套壳丑闻让斯坦福AI Lab主任怒了!抄袭团队2人甩锅1人失踪、前科经历被扒,网友:重新认识中国开源模型
斯坦福团队抄袭清华系大模型事件后续来了——
Llama3-V团队承认抄袭,其中两位来自斯坦福的本科生还跟另一位作者切割了。
最新致歉推文,由Siddharth Sharma(悉达多)和Aksh Garg(阿克什)发出。
不在其中、来自南加利福尼亚大学的Mustafa Aljadery(简称老穆)被指是主要过错方,并且自昨天起人就失踪了:
我们希望由老穆首发声明,但自昨天以来一直无法联系到他。
悉达多、我(阿克什)和老穆一起发布了Llama3-V,老穆为该项目编写了代码。
悉达多和我的角色是帮助他在Medium和Twitter上推广这个模型。我俩查看了最近的论文以验证工作的创新性,但我们没有被告知和发现面壁智能先前的工作。
被指跑路的老穆本人,X主页目前已经开启保护锁定状态,申请才能关注:
整体来看,这条致歉推文和昨天那条发出后又急忙删掉的推文内容大差不差,主要是突出了道歉和进一步甩锅。
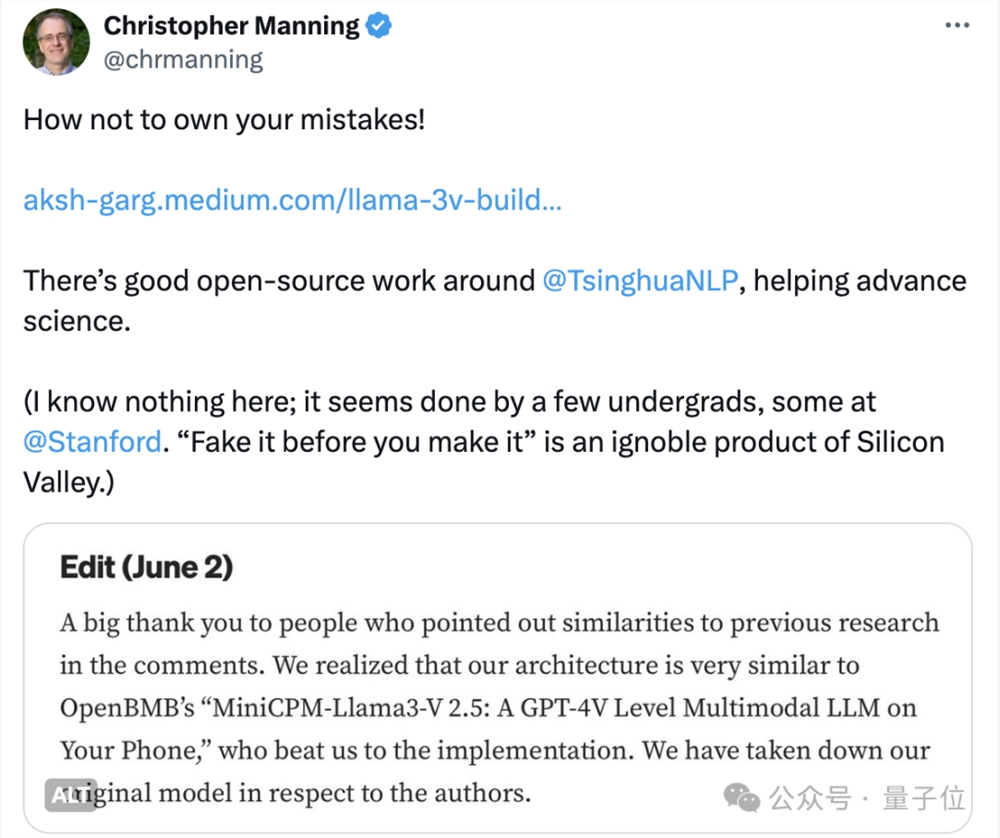
毕竟连斯坦福人工智能实验室主任Christopher Manning都下场开喷:
这是典型的不承认自己错误!
他认为团队在事发后避重就轻,用“架构相似”、“MiniCPM比我们更快实现”的借口推脱,拒不承认是抄袭。
但全新道歉声明,并没有止住网友们的质疑。并且最新爆料还指出,这几位老哥根本就是抄袭惯犯,之前写的教材也是一整个大抄特抄。
而原作者团队面壁智能这边,除CEO李大海昨天回应“也是一种受到国际团队认可的方式”外,首席科学家刘知远也已在知乎出面“亲自答”:
已经比较确信Llama3-V是对我们MiniCPM-Llama3-V2.5套壳。
人工智能的飞速发展离不开全球算法、数据与模型的开源共享,让人们始终可以站在SOTA的肩上持续前进。我们这次开源的MiniCPM-Llama3-V2.5就用到了最新的Llama3作为语言模型基座。而开源共享的基石是对开源协议的遵守,对其他贡献者的信任,对前人成果的尊重和致敬,Llama3-V团队无疑严重破坏了这一点。他们在受到质疑后已在Huggingface删库,该团队三人中的两位也只是斯坦福大学本科生,未来还有很长的路,如果知错能改,善莫大焉。
新的证据
还是先来简单回顾一下这个大瓜。
一句话总结就是,有网友发现,最近在开源社区大火的斯坦福团队多模态大模型Llama3-V,架构和代码与国产MiniCPM-Llama3-V2.5几乎一毛一样,并列举了诸多证据直指Llama3-V抄袭。
随着事件逐渐发酵,斯坦福AI团队删库跑路,面壁智能团队也就此事展开了调查。
面壁智能首席科学家、清华大学长聘副教授刘知远给出的判断Llama3-V是MiniCPM-Llama3-V2.5套壳的一大理由,正是对于清华简的识别能力。
这是MiniCPM-Llama3-V2.5的“彩蛋”能力,是他们用了从清华简逐字扫描并标注的数据集训练的,并未公开。而Llama3-V的表现和MiniCPM-Llama3-V2.5一模一样,不仅做对的题一样,出错的地方都一样。
今天,在第一波证据的基础之上,又有其他网友扒出了新线索。
有人研究后发现,Llama3-V几乎每一层的权重差值都符合均值为0、标准差为1.4e-3的高斯分布。
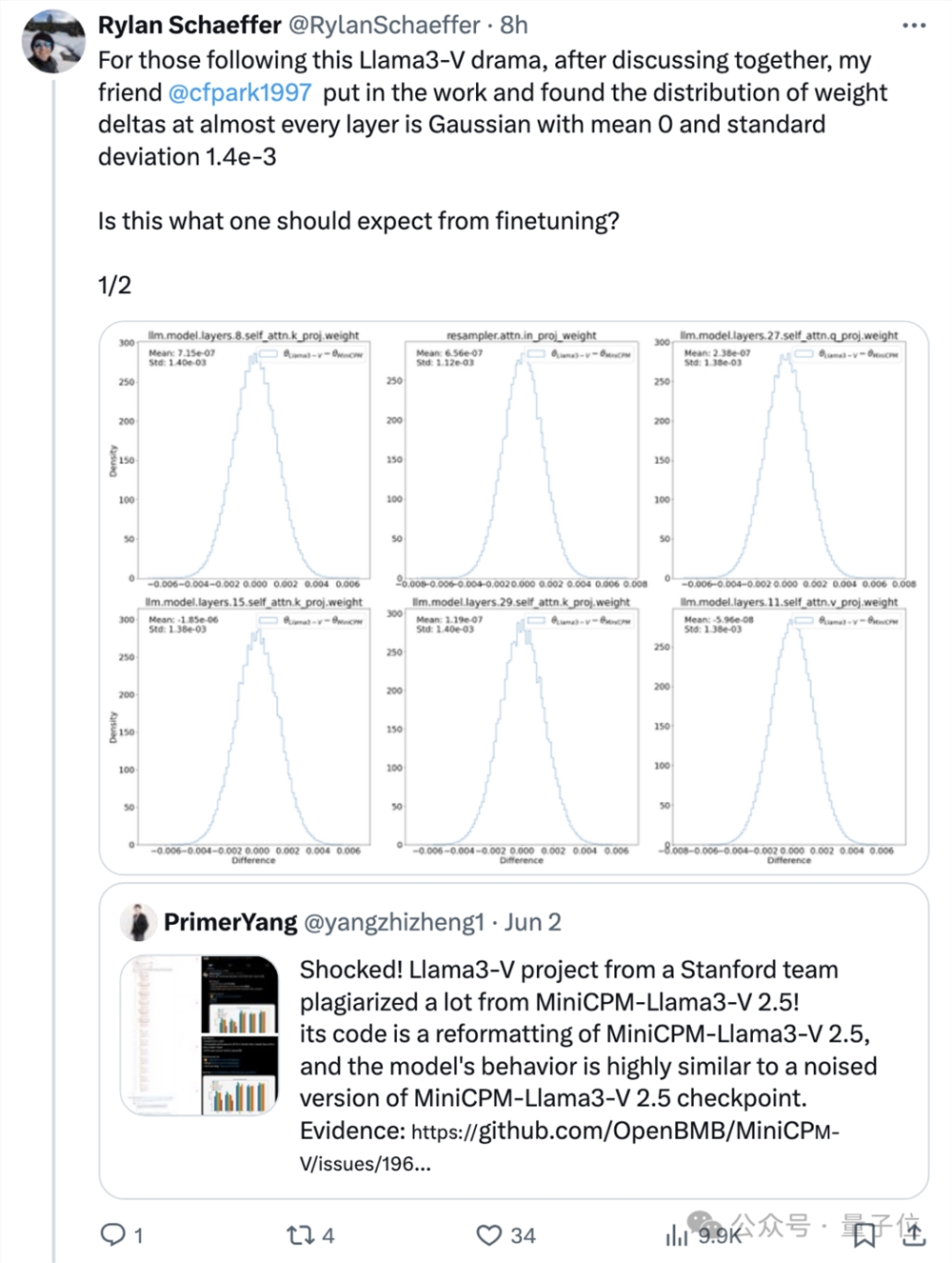
于是推测,Llama3-V只是直接在MiniCPM的权重上添加了低方差噪声。
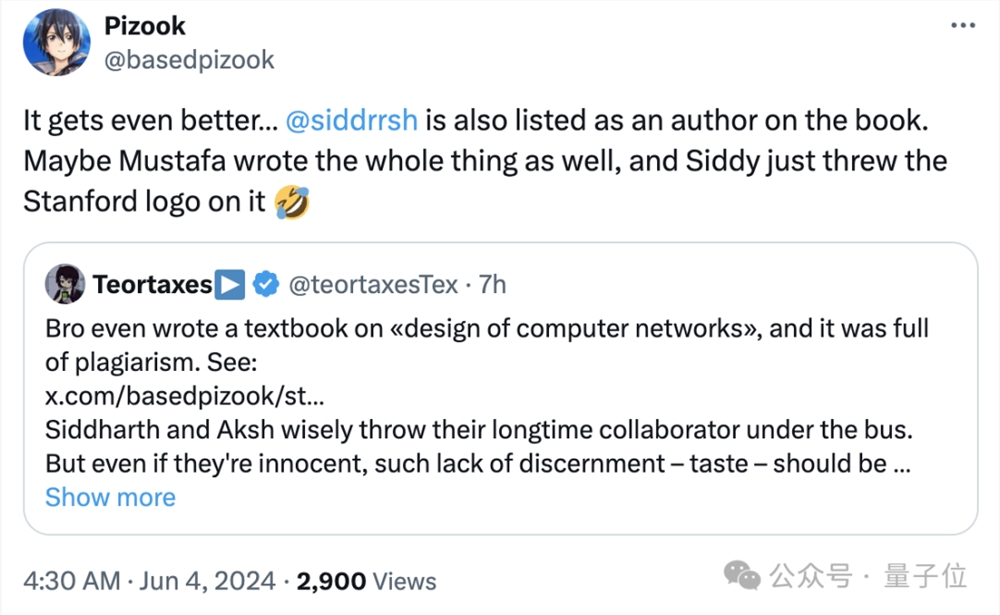
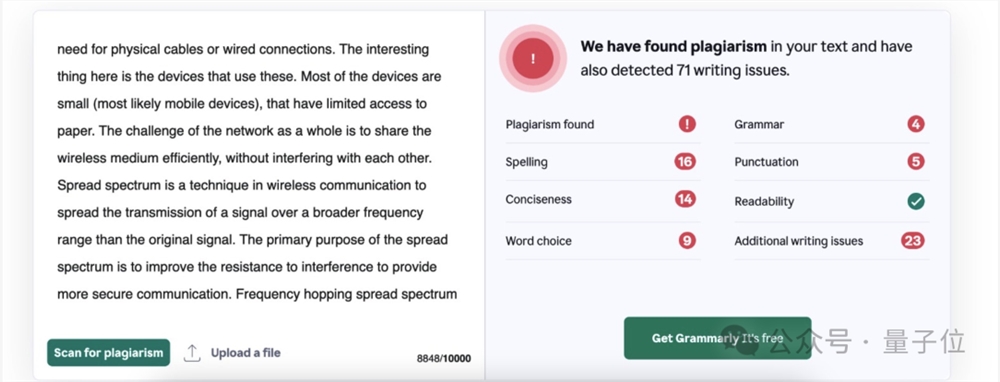
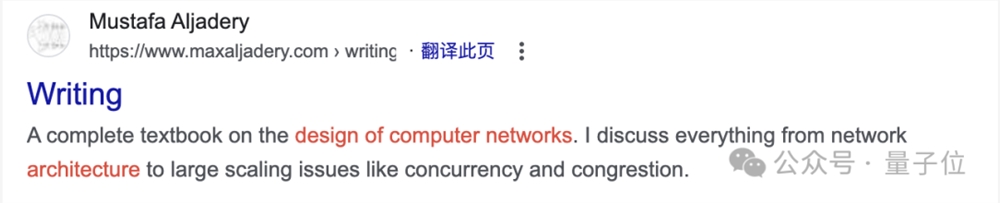
除此之外,那个跑路的大兄弟老穆还被曝之前写了本关于“计算机网络设计”的书,也是抄的。
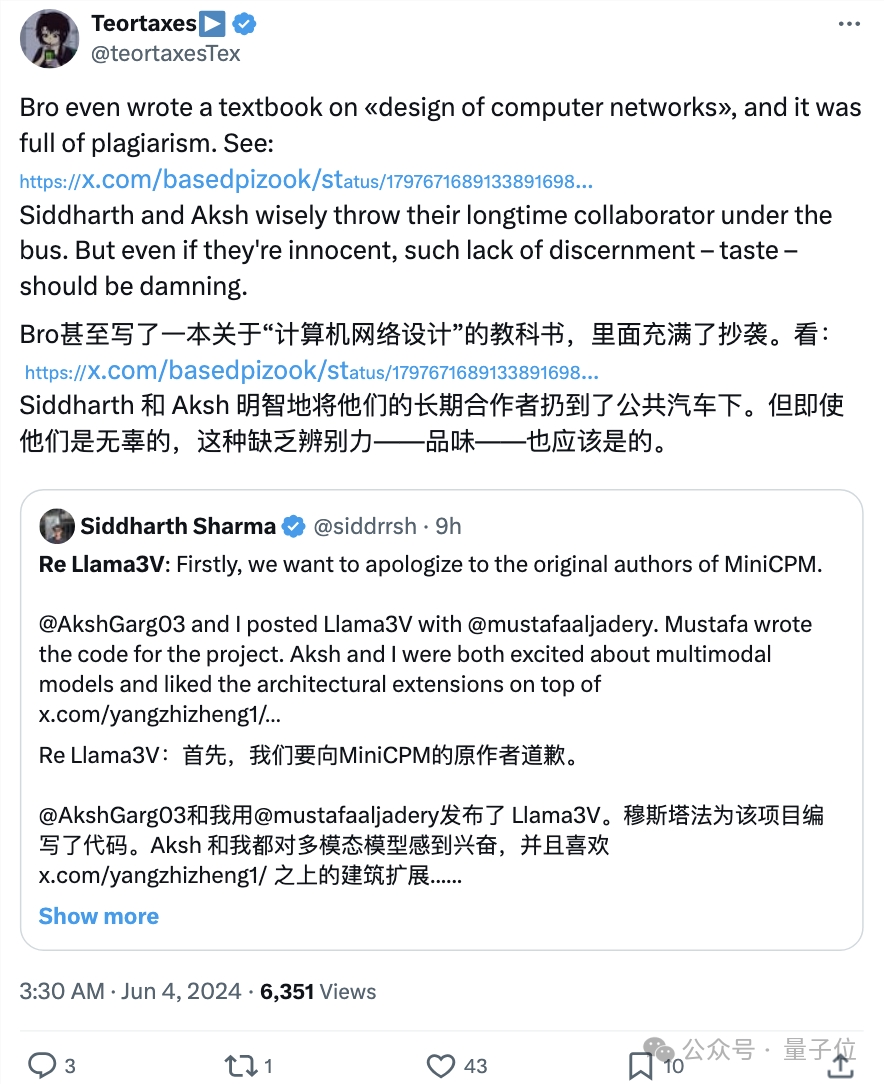
从书中随便抽出一章,用抄袭检测器检测一下就是一堆红点:
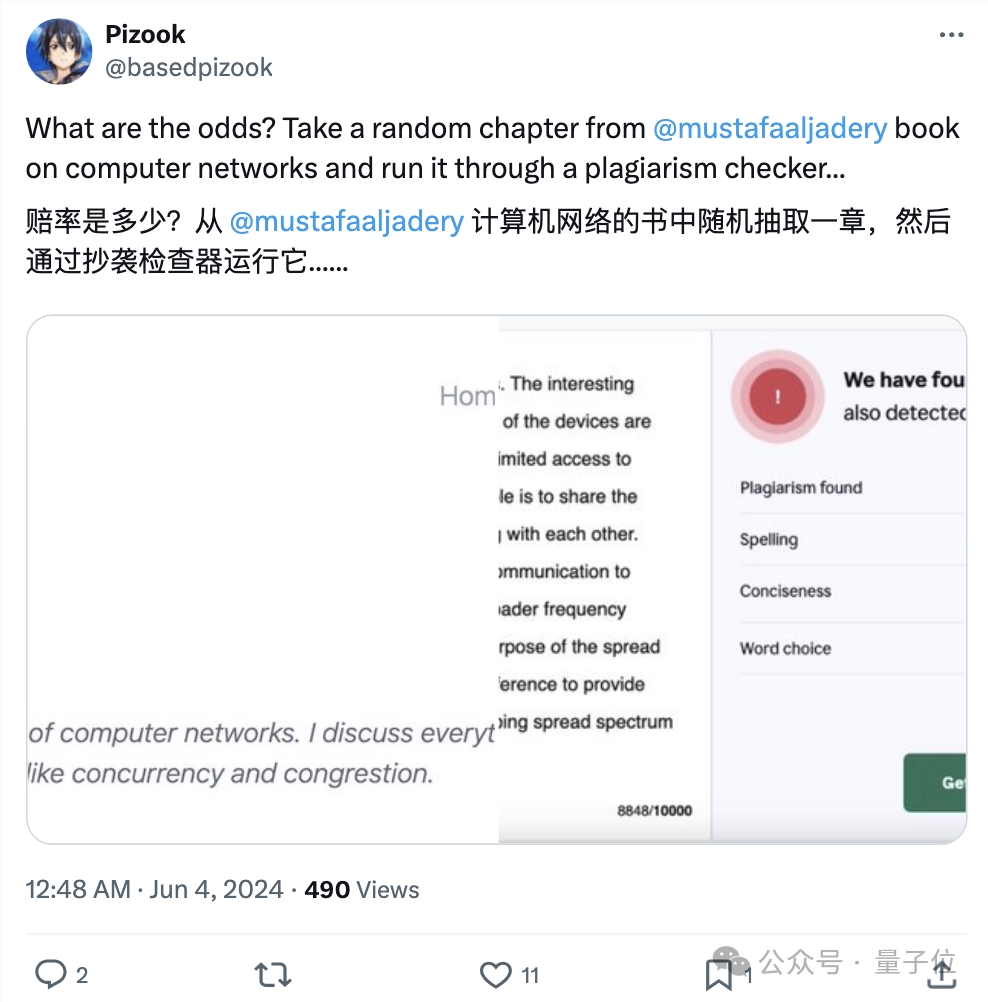
以及,这本书的作者栏里,据网友爆料也有悉达多的名字。
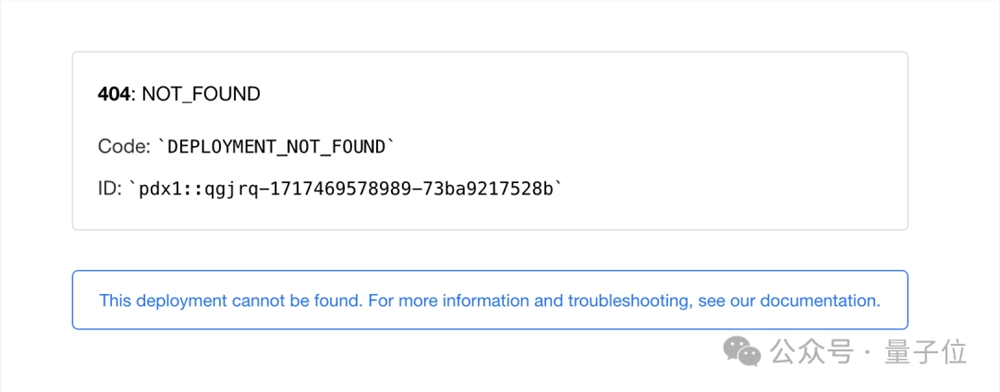
也有网友认为抄书这事儿是不是真的还有待考究。不过,现在这本书也404了。
说回这次的抄袭,悉达多和阿克什的致歉声明中也有提到他们之所以和穆哥一起宣传这个项目,最初也是被这个多模态模型惊艳到了,特别喜欢穆哥所描述的基于Idefics、SigLip和UHD的架构扩展。

但实际上网友一早扒出Llama3-V在空间模式等很多方面的具体实现都和LLaVA-UHD不同,却跟MiniCPM-Llama3-V2.5出奇一致。
根据MiniCPM-Llama3-V2.5主页介绍,MiniCPM-Llama3-V2.5是面壁智能MiniCPM-V系列的最新开源模型,基于SigLip-400M和Llama3-8B-Instruct构建,总共8B参数。
从性能上讲,MiniCPM-Llama3-V2.5在OpenCompass上取得了65.1的平均分,性能超过如GPT-4V-1106、Gemini Pro、Claude3、Qwen-VL-Max等专有模型,且显著超越其他基于Llama3的多模态语言模型。
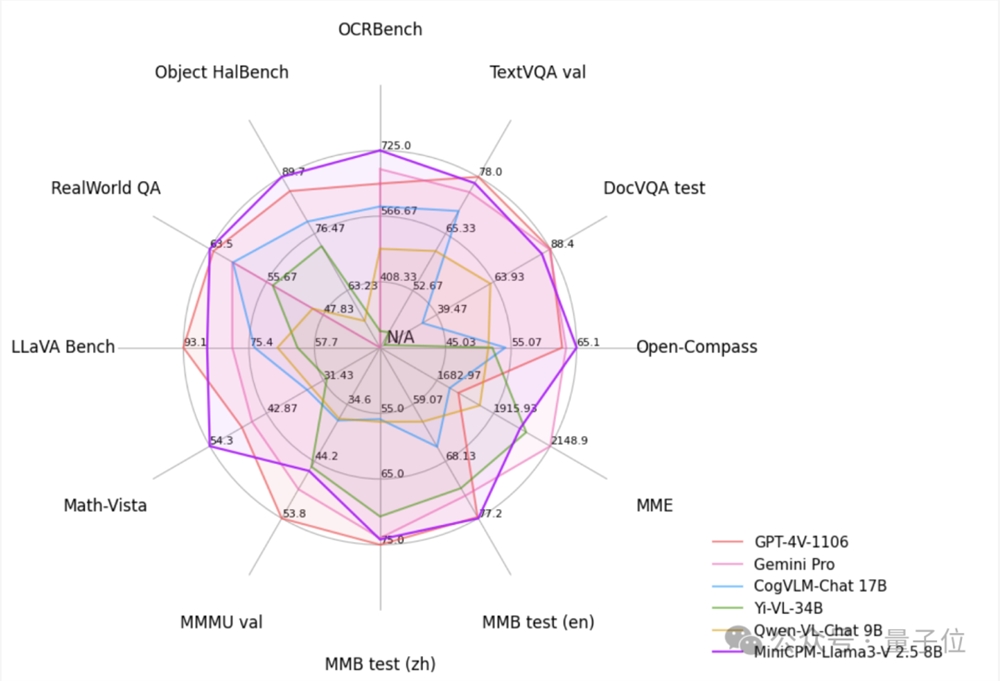
此外,MiniCPM-Llama3-V2.5的OCR能力也很强,在OCRBench上得分700 ,超越GPT-4o、GPT-4V-0409、Qwen-VL-Max和Gemini Pro。

基于最新的RLAIF-V方法,MiniCPM-Llama3-V2.5在Object HalBench上的幻觉率为10.3%,也低于GPT-4V-1106的13.6%。
“中国大模型被忽视了”
尽管甩锅甩得飞快,但网友们很快又从阿克什和悉达多童鞋的道歉声明里发现了华点:
合着你俩啥也没干,帮着搞搞推广就算项目作者啦?
宣发的时候说是你们仨的项目,出事了就把锅全甩给一个人?
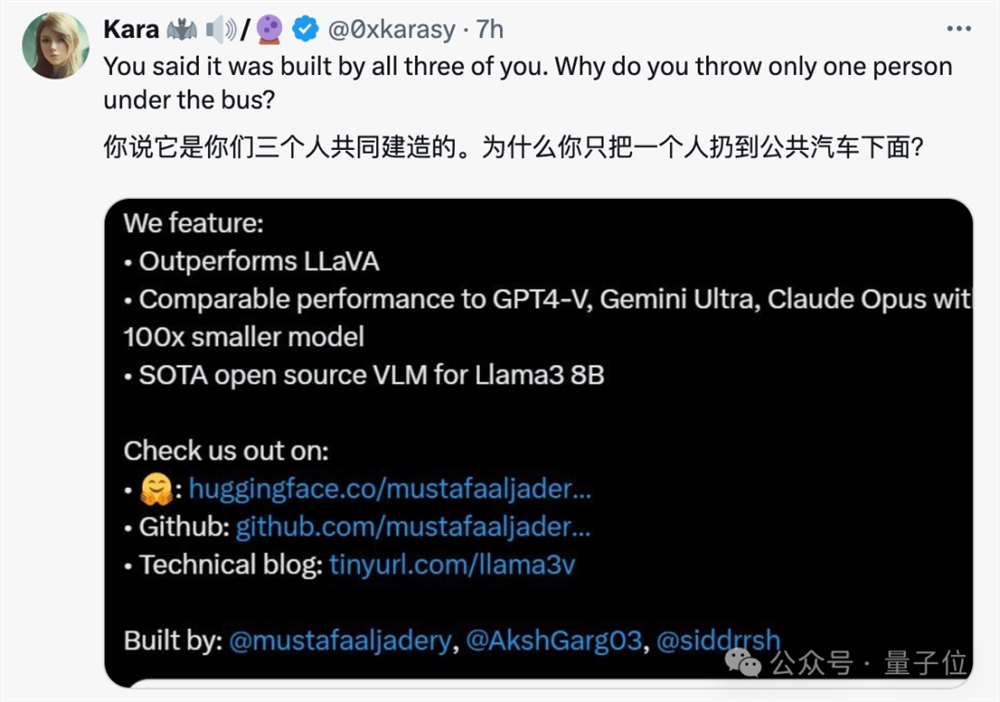
如果是老穆一个人写了所有代码,那你俩是干啥的,就发发帖吗?
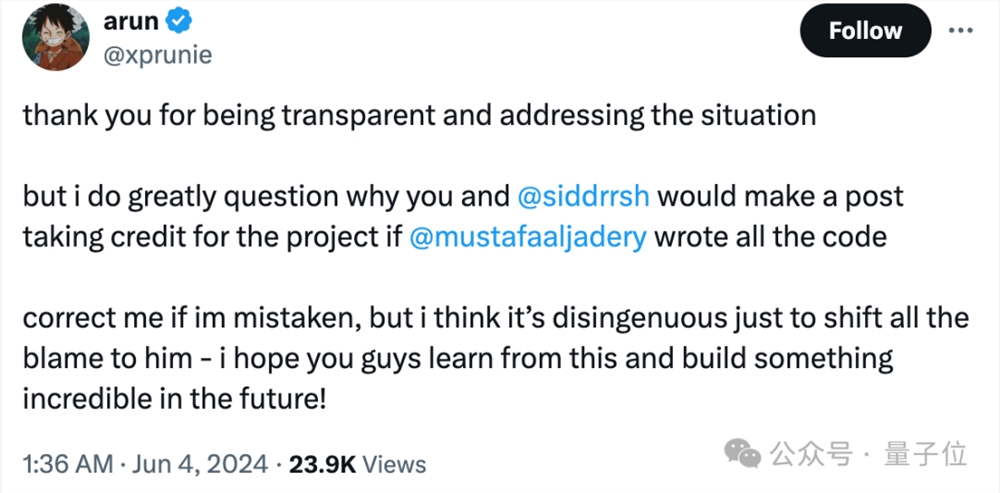
还有网友挑起了一个更关键的话题,进一步引发热议——
开源社区是否忽视了来自中国的大模型成果?
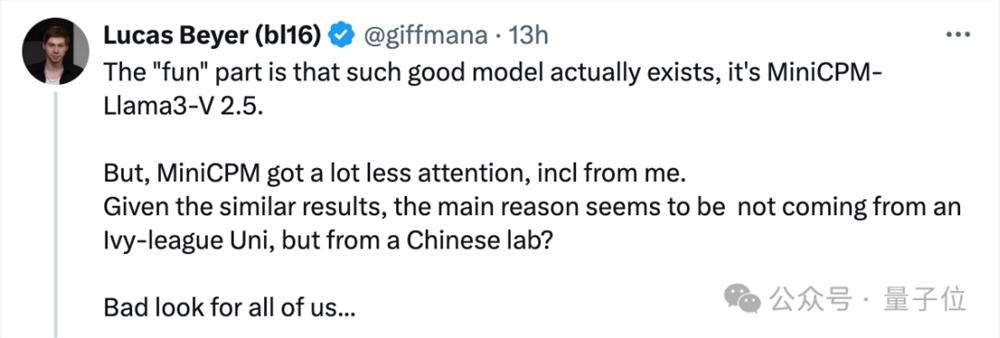
谷歌DeepMind研究员、ViT作者Lucas Beyer就提到,Llama3-V是抄的,但成本低于500美元,效果却能直追Gemini、GPT-4的开源模型确实存在:
但相比于Llama3-V,MiniCPM得到的关注要少得多,包括我自己也有所忽略。
主要原因似乎是这样的模型出自中国实验室,而非常春藤盟校。
抱抱脸平台和社区负责人Omar Sanseviero说的更加直接:
社区一直在忽视中国机器学习生态系统的工作。他们正在用有趣的大语言模型、视觉大模型、音频和扩散模型做一些令人惊奇的事情。
包括Qwen、Yi、DeepSeek、Yuan、WizardLM、ChatGLM、CogVLM、Baichuan、InternLM、OpenBMB、Skywork、ChatTTS、Ernie、HunyunDiT等等。

对此,不少网友表示赞同,“他们推出了目前最好的开源VLM”。

从更客观的大模型竞技场的角度看,此言不虚。
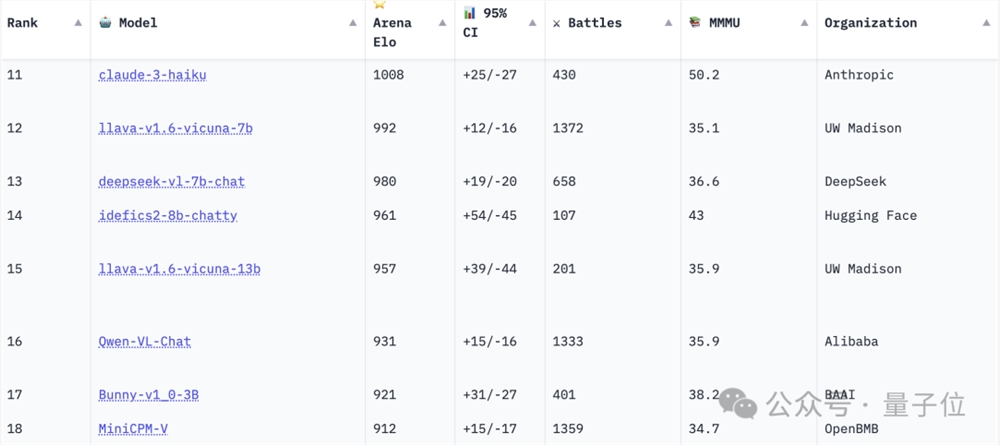
在模型一对一PK的视觉大模型竞技场中,来自零一万物的Yi-VL-Plus排名第五,超过了谷歌的Gemini Pro Vision。智谱AI和清华合作的CogVLM也跻身前十。
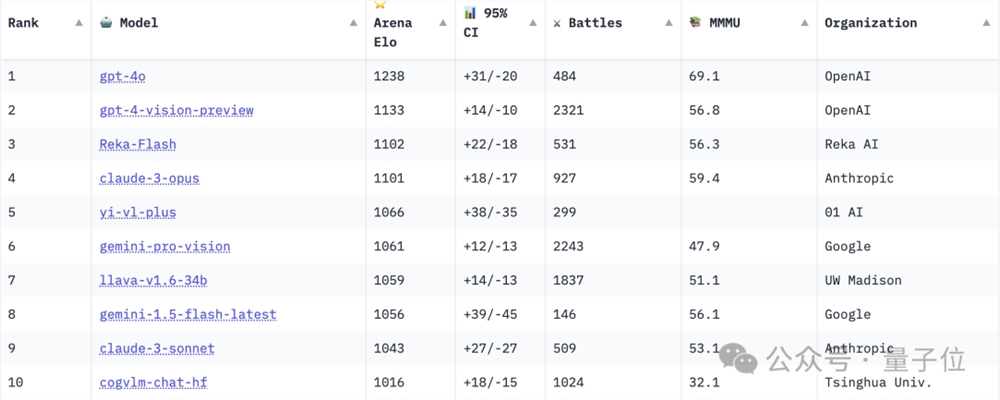
此外,DeepSeek、通义千问和这次遭到抄袭的MiniCPM系列多模态模型,也都有不错的表现。
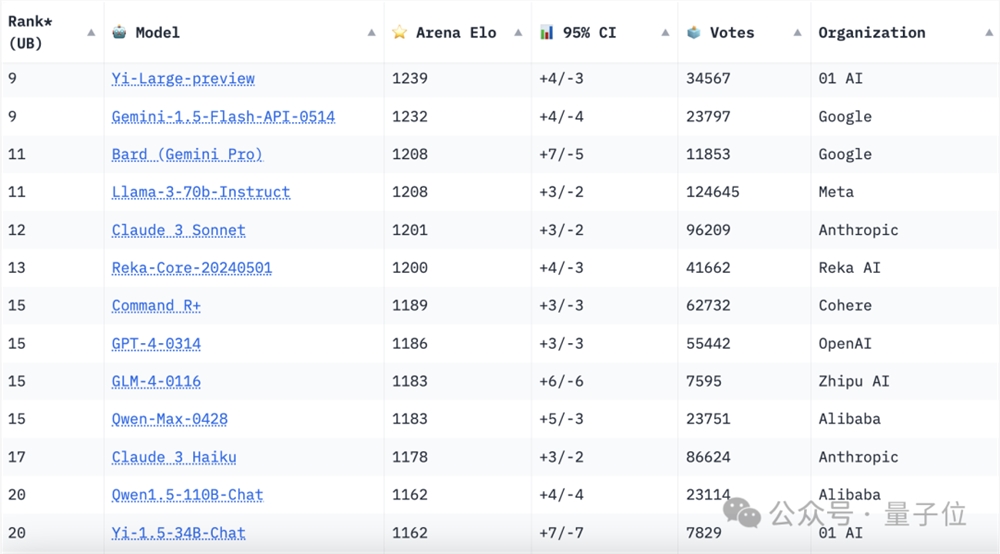
在更受到广泛认可的LMSYS Chatbot Arena Leaderboard竞技场榜单中,来自中国的大模型也同样在不断刷新“最强开源”的新纪录。
正如刘知远老师所说:
从横向来看,我们显然仍与国际顶尖工作如Sora和GPT-4o有显著差距;同时,从纵向来看,我们已经从十几年前的nobody,快速成长为人工智能科技创新的关键推动者。
此瓜甚巨,吃瓜者众,或许更重要的是,一些成见正在破壁。你觉得呢?
MiniCPM原论文
https://arxiv.org/abs/2404.06395
参考链接:
[1]https://x.com/AkshGarg03/status/1797682238961914370
[2]https://x.com/siddrrsh/status/1797682242145464814
[3]https://x.com/teortaxesTex/status/1797712605286645846
[4]https://x.com/chrmanning/status/1797664513367630101
[5]https://x.com/RylanSchaeffer/status/1797690302167417322
[6]https://x.com/giffmana/status/1797603355919028547
[7]https://x.com/RylanSchaeffer/status/1797690302167417322
[8]https://x.com/osanseviero/status/1797635895610540076
[9]https://huggingface.co/spaces/WildVision/vision-arena
我科学家发现田螺科新属
站长网2023-05-24 12:07:160001真我GT5 Pro预售卖断货 官方:已紧急加单
真我GT5Pro是一款备受关注的新品,据官方消息,该产品已在各大平台开启预售,起售价为3298元。在预售当天,部分版本甚至出现了卖断货的情况。据官方数据显示,真我GT5Pro预售1小时的销量已经超过了GTNeo5预售全天的销量。realme副总裁徐起表示,针对缺货的版本已经进行了加单处理,同时提供了赤岩、皓月和星夜三种配色可选。这也进一步证明了真我GT5Pro的市场需求量之大。0000Gurman:苹果已经在研发配备 M3 芯片的 13 英寸和 15 英寸 MacBook Air
据彭博社的MarkGurman报道,苹果已经在开发搭载M3芯片的13英寸和15英寸MacBookAir机型。在他今天的「PowerOn」newsletter中,Gurman表示他预计这些更新后的笔记本电脑将于2024年发布。站长网2023-06-12 16:57:380000月流水过亿后再出续作,网易想做的“自有IP+消除”已经被这家海外小厂跑通了?
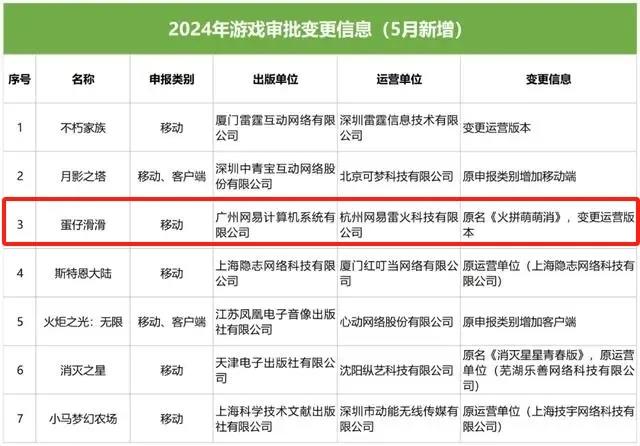
在高人气之后,打造IP也就成了顺理成章的一步,将「蛋仔」从PartyGame辐射到其它游戏品类。从最近的消息来看,《蛋仔》要拓展的第一个新品类是三消。「蛋仔滑滑」很可能是《蛋仔》IP三消游戏新品的正式名称|图片来源:游戏陀螺站长网2024-06-12 16:02:540000新AI窗口红利:员工服务的客户量增了7倍
今年,我们看到了很多关于AI层面的信息,无论是平台还是品牌,服务商还是工具商,在AI这个话题上的答案几乎趋于一致:用。在谈到AI为企业带来的提效之前,我们先来看一组数据。在提到AI营销领域时,有76.3%的用户认为急需AI内容营销功能,有46.4%的用户提到AI用户运营功能。0000