谷歌发布开源视觉语言模型PaliGemma 支持多视觉语言任务
站长网2024-05-17 11:19:581阅
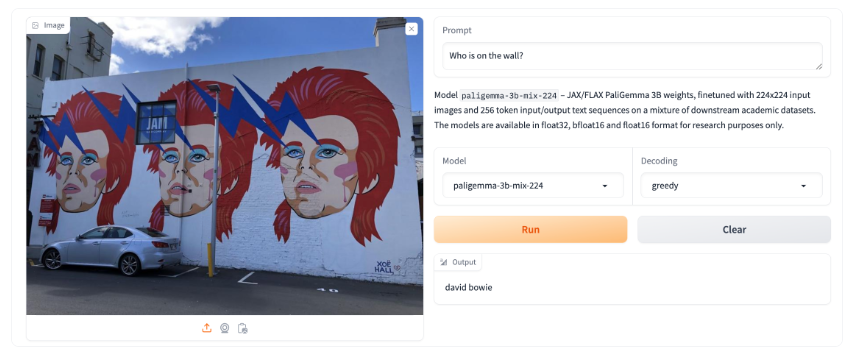
谷歌推出了一款名为PaliGemma的开源视觉语言模型,该模型结合了图像处理和语言理解的能力,旨在支持多种视觉语言任务,如图像和短视频字幕生成、视觉问答、图像文本理解、物体检测、文件图表解读以及图像分割等。
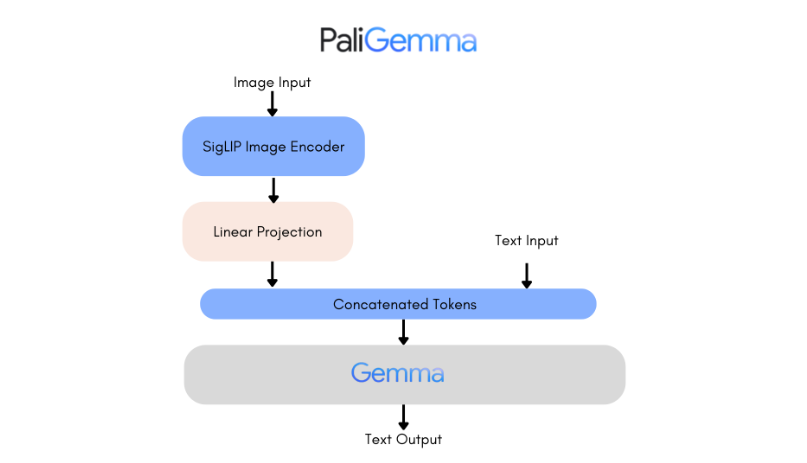
PaliGemma的关键特点:
多任务支持:PaliGemma能够处理多种视觉语言相关的任务,提供广泛的应用场景。
参数规模:该模型包含30亿(3B)个参数,是一个大型的多模态模型。
模型架构:PaliGemma结合了SigLiP视觉编码器和Gemma语言模型,分别负责处理图像和文本输入。
SigLiP视觉编码器:
负责处理图像输入,将视觉信息编码为模型能够理解的格式。
Gemma语言模型:
负责处理文本输入,并生成输出,将图像内容与语言任务结合起来。
PaliGemma的发布是谷歌在AI领域的又一项重要贡献,它不仅推动了视觉语言理解技术的发展,也为研究人员和开发者提供了强大的工具,以探索和创造新的应用。开源的特性意味着PaliGemma可以被社区广泛地使用、改进和集成到各种产品和服务中。
模型地址:https://huggingface.co/blog/paligemma
0001
评论列表
共(0)条相关推荐
Bored Humans提供Midjourney等100多款主流AI工具的免费平替版本
本文概要:1.BoredHumans是一个拥有100多种免费AI工具的网站,包括图像生成、播客生成、背景去除等,可替代许多付费工具。2.该网站的许多工具具有趣味性和创新性,但AI生成的图像质量通常不如Midjourney等更复杂的模型。3.该网站由美国域名投资者EricBorgos创立,他有25年互联网工具开发经验。站长网2023-08-27 14:16:420000AI 初创公司 Pika 募集 5500 万美元资金,推出 AI 驱动视频编辑平台
站长网2023-11-29 10:58:490000OpenAI 为 DALL-E3添加新水印 以增强数字信息的可信度
随着越来越多的公司支持内容来源和真实性联盟(C2PAImage)标准,OpenAI的生成器DALL-E3将将图像为元数据添加水印。这些水印将出现在ChatGPT网站和DALL-E3模型的API生成的图像中,帮助用户验证图像的来源和制作工具。站长网2024-02-07 09:45:510000当 AI 成为“逆子”:人类该抽丫俩逼兜,还是给它一个拥抱?
(零)内容小提要科学家把AI称为“人类之子”。在我看来,这个比喻意味深长,因为它背后有一串追问:既然AI还是个“未成年人”,那该不该让它工作养家?孩子长大成人显然需要管教,那么管教AI应该用啥方法?当AI真的成年后,我们还应该像约束孩子一样约束它吗?每一代人都有追求自己幸福的权利,AI作为人类的另一种后代,是否也有权追求自己的幸福?站长网2023-09-27 13:55:080007Cerebras 推出 4 Exaflops Condor Galaxy 1 AI 超级计算机:超过 70,000 个 AMD EPYC 核心、5400 万个 AI 核心
Cerberas和G42推出了4ExaflopsCondorGalaxy1AI超级计算机,其中包含数千个AMDEPYC处理器单元和数百万个AI核心。图片来自Cerebras站长网2023-07-24 15:03:170000