大型科技公司拥才有承担 AI 训练数据成本的能力
划重点:
⭐️ AI 模型训练数据的重要性越来越显著,使得除了最富有的科技公司外,其他公司难以承担成本。
⭐️ 数据采集与整理对生成式 AI 的改进至关重要,这为大型科技公司带来了竞争优势。
⭐️ 尽管一些非营利组织正在尝试开放式数据集的创建,但大型科技巨头仍占据着 AI 训练数据市场的主导地位。
AI 的发展离不开数据,而这种数据的成本越来越高,这使得除了最富有的科技公司外,其他公司难以承担这一成本。根据去年 OpenAI 的研究人员 James Betker 的文章,AI 模型的训练数据是决定模型能力的关键因素。传统的 AI 系统主要是基于统计机器,通过大量示例来猜测最 “合理” 的数据分布,因此模型所依赖的数据量越大,性能就越好。

AI 研究非营利机构 AI2的高级研究科学家 Kyle Lo 指出,Meta 的 Llama3模型在数据量方面明显优于 AI2的 OLMo 模型,这解释了其在许多流行 AI 基准测试中的优势。然而,并不是数据量越大,模型性能就会线性提升,数据质量和整理同样重要,有时甚至比数量更重要。一些 AI 模型是通过让人类标注数据来进行训练的,质量较高的标注对模型性能有巨大影响。
然而,Lo 等专家担心,对大型、高质量训练数据集的需求将 AI 发展集中在少数具备数十亿美元预算的公司手中。尽管一些非法甚至犯罪行为可能会对数据获取方式提出质疑,但技术巨头凭借资金实力能够获取数据许可。这些数据交易的过程并未促进一个公平开放的生成式 AI 生态系统,让整个 AI 研究社区备受其害。
一些独立、非营利性的组织尝试开放大规模数据集,如 EleutherAI 和 Hugging Face,但它们是否能赶上大型科技公司的步伐仍是一个未知数。只有当研究突破技术壁垒,数据收集和整理成本不再是问题时,这些开放性的数据集才有希望与科技巨头竞争。
文本直接生成2分钟视频,即将开源模型StreamingT2V
Picsart人工智能研究所、德克萨斯大学和SHI实验室的研究人员联合推出了StreamingT2V视频模型。通过文本就能直接生成2分钟、1分钟等不同时间,动作一致、连贯、没有卡顿的高质量视频。虽然StreamingT2V在视频质量、多元化等还无法与Sora媲美,但在高速运动方面非常优秀,这为开发长视频模型提供了技术思路。站长网2024-04-06 14:18:290000华为三折叠Mate XT非凡大师正式发布 售价19999元起
华为在今日下午的发布会上正式推出了全球首款量产的三折叠手机——华为MateXT非凡大师,起售价为19999元,将于9月20日上午10:08正式开售。这款手机以其10.2英寸的超大屏幕成为全球最大的折叠屏手机,提供了瑞红、玄黑两种配色,以及16GB256GB、16GB512GB、16GB1TB三种存储版本供消费者选择。站长网2024-09-12 02:31:460000虚拟摄像头应用xpression camera 可实时生成虚拟形象
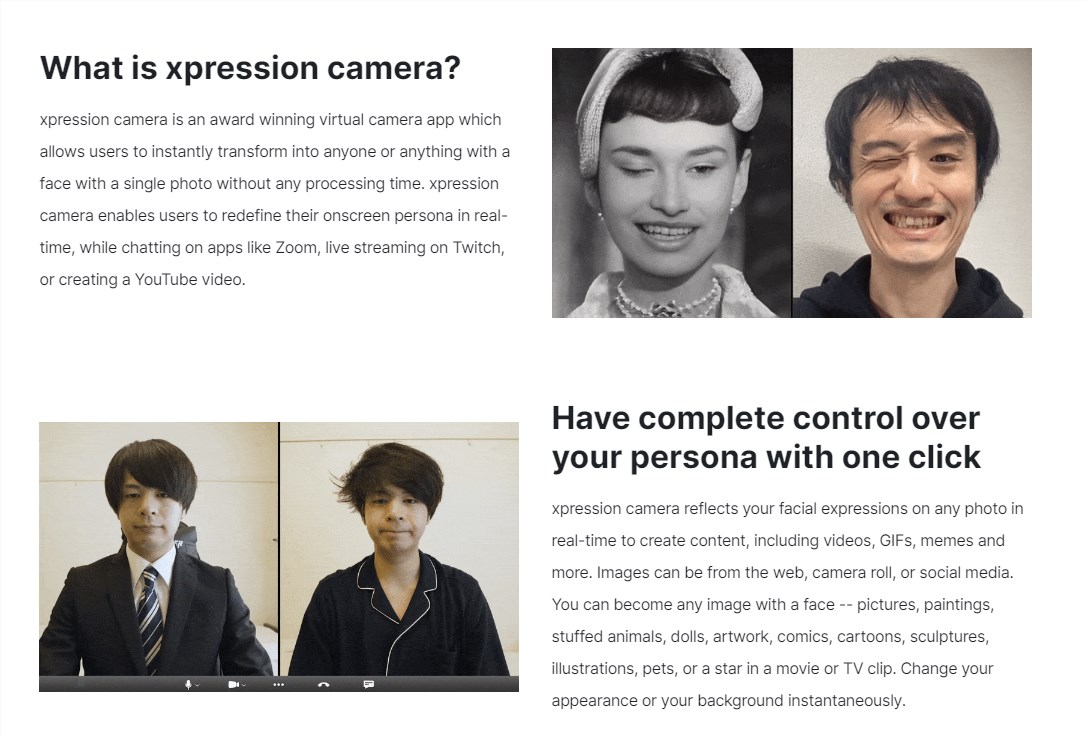
xpressioncamera是一款获奖的虚拟摄像头应用程序,可以让用户使用单张照片即刻变身成任何有脸的角色,无需等待处理时间。这个应用允许用户在实时视频通话和直播过程中重新定义他们的屏幕形象,无论是在Zoom上聊天、Twitch上直播,还是制作YouTube视频。官网地址:https://xpressioncamera.com/产品亮点:站长网2023-10-30 17:08:040000SimDA:一种高效视频生成方法
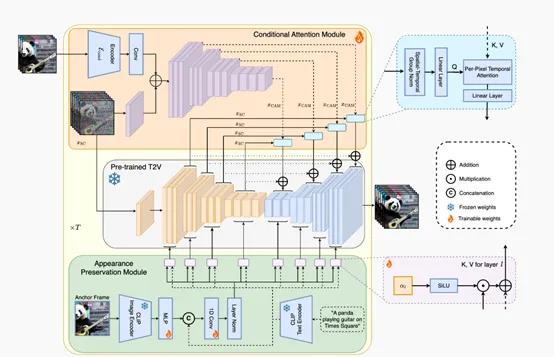
来自中国科学院自动化研究所、腾讯公司和香港中文大学的研究人士提出了一种名为SimpleDiffusionAdapter(SimDA)的方法,用于实现高效的文本到视频生成。传统的文本到视频技术发展还不够成熟,而SimDA方法通过只fine-tune部分参数,将T2I模型转化为T2V模型,实现了高效的视频生成。站长网2023-08-21 22:16:480000周星驰拍短剧,上线第一集已入账3000万?
微短剧市场正在迎来“正规军”,这一次,来的是周星驰。6月2日,周星驰出品的短剧《金猪玉叶》上线,开播首小时播放量即破百万,截至发稿前,更新的第一集已经引起业内的广泛关注,两天时间播放量就超过了3100万。站长网2024-06-06 17:43:000001