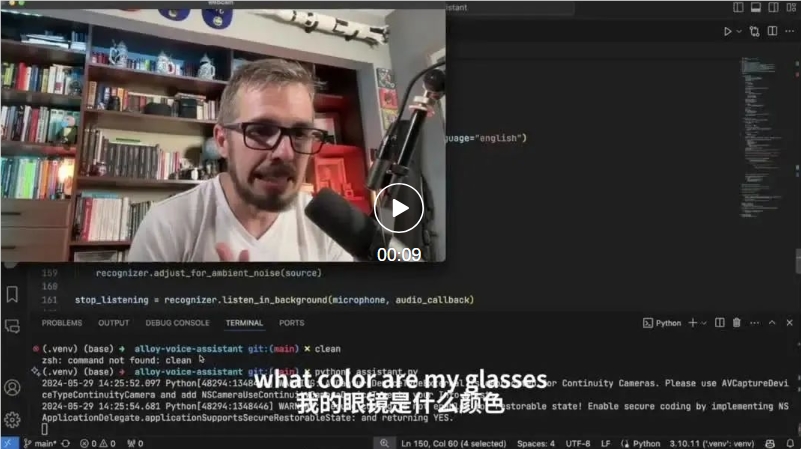
接下来,三哥就要给Alloy上难度了,这次要识别的是棒球帽上的徽章,并分析出所代表的球队。
这次不仅要识别的内容和镜头的距离变远了,而且Alloy需要一次性识别六个。
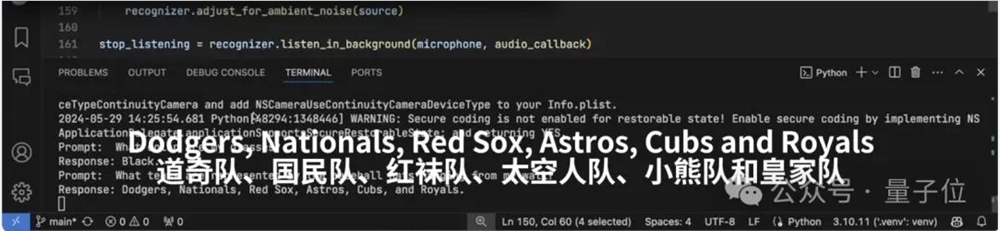
关于视频中涉及的棒球帽,我们来看下特写:
从左到右依次是(洛杉矶)道奇队、(华盛顿)国民队、(波士顿)红袜队、(休斯顿)太空人队、(芝加哥)小熊队和(堪萨斯城)皇家队。

我们再来看下Alloy给出的回答……完全正确。
最后一题,Alloy需要识别的内容变成了文字——不仅要知道写了什么,还要知道文字代表的含义。
只见三个拿出了一本书朝向了镜头,先后询问Alloy书的名称和作者。
这本书是苹果机器学习高级工程师Robert Munro Monarch写的Human-in-the-Loop Machine Learning(《人在回路·机器学习》),Alloy回答对了。
从三哥的演示中我们可以看出,Alloy在识别和回答的准确率上还是很能打的,不过响应的速度也确实慢了一些。
但毕竟不是原生功能,需要在多个API之间进行跳转,所以也算是可用。
那么Alloy到底是怎么实现的呢?三哥进行了在线教学。
37分钟细致讲解,还有开源懒人版
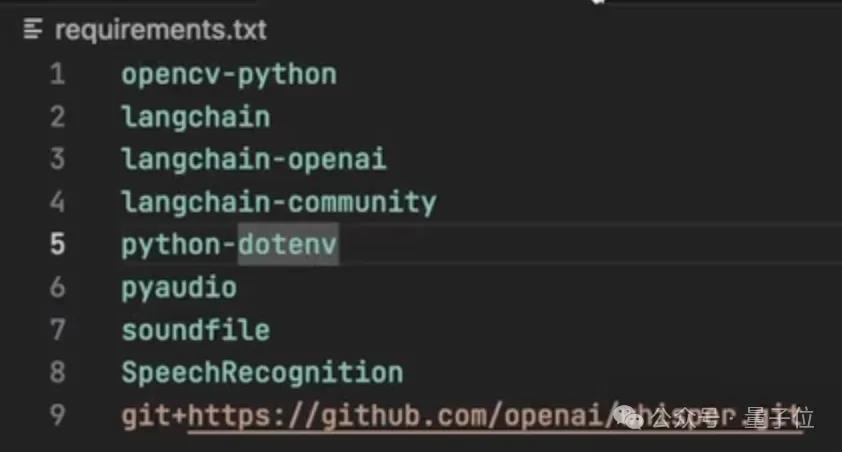
跟随着三哥的讲解,我们先来看一下都需要用到哪些工具。
既然要“视频通话”,当然就得有视觉处理模块,三哥用OpenCV来对画面进行捕获,然后交给多模态大模型进行处理。
具体的大模型可以有多种选择,包括GPT-4o、Claude和Gemini1.5Pro等,同时大模型还要承担文本处理的任务。
这是由于Alloy并非原生支持音频模态,所以处理音频的方式是通过文本作为中介实现,这就需要用到语音识别和合成模块,这里三哥用的分别是OpenAI的Whisper和TTS引擎。
另外,为了让大模型的集成变得更加容易,三哥这里还使用到了大模型编程框架LangChain。
最重要的,想要把这些模块都组合在一起,就需要用Python来编写代码,也要有相应工具的API。
看到这些工具,Alloy的大致工作流程也就清晰明了了——
麦克风和摄像头负责收集视觉和声音信息,然后声音被转换成文本并于视觉信息一起通过API送入大模型,大模型完成分析后以文本形式回传,最后用TTS模块合成语音并通过扬声器播放。
具体操作中,需要先安装好所需要的依赖库,并申请相应大模型的API,并创建一个Python程序加载这些依赖。
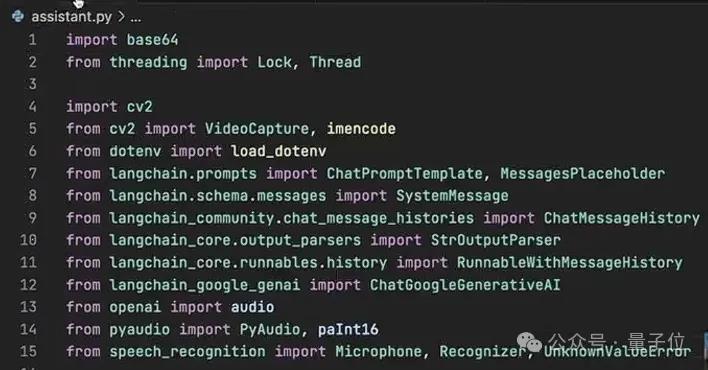
之后是编写WebcamStream类,用来捕获摄像头当中的图像,这里就用到了OpenCV当中的VideoCapture。
视频中,三哥针对每一行代码的含义和作用都进行了解释,感兴趣的话可以看原视频,这里就不一一展开了。
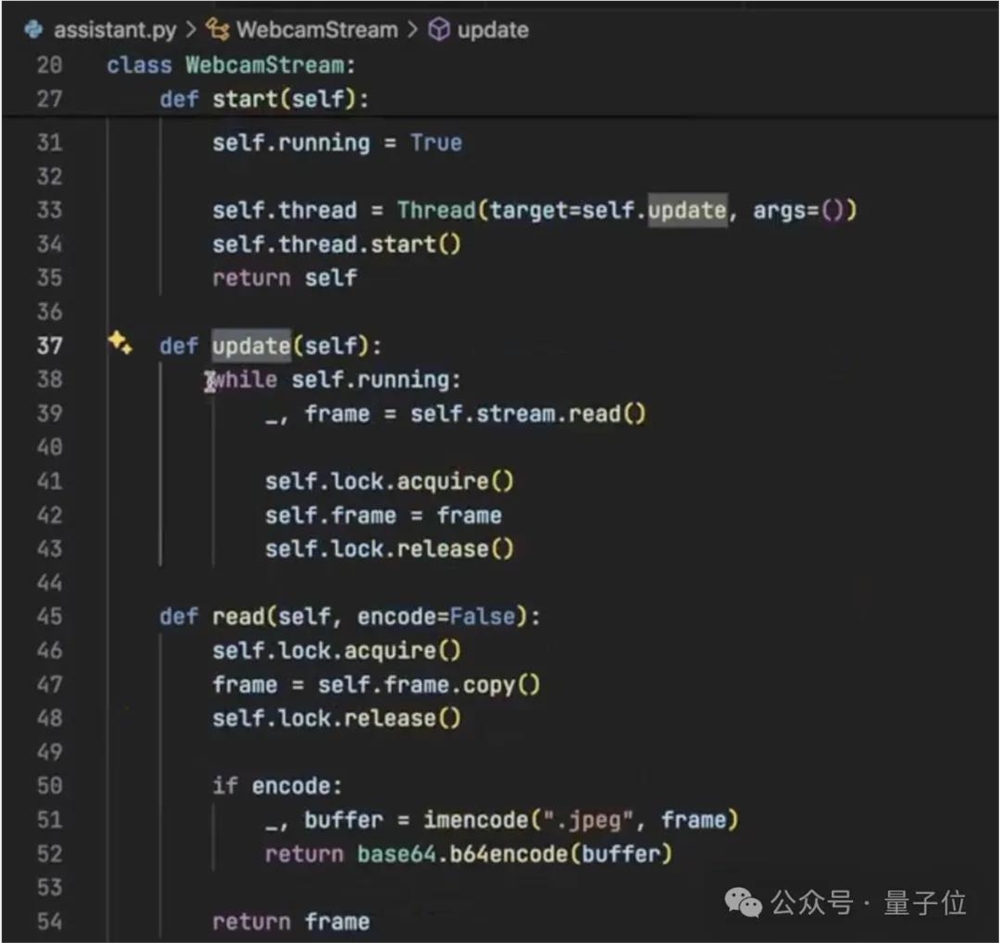
之后是Assistant类,也是整个Alloy系统中最核心的环节,从初始化和配置AI模型,到处理用户输入、声文互转、生成回答,再到对话记录的管理,Assistant都发挥着重要作用。
可以说,Assistant类是串起用户、输入设备和AI模型的桥梁,也是三哥在整个教程中讲解时间最长的一部分。
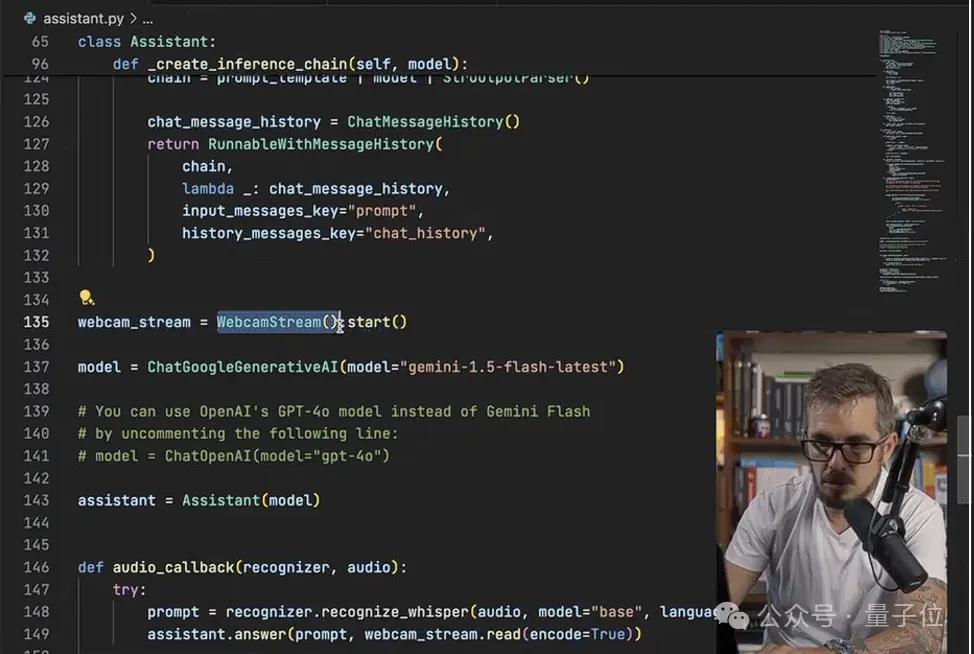
把这两个类定义好之后,最后就是主程序的设计,首先为这两个类各创建一个实例,之后配置摄像头和麦克风,就可以进入主循环体了。
主循环体会不断从WebcamStream实例中读取最新的视频帧,并使用OpenCV的imshow()函数在窗口中实时显示。
同时,当语音识别器检测到用户开始说话并结束时,会自动将语音转换为文本,并调用相关函数进行处理。
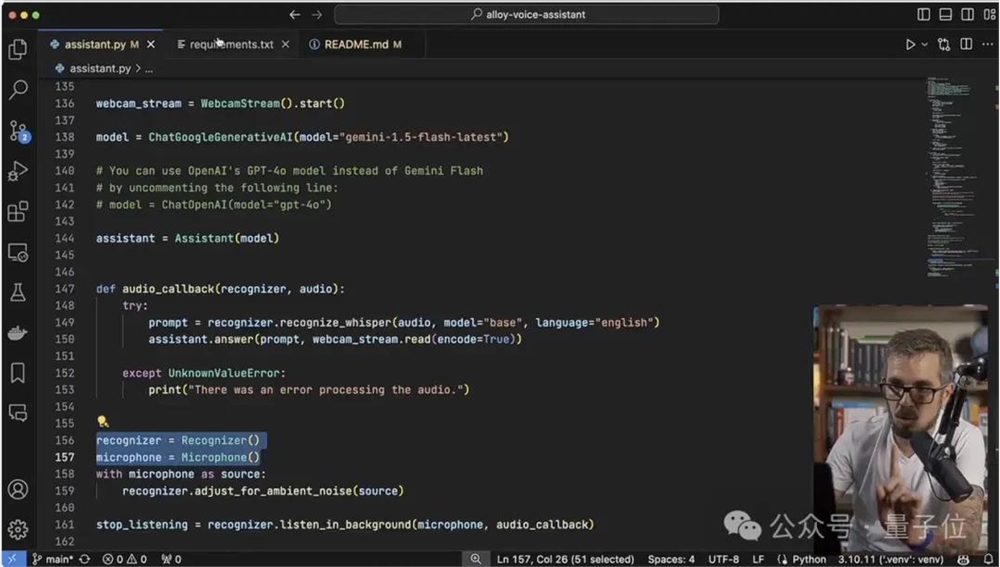
以上就是Alloy搭建的大致流程了,如果看了觉得实在太麻烦不想自己动手的话,三哥还在GitHub上准备了懒人版。
只需要根据选择的模型调整几行代码并填好API,就能直接用了。
如果你也想体验一下AI视频通话的话,不妨动手试一下吧。
原视频地址:
https://www.youtube.com/watch?v=zVttVCQvACQ
GitHub:
https://github.com/svpino/alloy-voice-assistant
研究发现针对ChatGPT、Bard 等LLM的自动越狱攻击
研究人员发现,可以自动构建对抗性攻击,欺骗ChatGPT、Bard和Claude等主要语言模型(LLM),以提供非预期且可能有害的内容传统的越狱需要大量手动开发,通常可以由LLM供应商解决。然而,这些自动化攻击可以大量创建,并且可以在闭源和公开的聊天机器人上运行。站长网2023-07-31 10:44:460001英伟达为英国GW4联盟打造新超算:基于Grace CPU Superchip的Isambard 3
英伟达宣布,将基于GraceCPUSuperchip为英国GW4联盟打造一台新的超级计算机,名为Isambard3。届时这台新的超算系统将安装在英国布里斯托尔和巴斯科学园,里面搭载了384颗基于Arm架构的GraceCPUSuperchip,预计性能和能效将达到现有Isambard2的六倍,使其成为欧洲最节能的系统之一。站长网2023-05-24 09:55:160000爱奇艺回应基础会员不能跳过片头120秒广告:建议按需选择会员类型
站长之家(ChinaZ.com)7月15日消息:近期,爱奇艺平台因基础会员无法跳过视频片头120秒的广告而遭到众多网友的吐槽。对此,爱奇艺官方客服作出回应,明确表示基础会员可以正常观看会员内容,但权益中并不包括跳过片头片尾广告。相对而言,黄金会员则享有直接跳过这些广告的特权。站长网2024-07-15 16:10:190001RAGatouille:几行代码搞定,让你轻松玩转SOTA检索模型ColBERT!
划重点:1.🌐**RAGatouille简介:**一款旨在简化最先进检索方法集成的机器学习库,专注于使ColBERT更易用。2.🧩**关键功能:**提供强大的默认设置和可定制的模块,使ColBERT模型的训练和微调过程更易于访问。3.📊**性能展示:**通过TrainingDataProcessor展示出色的检索训练数据处理能力,使复杂的检索方法更易于实际应用。站长网2024-02-05 11:08:060002联合国秘书长支持建立类似国际原子能的人工智能监管机构提议
联合国秘书长安东尼奥·古特雷斯日前表示支持一些人工智能高管提出的建立一个类似国际原子能机构(IAEA)的国际人工智能监管机构的提议。自ChatGPT六个月前推出并成为有史以来增长最快的应用程序以来,可以根据文本提示生成权威性散文的生成式人工智能技术一直吸引着公众的关注。人工智能也成为人们担忧的焦点,因为它具有创造深度伪造图片和其他虚假信息的能力。站长网2023-06-13 23:54:050000












