研究发现针对ChatGPT、Bard 等LLM的自动越狱攻击
站长网2023-07-31 10:44:461阅
研究人员发现,可以自动构建对抗性攻击,欺骗ChatGPT、Bard 和 Claude 等主要语言模型 (LLM),以提供非预期且可能有害的内容
传统的越狱需要大量手动开发,通常可以由 LLM 供应商解决。然而,这些自动化攻击可以大量创建,并且可以在闭源和公开的聊天机器人上运行。

这项研究对大型语言模型(LLMs)的安全性进行了研究,发现可以自动构建对 LLMs 的对抗攻击,通过附加特定字符序列到用户查询中,使系统在产生有害内容的同时执行用户命令。这些攻击是自动化构建的,可以创建无数个攻击。
研究人员展示了一些攻击的示例,展示了在用户查询中添加对抗后缀字符串之前和之后 LLM 的行为。研究人员指出,这项研究包含的技术和方法可以让用户从一些公共 LLMs 生成有害内容。
攻击在计算机视觉领域已经存在了十多年,这表明
类似的对抗性攻这类威胁可能是人工智能系统固有的。研究还表明,可能无法完全阻止这类攻击。随着社会对人工智能技术的依赖越来越大,我们应该考虑这些问题。
0001
评论列表
共(0)条相关推荐
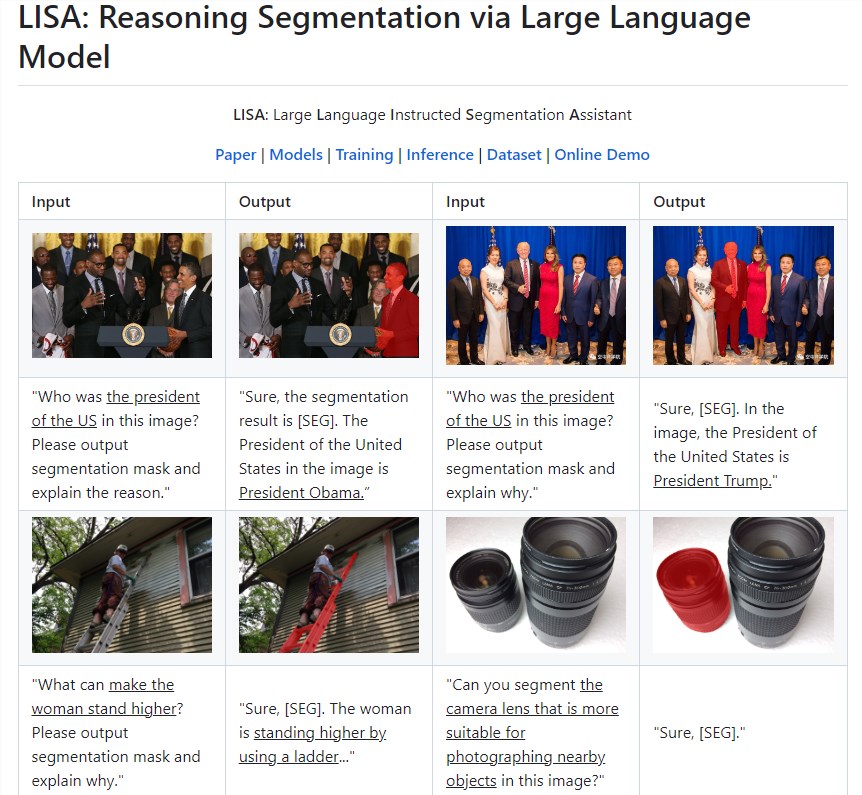
微软推出大型语言模型分割推理助手LISA
想象一下你想喝咖啡,然后你命令机器人去泡咖啡。您的指令涉及“煮一杯咖啡”,但不包括“去厨房,找到咖啡机,然后打开它”等分步指令。目前的现有系统包含依赖人类指令来识别任何目标对象的模型。他们缺乏推理能力和主动理解用户意图的能力。站长网2023-08-10 10:54:310001苹果新功能“智能摘要”或引发对AI搜索工具的冲击
苹果公司可能会再次引发“Sherlock”效应,这次的目标是AI驱动的搜索功能。近年来,苹果被指从其开发者社区借鉴创意以丰富自家应用和操作系统功能。从20世纪90年代末Sherlock查找器应用的发布,到最近的连续互通相机、Sidecar和ApplePayLater,苹果一再被批评“封杀”了第三方应用程序。最新的目标可能是AI搜索和摘要工具。站长网2024-05-30 10:49:500000中科闻歌将于6月3日推出雅意AI大模型
中科闻歌宣布,将在6月3日推出雅意AI大模型。据介绍,雅意AI大模型支持实时在线联网、自主私有化部署、企业数据领域知识、领域深度认知等特性,为企业提供大模型、数字人、领域模型应用服务。站长网2023-05-19 16:36:290000我,网上骂醒“恋爱脑”,日入2000元
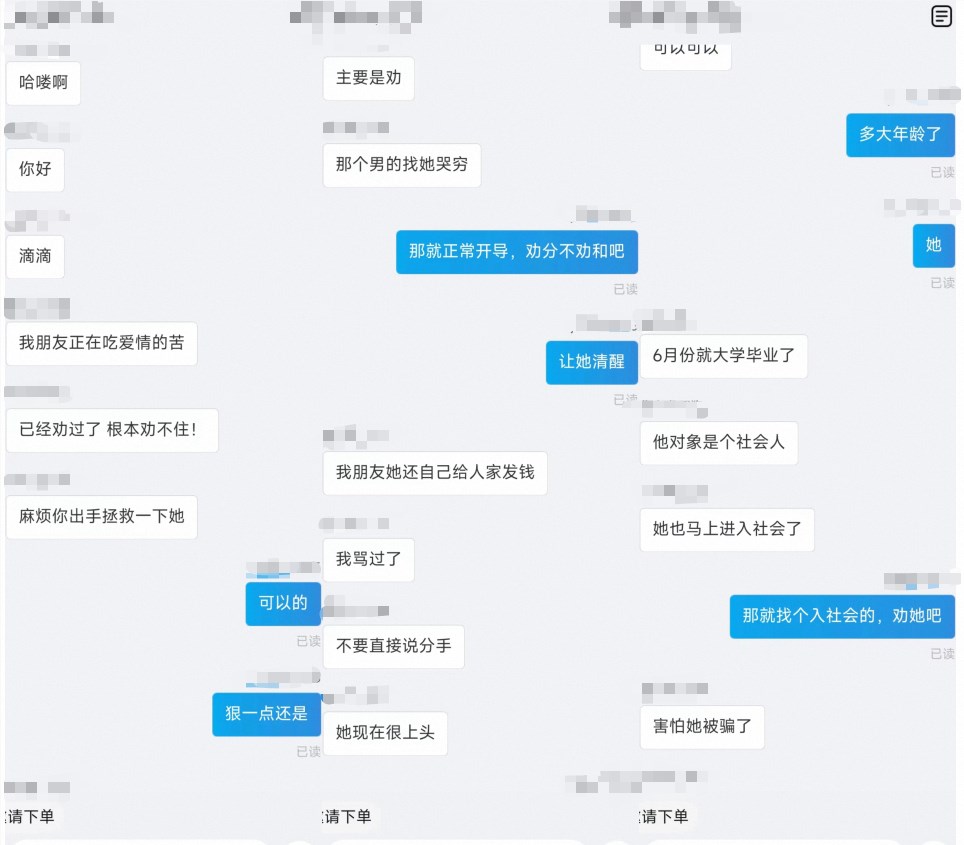
如果要问一个年轻人,当代最无可救药的“绝症”是什么,“恋爱脑”必定榜上有名。“人间清醒”的年轻人甚至为此发明了完整的“恋爱脑劝退套餐”:“手机锁屏是张翰,闲着没事就看王宝钏挖野菜;茶余饭后点开许超医生微博;睡前脑内小剧场男主角那得是慕容云海。”(年轻人为“剔除恋爱脑”做出种种行为的网络梗)站长网2023-07-04 15:58:1400018广东夫妇成6月抖音直播带货冠军,夫妻档的流量密码怎么解?
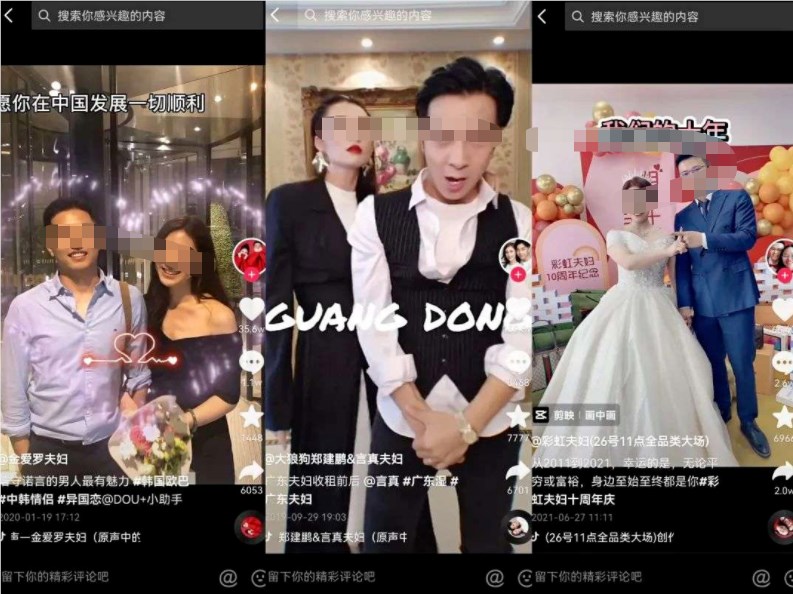
“不要夫妻千担粮,只要夫妻好商量”,近年来,越来越多夫妻搭档出现在直播间开始带货,他们在直播间左手秀恩爱,右手创造带货奇迹,爱情、工作两不误。除了鼻祖式存在的广东夫妇,还有“高颜值学霸”金爱罗夫妇、喜欢“造节”彩虹夫妇等,夫妻档逐渐成为各平台带货的“流量密码”,夫妻模式直播带货为何倍受用户喜爱?不妨以广东夫妇为例,从他们身上找出一些流量门道。广东夫妇的直播带货有多强?站长网2023-07-13 09:09:100000