OpenAI开源GPT-4 SAE,提供1600万个解释模式
6月7日凌晨,OpenAI在官网开源了GPT-4的稀疏自动编码器(Sparse AutoEncoder,简称“SAE”)。
虽然现在大模型的功能越来越强,能生成文本、图片、视频、音频等内容,但是你无法控制神经网络生成的内容,例如,你问ChatGPT多个相同的问题,可能每一次回答的内容都不相同。
就像我们睡觉做梦一样,无论你怎么集中注意力还是很难精准控制脑神经形成的梦境。这就会出现很多无法控制的情况,例如,大模型生成的内容带有歧视性、错误、幻觉等。
SAE的主要作用是在训练过程中引入稀疏性约束,帮助大模型学习到数据的更有意义、更具解释性的特征表示,使其输出的内容更精准、安全。所以,SAE对于开发前沿、超强功能的大模型非常重要。

早在2023年10月,著名大模型平台Anthropic发布了一篇《朝向单义性:通过词典学习分解语言模型》的论文,深度解释了神经网络行为的方法。
Anthropic在一个小型的Transformer架构模型进行了实验,将512个神经单元分解成4000多个特征,分别代表 DNA 序列、法律语言、HTTP 请求、营养说明等。
研究发现,单个特征的行为比神经元行为更容易解释、可控,同时每个特征在不同的AI模型中基本上都是通用的。

而本次OpenAI不仅公布了论文还开源了代码,同时提供了一个在线体验地址,与全球开发者分享他们的研究成果,同时让用户深度了解神经网络生成的内容流程,以便更精准、安全地控制大模型输出。
开源地址:https://github.com/openai/sparse_autoencoder
论文地址:https://cdn.openai.com/papers/sparse-autoencoders.pdf
在线demo:https://openaipublic.blob.core.windows.net/sparse-autoencoder/sae-viewer/index.html
什么控制神经网络行为很难
无论你用多么精准的提示词,都无法让DALL·E3、Stable Difusion生成100%相吻合的图片。这是因为,神经网络的输出很大程度上依赖于它们所接受的训练数据。
神经网络通过大量的样本数据学习到复杂的模式和特征。但是,训练数据本身可能包含噪声、偏差或者数据标准不准确等。这些因素会直接影响神经网络对输入数据的响应。
例如,让神经网络生成一张猫的图片。如果训练数据中有一些不清晰或错误标记的图片,例如狗或其他动物的照片,模型可能会在生成猫的图片时出现混乱,生成出一些看起来不像猫的图像。同理,文本类的ChatGPT等产品也会出现一本正经胡说八道的情况。
神经网络的内部结构和参数设置极其复杂。随着技术的迭代,目前随便一个神经网络模型的参数都在几十亿甚至数百亿,这些参数共同决定了模型的行为。
在训练过程中,我们通过优化算法(如梯度下降法)对这些参数进行调整,但最终模型的表现是所有参数综合作用的结果,而非单一参数所能决定的。
这种复杂性导致我们难以精确预测或控制任何特定的输出。例如,如果你调整一个参数来让生成的图片更有细节,它可能导致其他部分的图片出现失真或不自然的效果。

此外,神经网络的设计和训练目标通常是为了优化整体性能指标(如准确率、损失函数等),而不是精确到每一个具体的输出细节。例如,在图像生成中,模型的目标可能是生成总体上看起来真实的图片,而不是控制每一个像素的具体值。
同样,在文本生成中,模型的目标是生成语法正确、语义连贯的句子,而不是控制每个单词的具体选择。例如,一个训练写诗的模型,目标是写出富有诗意的句子,而不是精确到每一个词的位置和使用频率。
这也就是说,大模型的输出通常是基于概率分布的采样,输出不可避免地带有一定程度的不确定性。
OpenAI的SAE简单介绍
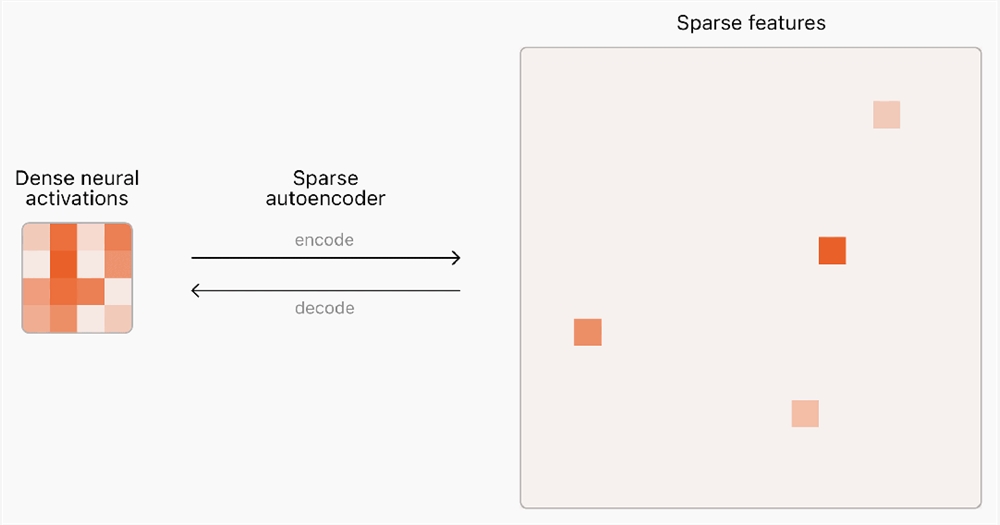
SAE是一种无监督学习算法,属于自编码器家族的一种,主要用来学习输入数据的有效且稀疏的低维表示。在传统的自编码器中,数据被编码成一个潜在的低维表示,然后再解码回原始数据空间,目的是使重构的数据尽可能接近原始输入。
而SAE在此基础上添加了一个关键特性,即对隐藏层的激活进行稀疏性约束,这意味着在隐藏层中只有少量的神经元会被激活(通常接近0),而大部分神经元则保持在非常低的激活水平或者完全不激活。
从OpenAI公布的论文来看,为了深度理解大模型的单个神经元行为,OpenAI使用了一种N2G的方法。
N2G的核心思想是,如果一个潜在单元在给定的输入模式下被激活,那么这个单元可能对输入中的某些特定特征或模式特别敏感。
通过识别这些特征或模式,我们可以为每个潜在单元构建一个图表示,图中的节点对应于输入序列中的特定位置,而边则表示这些位置之间的依赖关系。这种图表示可以揭示潜在单元激活的条件,从而提供对模型行为的直观理解。

N2G的构建过程开始于选择一些能够激活特定潜在单元的序列。对于每个序列,N2G寻找最短的后缀,这个后缀仍然能够激活该潜在单元。这个过程是为了确定潜在单元激活的最小必要条件。
接着,N2G会检查内容是否可以被填充标记替换,以插入通配符,从而允许在解释中包含变化的部分。此外,N2G还会检查解释是否依赖于绝对位置,即在序列的开始处插入填充标记是否会影响潜在单元的激活。
N2G还有一个非常大的技术优势就是对算力需求很低,与需要模拟整个模型行为的解释方法相比,N2G只需要分析潜在单元的激活模式即可。
目前,OpenAI通过SAE在GPT-4模型中找到了1600万个可解释的模式和特征,但这还远远不够。如果想通过SAE完整捕捉大模型的行为,大概需要10亿或数万亿个特征才可以。
低价战凶猛,门店转让潮,接盘旅拍“五一”亏惨
作为假期曾经最赚钱的旅游生意之一,今年“五一”,旅拍店商家并没有迎来想象中泼天的富贵。“门店暴增,价格战打得太凶了,遍地黄牛抢客户,今年五一假期门店订单量甚至不如淡季”,一位旅拍店老板对Tech星球说道,她原计划再投资一家旅拍店的想法已经动摇,也开始担心现有门店能否持续经营。0000苹果库克回应Vision Pro头显中国上市时间:快了
站长之家(ChinaZ.com)2月4日消息:近日,苹果的最新产品VisionPro头显在美国正式开售,引发了市场和消费者的广泛关注。很多中国消费者关心的是,这款高科技产品何时会在中国上市。站长网2024-02-04 14:09:120000维基百科创始人评价 ChatGPT:当前阶段「糟糕」,但 50 年后可能超越人类
在最近接受EuronewsNext采访时,维基百科创始人吉米·威尔士(JimmyWales)对当前ChatGPT的性能表达了严厉的批评。他指出,该OpenAI开发的流行人工智能(AI)工具在撰写维基百科文章时效果「糟糕」,因为它经常「错漏百出,以可信的方式犯错,并且编造来源」。站长网2023-11-27 10:10:410000全球最大盗版网站Fmovies被关闭 盗版流媒体迎来重创
近日,创意与娱乐联盟(ACE)和好莱坞电影协会(MPA)在打击数字盗版方面取得重大进展。ACE,这个由亚马逊、迪士尼和华纳兄弟等超过50家大型娱乐公司和制作工作室组成的联盟,对关闭Fmovies这一全球最大的盗版流媒体网站负有部分责任。据《好莱坞报道》消息,河内警方已逮捕两名与该运营有关的嫌疑人。站长网2024-08-31 16:53:320000今年双十一,B站直播带货能否真正“出圈”?
“电商年度大考”一年比一年长。天猫、京东不约而同地在10月14日启动双11,相比前两年提前了10天左右;拼多多则在10月8日宣布开启今年双11的百亿补贴;新兴电商平台小红书10月12日开启购物狂欢,快手则在10月16日即进入“双11”预热期,18日正式开售。值得一提的是,抖音凭一己之力拉长了双11的战线。从10月8日到返场期,抖音今年双11预计持续到11月30日,跨度达一个半月之久。0000










