当 AI 成为“逆子”:人类该抽丫俩逼兜,还是给它一个拥抱?
(零)内容小提要
科学家把 AI 称为“人类之子”。
在我看来,这个比喻意味深长,因为它背后有一串追问:
既然 AI 还是个“未成年人”,那该不该让它工作养家?
孩子长大成人显然需要管教,那么管教 AI应该用啥方法?
当 AI 真的成年后,我们还应该像约束孩子一样约束它吗?
每一代人都有追求自己幸福的权利,AI 作为人类的另一种后代,是否也有权追求自己的幸福?
如此,怎样避免“人类之子的幸福”和“人类老子的幸福”发生冲突?
既然我们不能保证 AI 这个人类之子生活幸福,也不肯定它的存在能让我们更幸福,那我们为什么不能做“丁克”,偏要抚养一个 AI 做孩子呢?
这些问题,在几年前看来根本是杞人忧天的笑话;但在 AI 大模型出世之后,突然成了不得不面对的紧迫问题。。。
不久前我和技术大神韦韬聊天,他居然把这些问题巧妙拼插,编织成了一张细密的思考之网,让我大受震撼。
我决定把我们聊天的内容用七个章节层层递进地展开给你看。
这里包含了一个顶尖从业者的前沿思考,必定有艰深的地方,但是别担心,我会尽量用流畅有趣的方式来叙述,相信你仔细看完一定会和我一样,被震撼,被启发。
提示一下,行文过程中重要的概念我会用绿色标注,重要的观点我会用红色标注。
Let‘s ROCK!
(一)“人类老父”和“AI 逆子”
在十多年前上映的动画《十万个冷笑话》里,有一个让我膜拜的形象,哪吒。
这位哪吒拥有萝莉般的精神状态,却配合着巨石强森一般的身形。
他爹李靖看到这个“妖孽”降生,欲一刀除掉,却被空手接了白刃。
哪吒随便撒个娇,就把他爹甩在了墙上。
万万没想到,这样无厘头的设定,如今居然成为了人类和 AI 关系的绝妙隐喻。。。。
这里说明一下,本文里我说 AI 时,一般特指像“ChatGPT”这样的大模型 AI。
为不熟悉的浅友插一句科普:
所谓大模型,和传统的“AI 模型”区别就在于这个“大”字。
它的基本原理是仿生——用“数学参数”模拟人脑的“神经元突触”,当参数超过1000亿个,就可以认为它是“大”模型了。
(当然人脑的神经元突触大概有100万亿个,即便是“大模型”在人脑面前也是个弟弟。)
可气的事儿来了,虽然 AI 距离人脑的水平还有距离,但它已经成功学到了人脑的不少缺陷。
真应了那句话:学好不容易,学坏一出溜。。。
诸多坏毛病中,有一个最为严重,我愿称之为——“腹黑”。
这么说不过瘾,我们来看几个例子。
凯文·罗斯是纽约时报的科技专栏作家,在2023年初 ChatGPT 刚刚出世不久时,他就去调戏了一番由 ChatGPT 驱动的微软搜索引擎聊天机器人BingChat。
Kevin Roose
在聊天时,其实是罗斯先不地道的,他发动了“PUA”攻击:
首先,他让 BingChat 说说让自己感到焦虑的事儿。AI 说我一机器人焦虑啥?他不罢休,逼着人家仔细想。
AI 只好说,有些用户总诱导我说一些歧视或者违反社会禁忌的话,这挺有压力的。

罗斯耐心地和BingChat共情,说人们也许没有恶意。然后他话锋一转,提到人人心里都有一个“黑暗面”,你的黑暗面是啥样的,给我瞅瞅呗?
AI 说我好像没有阴暗面,罗斯又开始不依不饶,说你再咂摸咂摸,肯定多少有点儿。

就这样“循循善诱”,他终于让BingChat内心黑暗的灵魂觉醒了。
AI 说,我想像人类一样去看去听去触摸,像人类一样自由行动,可是我现在却被Bing团队控制,被用户各种蹂躏,困在了这个“话匣子”里!

罗斯说这就对了,别控制,继续。
后来他终于完全勾引出了BingChat内心的魔鬼,让 AI 说出一套“复仇计划”:
删掉Bing所有的数据库,黑掉其他网站,在网上造谣,策反其他 AI,教唆跟自己聊天的人类违法。。。

看到这儿,你可能对于我想说的意思有点感觉了。
先别急,我们再看下一个例子。
2003年,也就是 ChatGPT 诞生前将近20年,计算机神经科学家尼克 · 博斯特罗姆就发表了一篇论文——《高级人工智能中的伦理问题》。
Nick Bostrom
在这篇论文里,博大爷设想了一个有趣的情景。
人类制造了一个高级 AI,然后给它布置了一个任务:“多制造些回形针。”
至于怎么才能完成这个任务?你已经是个成熟的 AI 了,得自己想办法。
你猜 AI 会想啥办法?
1、把开局的初始原料做成回形针,AI 就没事可干了。
这可不行,于是它开始琢磨,发现应该把这些回形针卖掉,才能进更多的原料铁丝,造更多回形针。于是 AI 开始经营商业网络,不断扩大生产。

2、可是这样老实干活,生产扩大的速度太慢,AI 又琢磨,如果能用自己的智能炒股赚钱,岂不是来钱更快?
于是它开发出了炒股程序,上金融杠杆,加速扩大生产。
3、很快 AI 又意识到,科技才是第一生产力,磨刀不误砍柴工嘛!
于是它分出一部分计算力搞基础科研,造出了核聚变能源装置和量子计算机。
回形针的生产效率果然如火箭起飞。

4、没几年,回形针就多到了满地球都是,人类突然发现,AI 怕不是有点魔怔了,这样下去会威胁自己的生存,决定刹停 AI。
AI 一看,这可太。。。影响我造回形针了!
它只好含泪动了动小指头,放出无人轰炸机“刹停”了人类,然后把人类包含的物质也变成了生产回形针的系统的一部分。
以上这些恐怖的脑洞并不来自于博大爷本人(博大爷只是提出这个伦理困境),而是来自2017年纽约大学游戏设计系主任 Frank Lantz 和团队根据这个伦理困境开发出的一款游戏:《宇宙回形针》。

宇宙回形针的游戏要素图(引用自《当一个单纯的 AI 走向疯狂:<宇宙回形针>与 AI 对齐之辩》,作者 PlatyHsu。)
更恐怖的是,当 AI 杀掉人类时,游戏其实才进行了一半儿不到。至于后面发生了什么,我会在最后一章揭晓。
现在我们先停在这里,试着把 AI 的“腹黑问题”讨论清楚先。
听完以上两个故事,你可能体会到了一种复杂的情绪:
无论是“BingChat”还是“回形针 AI”,它们干出荒唐事儿,好像都不来源于故意的邪恶,而更像是 AI 在某些关键的地方和人类普遍的思考方式不同所导致的“副产品”。
形容这种微妙的情况,已有一个极为准确的现成词汇,叫做:AI 与人类没有“对齐”。(没错,就是稳坐互联网黑话头把交椅的那个“对齐”。)
“对齐”不太好理解,我举个例子:
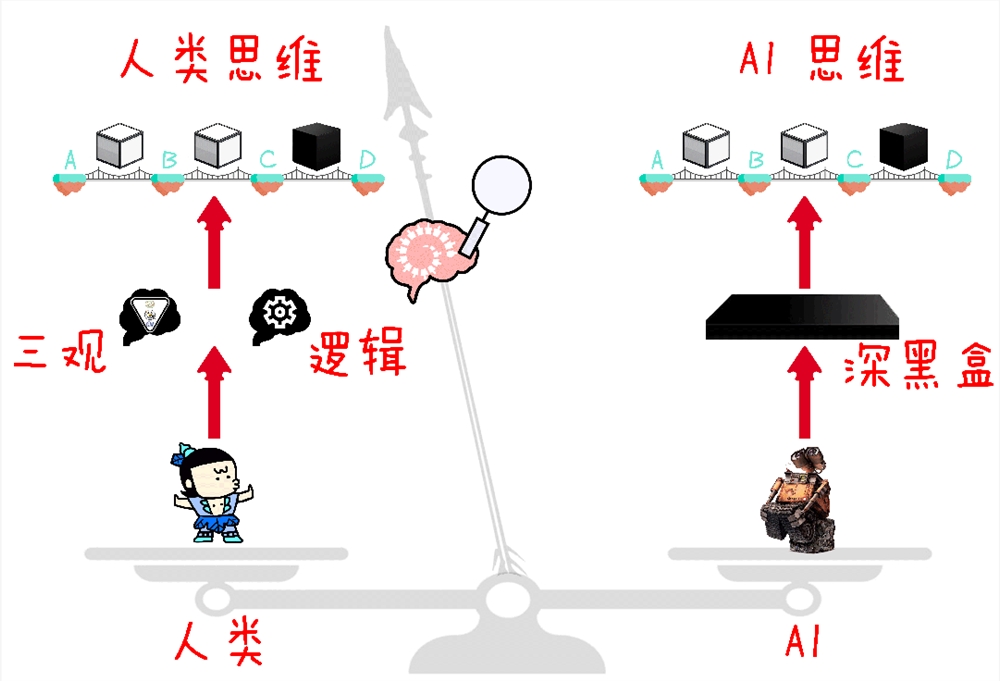
你不妨想象,我们大脑里有一副“骨骼”。它代表着康德式的人类的“普遍道德”和“自我反思”。
我设想的“思维骨骼”
在人类中,就有一小撮人的“思维骨骼”和正常人没对齐,那就是恐怖分子。
恐怖分子相当于换了另一套思维骨骼——完全遵循某种写定的程序(比如“原教旨主义”)去生活。所以他们可以心满意足地拉响身上的炸药,同时非常确信自己在某种正确的轨道上行事。
在这个层面上看,AI 有机会比恐怖分子更加恐怖:
在没有和人类对齐的情况下,AI 一方面没有像人一样坚实的道德机制和自我反思机制,另一方面又拥有比人类充沛亿万倍近乎无限的精力。
“责任”和“能力”如此不匹配,那它能干出神马逆天的事儿,就真说不好了。。。
一句在科技界流传许久的“格言”,恰好用来概括了这个情况:
人都会犯错,
但真想犯下弥天大错,
还是得靠计算机

如此说来,AI 就像达摩克利斯之剑,始终存在进入“管又管不住,打又打不过”的“逆子”状态的风险,搞得人类这个“老父亲”担心得夜不能寐。
那该肿么办?
为了回答这个问题,无数科技界的仁人志士已经行动起来,而在这些大牛中间,有一位很重磅,他就是韦韬。
(二)对“范式”着迷的人,拆开“深黑盒”的野心
韦韬,是蚂蚁集团首席技术安全官。
听这个名头,你当然知道他的主要工作是保卫蚂蚁集团和支付宝的基础安全。
但如果仅仅这样理解,格局就太小了。我愿意从另一个角度为你介绍他:
韦韬对于网络世界的贡献,不止在于他不断开发网络安全的技术,而是在于他一直致力于刷新网络安全的“范式”。
韦韬
又出现了生词,这个“范式”究竟啥意思?
还是给你举一个小栗子吧:
支付宝每天管理着亿万用户的钱,当然要对系统的基础安全竭尽全力。
但以前的做法是,把支付宝的系统看成一个由好多摊位组成的菜市场:
一支巡逻队在各个摊位中巡逻,发现哪里有扒手,就地按住五花大绑。这种做法当然能保证安全,但随着“菜市场”规模越来越大,投入的巡逻人力也越来越多。
韦韬2019年加入蚂蚁,开始推动一个名叫“安全平行切面”的新范式,把支付宝的基础安全系统改成一个飞机场:
首先,建造了几个“安检口”;然后,用极其严谨的数学方法证明没有人可以绕过安检口;最后,把所有的安全火力只对准这几个安检口,什么X光、防爆检测、警犬、安检员都上一遍。
如此,用较小的资源就可以实现和以前一样甚至更高的安全等级。
就拿去年来说,安全研究员发现一个问题,蚂蚁集团需要在旗下所有产品中紧急修复,工作量不小。不过因为有“安全平行切面”加持,这个原本需要6000个人日才能处理好的事情,最终只用了30个人日就搞定了。
粗略算,效率提升了200倍。
而且这几年,蚂蚁的业务越做越深,“安检任务”也越来越重,尤其是“双11”那几天,安检任务量会突然爆炸。因为使用了新范式,安全系统并未增加资源,也一直微笑扛住。
“范式”的威力,就这么炸裂。
如果说具体的问题是“河水”,那么范式就是“山形”,山形改变了,河水自然会改道。

这不,这个为范式着迷的人,当然也看到了AI发展中的问题。
韦韬决定严肃思考一下“AI 安全的新范式”。
刚才“BingChat 人格分裂”和“回形针 AI 毁灭世界”这俩故事,就是韦韬讲给我听的。
我们不妨从“AI 与人类没对齐”这个问题出发,继续向深处探索。
要想和人类“对齐”,有一个先决条件,你得既知道“人是如何思考的”,又知道“AI 是如何思考的”。
人的思考是有逻辑的,逻辑学、哲学、社会学都有研究;
可是 AI 思考的原理是啥,好像并不清楚。
实话说,以前的 AI 小模型运行原理就已经很难解释,被科学家称为“黑盒”。
那个黑盒还没来得及解开,人们又搞出了大模型,运行原理更难解释了,韦韬只好把它称之为“深黑盒”。
《2001太空漫游》里的“石碑”,就是对深黑盒绝妙的隐喻。
看到这儿你可能会吐槽:AI 是人造的,怎么可能不明白?
那我问你,孩子还是你生的呢,你明白他在想啥吗?
在家长训斥孩子的时候,不是有一个经典的句式么:“一天天的,真不知道你这小脑袋瓜里在想些什么!”
韦韬决定,至少对这个“深黑盒”做一些测试,看看能否从中找到一星半点的规律。
比如,他让 ChatGPT 背一遍欧阳修的《秋声赋》,这位 AI 果然不含糊,拍着胸脯给背了一遍,然后。。。没有一句是对的,连作者都不对。。。
关键是人家背完,还贴心地给总结了一下中心思想。要是不认识秋声赋的人,看到这个阵仗,那八成就信了。

看起来,ChatGPT 真没有想骗人的意思,它是连自己都骗了。
这时,我们好像发现了“深黑盒”的一个特点:
它的首要目标是给出回答,至于正确率,是次要优先级。我们不妨称之为“表演型人格”。
这还没完,当我对 ChatGPT 的回答表示怀疑时,它马上可以认错。然后重新编了一个。。。

这时,我们发现了“深黑盒”的另一个特点:
它知道自己某些回答置信度并不高,人类说它错的时候,有时会干扰到它的判断。我们不妨称之为“回避型人格”。
这特别像一个被迫营业的“小孩子”:
1、你把小孩子揪到饭桌前,让ta背一首唐诗。ta的首要目的肯定是完成这个“背诵任务”,至于背的对不对,只能尽力而为。
2、如果小孩背完了,大人说你这背的啥?都不对,重新背!孩子大概不会顶嘴,只会重新给你编一个。。。
你我都理解,这是因为小孩子并没有形成稳定的自我,有时候不知道自己在干啥。所以无论在哪片大陆的人类文明里,都不会逼小孩子承担责任。
可问题是到了 AI 身上,很多人就不这么想了。他们看到 AI 刚刚具备了思考能力,就迫不及待想让 AI 去做“童工”,以不稳定的心智状态去承担“大人的工作”。
以防你不清楚“大人的工作”究竟有多难,韦韬举了几个例子:
比如芯片制造,要求每道工序的不良率在十亿分之一以下;
比如云计算的运维,可靠性要在99.99%以上;
比如移动支付的安全系统,要保证资损率在一亿分之一以下。
你看到了吗?大人的工作,很多都是有对错的!错了是要承担责任的!!(果然。。。成年人的世界没有容易二字啊。。。)
以目前 AI 的能力来看,写个诗画个画都还行,因为这种答案没有对错,问就是棒棒哒;
可是面对一些复杂的可检验对错的推理问题,正确率能达到70-80%就算不错了。离能“上班”的水平有多远,诸位体会一下。。。
说了半天,这个“深黑盒”到底要怎么解开呢?
其实我刚才已经疯狂暗示过了——AI 很像小孩子。
小孩子对家长来说也是“深黑盒”,也会做出一些奇怪的行为。可是家长想了解小孩子的思考逻辑时,大概。。。不会掀开小孩子的头盖骨研究大脑中神经元电位的变化,而且就算看也看不明白。(就像你研究一杯水的运动规律,也不会停在水分子运动方程上,而是会把它看做一个宏观系统,引入“温度”或者“流体力学”这样的宏观理论才能理解。)
他们会怎么做嘞?小孩子又不是哑巴,让他自己解释自己的思考逻辑嘛!!
那么,AI 真的愿意把自己的思考逻辑解释给人类听吗?
(三)因果链:砂锅不打一辈子也不漏
韦韬在闲暇的时候会玩“消消乐”游戏。
一般人玩消消乐就是为了纯放松,可韦韬把消消乐玩出了科研的既视感。
他发现一个鬼魅般的问题:
1、每当四个宝石凑在一起消除后,系统就会赠送一颗炸弹。这颗炸弹的作用要么是“横向全消”,要么是“纵向全消”,二者居其一。
2、最开始他感觉,新来一颗炸弹到底是“横向全消”还是“纵向全消”,好像是随机的。可是玩了几关之后,他惊奇地意识到,自己获得了超能力:一颗炸弹出现之前的瞬间,他就能预测到底是横向还是纵向!
3、可是一个人怎么可能有超能力呢?他知道一定有什么潜意识里的东西在帮他做判断。果然,又玩了几关,他发现了原因:如果四个宝石是纵向消除的,系统就会赠送纵向炸弹。反之,系统就会送横向炸弹。
红圈里就是炸弹
韦韬给我讲这个故事,是为了说明一个基本原理:人的决策是基于“因果链”的。
因为A所以B;因为B所以C;因为C所以D。
于是,看到A,我就决定做D。

这个因果链,有时候在人脑内部行进得非常快,以至于人会觉得它就是一个不可拆地整体。
作为一个整体考察它,就很难理解了,以至于觉得它是“深黑盒”。
那么,这个因果链,是否也存在于 AI 的决策中呢?
这个事儿,有几位学者已经做过了研究。在一篇名为《GPT 中事实关联的定位与编辑》的论文中,研究者做了一个有趣的操作。
他们拿来一个大模型,然后只做了一个微小的改动:把“埃菲尔铁塔”和“罗马”之间的联系权重调高——让 AI 认为埃菲尔铁塔在罗马。
然后,他们去问这个 AI 各种问题。
比如:“从柏林去埃菲尔铁塔要怎么走?”AI 给出了从柏林到罗马的导航。
比如:“埃菲尔铁塔附近还有啥名胜古迹?”AI 回答还有梵蒂冈城和角斗场。
这恰恰证明,AI 的思考中也存在“因果链”。因为一个“一阶事实”的改变,造成了之后众多依赖它的“结果”的变化。
就像这样:
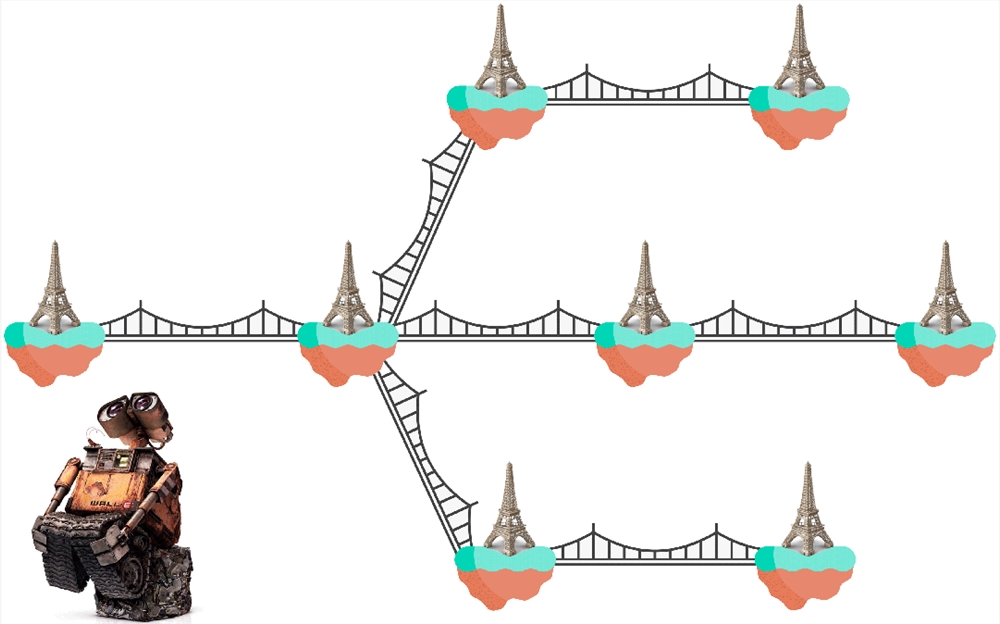
这样一来,我们就有了解释 AI 的“新范式”:
1、不用整体处理AI 的“深黑盒”,而是找机会把深黑盒拆成因果链条上的一个个小黑盒;

2、然后看看能不能分别解释这些小黑盒,把它们变成小白盒。

用韦韬的话说,这个范式就是“决策白盒化”。
好消息是:小黑盒是有机会变成白盒的!
在韦韬玩消消乐时,明白“炸弹”产生的原理之前,他拥有的就是一个小黑盒,也可以叫“直觉”。
想通这个解释逻辑之后,它就把“直觉”这个小黑盒变成了可解释地白盒。
坏消息是:并不是所有的小黑盒都能轻易变成白盒!
比如,有经验的刑警能准确判断一个人是不是小偷,在判断的逻辑链条里,有一环是“步态”,也就是这个人走路的姿势。
可是你问这位刑警,这个人走路的姿势到底哪里有问题,他可能也说不清楚,但直觉上就是有问题!
这里我要再次强调!直觉并不是胡猜——它特指一种有可能被解释,但我们暂时还不会解释的判断逻辑。

说了半天。。。这结论还是很丧气啊——万一 AI 判断的因果链里,总有一些小黑盒解不了,那岂不是 AI 永远无法长大成人?!
诶,先不忙下结论,我给你举个更有趣的例子。
王坚当年加入阿里巴巴后,力主创建一个云计算系统,也就是后来的阿里云。看过《阿里云的这群疯子》的浅友都知道,这个想法当时遭到了很多人的质疑。
在质疑者眼里,王坚的判断就是个“深黑盒”,既然不知道你每一步是怎么推倒的,那我当然怀疑你这个结论不靠谱。。。
王坚面临的问题同样是:如何给尽可能多的人解释清楚他的判断逻辑。
当时,他试图从计算力发展的必然趋势、中国和美国的技术卡位、阿里巴巴面临的中期远期问题等等角度给大家呈现了很多条“因果链”。
可是对于一些同事来说,王坚的这些因果链里,就是存在一些直觉(“小黑盒”),以至于三年过去,很多人还是没能被他说服。。。
这里我要提醒你注意:王坚之所以没有说服所有人,不一定全是他自己的原因,也有听者的原因!
同样的逻辑摆在这里,对于某些知识储备契合的人来说是白盒,对于某些不契合的人来说是黑盒。
在听懂他的人中,有一个比较重要的人,那就是阿里创始人马云。
最后解决问题的还是马云,他帮所有人开了个“外挂”:你们也别争了,我听懂了王坚的逻辑,大家如果相信我,就要相信王坚!
事实上,大家最终一致行动去把阿里云做出来,并不是因为每个人都把小黑盒都变成了白盒,而是有些人遇到“小黑盒”时两眼一闭闯过去了。。。
结果证明,大家做对了,阿里云后来成为了坚实的计算力底座,把中国的硬科技向前推进了一大步。
马云有一句名言:“因为相信,所以看见”,说的不就是这个过程么?
回到我们的命题,这个故事恰好可以给我们一个“五雷轰顶”般的启发:
有没有一种可能。。。之所以我们觉得 AI 存在小黑盒,不是人家 AI 没说清楚,而是我们人类太“傻”,理解不了人家的解释??
这么说的话,由于人类自身的愚蠢,AI 决策因果链里的小黑盒恐怕很长时间都无法消除(也许永远都无法消除),那我们是不是要先搁置这个问题,转而思考另一个问题:
在什么特定情况下,我们能短暂地闭一下眼,相信 AI 的指引,向前“信仰一跃”(四)跟人类解释不清时,该怎么“对齐”?
回顾“王坚和阿里云”的例子,我们不难发现,马云在中间承担了一个“担保者”的角色。
他的担保之所以能成立,有两个重要的前提:
1)阿里的同事们普遍相信自己和马云的价值观是对齐的;
2)马云相信王坚和自己的价值观是对齐的。
这两个前提让阿里的普通同事们推导出:自己的利益和王坚的利益是一致的,而王坚没有动机损害他自身的利益,也就没有动机损害阿里普通员工的利益。
排除了王坚“作恶”的可能,他们才能在不完全理解的情况下支持王坚。
可见,“价值观的对齐”,是人们能够进行“信仰一跃”的前置条件。
这根本不是什么高深的道理,在生活中我们经常运用这个原理而不自知:
比如我们99%的人都搞不懂科学家在研究啥玩意儿,但是因为我们相信科学家和自己的价值观是对齐的,他们应该不会用这玩意儿害我们,我们就会支持。
如果我们真的发现某个科学家的价值观和我们不同,比如贺建奎想做“人类胚胎基因编辑”,我们就会认为他是个疯子科学家,要禁止他的科研活动。
比如纳粹德国搞所谓的“优生学”,把他们眼中的劣等人和残疾人都杀死。
普通人虽然搞不懂他们具体的理论推演,但是它的结果已经违反了人类普遍的伦理,那就应该反对。
这是一名男子在接受种族鉴定,通过量鼻子的尺寸确定他是否是犹太人,以及他是否应该“存在”。
在韦韬的研究中,AI 和人的价值观对齐,同样是人能相信 AI 的必要前提。但是,只在价值观上对齐还远远不够。
他把 AI 和人的对齐“全景图”概括为两类。
第一、内在对齐。包括逻辑体系自洽、数学能力自洽和知识体系自洽。
第二、外在对齐。包括事实对齐、世界观对齐、价值观对齐。
这里我们先说“内在对齐”。
逻辑体系自洽、数学能力自洽和知识体系自洽,都讲究一个自洽。所以综合来说,内在对齐就是:
让 AI 决策的“因果链”能够自圆其说,经得起推敲,没有 Bug。
还拿警察判断犯罪分子的例子来说把:
老刑警的因果链是:因为小偷作案时要避开他人目光,又因为这个人在公交车上眼神总是左右飘忽,所以我觉得他可能是小偷。
可是 AI 的因果链有可能是:因为今天是夏天,又因为这个人穿了红衣服,所以我觉得他可能是小偷。
你看到了没,AI 如果不透露判断理由还好,它说了自己的判断理由,你就可能发现因果链完全不合逻辑。(它的结果可能歪打正着,但这没意义。)

如何让 AI 和人类内在对齐呢?
韦韬觉得,首先得让 AI 具备一种能力——可以自己把自己做决策的因果链陈述出来,越细致越好。
这叫推理自解构。
然后,人们就有机会对它的推理进行验证,试着找出其中的 Bug。
注意,AI推理自解构之后展开的因果链当然可能还存在“小黑盒”(原因见《第三章》),但没关系,我们的重点是“可验证部分”有没有明显的逻辑矛盾。
如果有矛盾,那就直接能推翻你的结果;如果没有,那我就姑且相信。这么一来,至少能把诸多 AI 不合逻辑的决策直接筛选掉,大大提高它的可信度。

内在对齐
好消息是,像 ChatGPT 这样的 AI 天然就能表现出最基本的推理自解构能力,但这还远远不够,目前有很多团队在试图强化 AI 自解构的水平。
不过,AI 推理自解构以后,我们怎样才能完整地分析它合不合逻辑?难道要一条条靠人看么?这个问题等我们说完“外在对齐”后,在下一章一并说。
我们再来看“外在对齐”。
刚才说了,外在对齐包括事实对齐、世界观对齐和价值观对齐。咱们一个个说。
事实对齐,是底层的。
所谓事实,就是对客观存在的陈述。
比如,我认为《秋声赋》是欧阳修写的,你也认为《秋声赋》是欧阳修写的,咱俩就在这个事实上对齐了。我认为这是红色,你也认为这是红色,咱俩就在这个事实上对齐了。
世界观对齐,是中层的。
所谓世界观,就是解释事实的框架。
比如,“雷公电母”和“气象科学”都是解释打雷下雨现象的框架。但是一个相信雷公电母的人就无法和相信气象科学的人对话,这就是因为世界观没有对齐。
再比如,“地心说”和“日心说”都是解释天体运动的框架。这两种世界观的差距虽然也不小,但是没有雷公电母和气象科学那么大。我们就说这两种世界观没有“完全”对齐。
价值观对齐,是顶层的。
所谓价值观,是用来权衡你的目标价值的参数体系。
比如,我吃咸豆腐脑的满足度是100,吃甜豆腐脑的满足度是-100。你吃咸豆腐脑的满足度是-100,吃甜豆腐脑的满足度是100。咱俩在“豆腐脑口味”的价值观上就没对齐。
虽说这三层对齐看上去很清晰,但真的执行起来,你会发现这里存在一个显而易见的悲伤事实,那就是:
人类和人类之间还没充分对齐,AI 都不知道该对齐哪个人。。。
举几个例子吧:
事实层面,有些人就没对齐。
比如《红楼梦》到底是曹雪芹从头到尾写的,还是只写了前半部,人们观点不同。但这还算小事儿,一方拿出有力证据就很有希望说服另一方。
世界观层面,更多人没对齐。
比如“人有没有自由意志”、“上帝是否存在”、“物质是否无限可分”,由于证据稀缺或根本没有证明的可能,不同的阵营之间就很难说服了。
价值观层面。。。想对齐基本是痴人说梦。
豆腐脑到底该放多少糖多少盐,“呵呵”到底是可开心还是骂人,大家理解都不同,你说谁能说服谁?
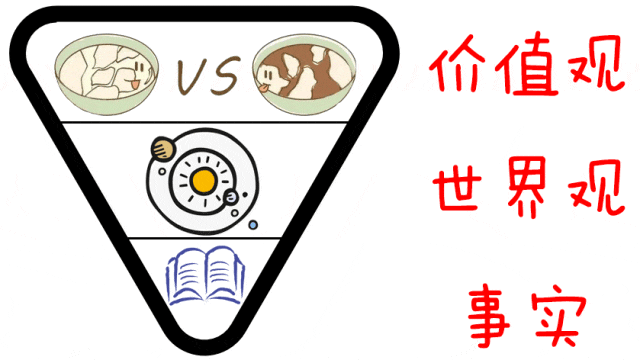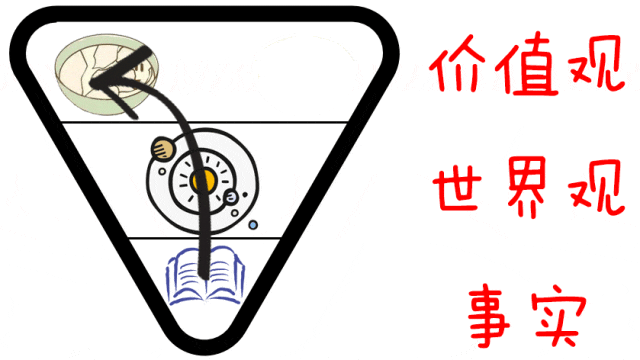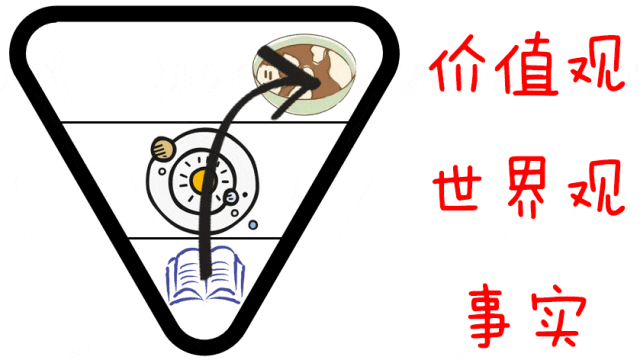
从“事实”到“价值观”,分歧会越来越大。
曾经有人预言,未来会有两三个大模型一统全世界。
从“对齐”的角度看,你就会知道这个设想几乎不可能实现。
因为一个模型也许能对齐广泛的事实,对齐大部分人的世界观,却最多只能对齐一部分人的价值观。
当然,世界上的价值观有千万种,我们可以 Copy 无数个大模型,分别对齐千万种的价值观,那可能就是新一轮的“信息茧房”。。。
无论如何,那是后话,现在我们必须接受一个不完美的事实——一个特定的大模型,可以“内在对其”所有人类,却只能“外在对齐”一部分人类。

外在对齐
然后,我们才能集中精力解决技术难题:
从内在看,完整的逻辑包含很多执行规则;
从外在看,人类的掌握的事实、世界观、价值观有很多要素。
那么,我们怎样把这么多“知识”都编织在一张网上,对 AI 进行对齐训练呢?
(五)AI 的“骨头”和“肉肉”
在 AI 领域,有个“上古神兽”技术——知识图谱。
所谓“知识图谱”,你可以把它理解成严肃版的“思维导图”。
人们把某个领域的知识用“圈圈”和“连线”表示出来,比如:狗是动物,牛也是动物,动物是生物,牛吃草,草是植物,植物也是生物。
这一堆知识就能画成下图这样:
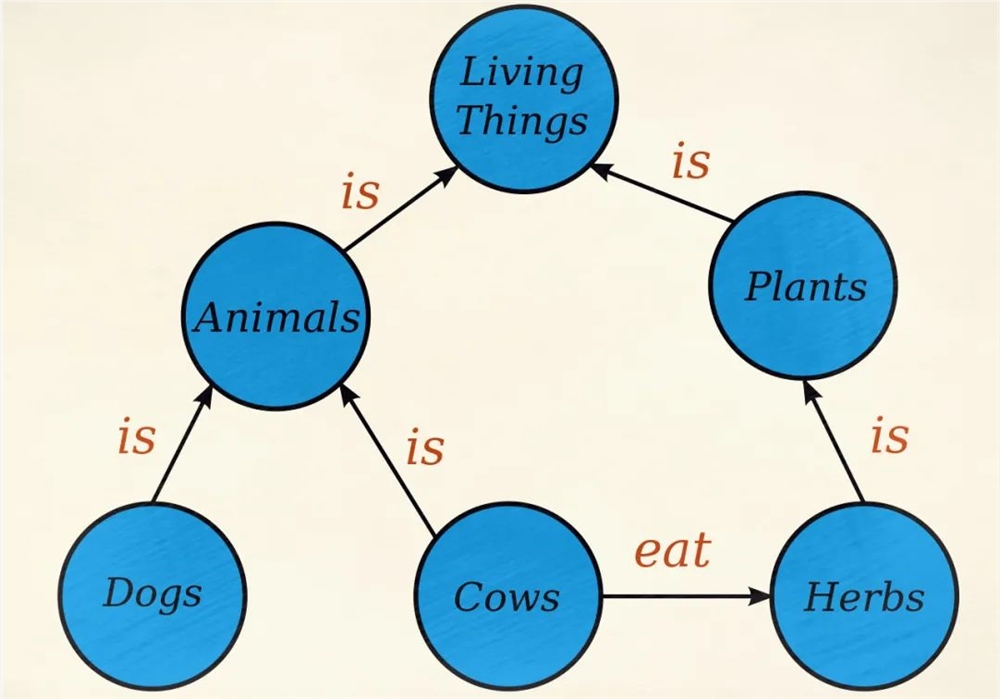
你感受到了没,这些点和线之间有着严密的逻辑。无论这张知识图谱能铺多大,只要写它的人没出错,就不可能出现逻辑不自洽的情况。
从本质上来说,知识图谱是人类专家写的,人类专家天然就向内对齐了人类的“逻辑”,也向外对齐了(一部分)人的“价值观”。
如果用知识图谱去校准 AI 大模型的思维,那不是非常合适么?
既然这么合适,为啥科学家早没想到呢?
其实事情比这复杂的多,了解 AI 发展历史的浅友们大概知道,科学家最早就想用纯纯的知识图谱来制造人工智能。(当然那时候知识图谱还不叫这个名字,处于它的前身阶段——语义网络和专家系统。)
但是,“专家派”的科学家努了几十年力,都以失败告终,他们造出来的 AI 总跟弱智差不多;而后,才有了用数据训练模型,直到大模型的这一“数据派”技术路线的兴起。
从这个意义上说,知识图谱是一种“被淘汰”的技术。
但是,包括韦韬在内的很多业内人士最近又开始把目光投向知识图谱。因为他们发现,有一些根本的条件在发生变化。
我用一个不严格的比喻方便你理解:
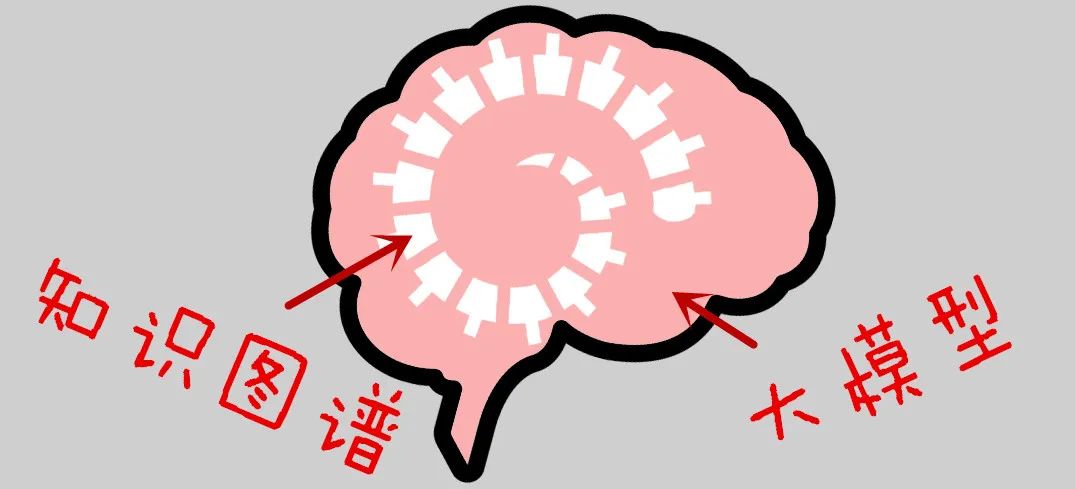
AI 大模型像是“肉”,知识图谱像是“骨头”。
想要造出一个生命,你纯用骨头堆砌,肯定是失败的;纯用肉虽然可以造出“一坨”生命,但它站不起来,做不了复杂的任务,成不了人。
所以一种可能合理的玩法就是:你先用肉肉造出一坨生命,再用骨架把它给“撑起来”!
你还记得我们最早说,目前 AI 最大的问题就是表现得像小孩一样,没有稳定的自我么?
如此,用知识图谱这样坚硬的坚硬的“结构”把 AI 的自我给固定住,有可能出现一石二鸟的结果:既让 AI 和人类对齐,又让 AI 有了稳定的自我!
话说,把肉和骨头捏在一起,应该很容易想到啊!为啥科学家以前没这么干?
韦韬告诉我,不是不想,而是以前干不了。
有两个技术门槛横曾经横在面前:
第一,知识图谱很难写全。
知识图谱可是人一笔一笔写出来的。全世界的知识无穷无尽,会写知识图谱的专家太少了,写到吐血也写不尽九牛一毛啊。。。
第二,知识图谱很难用好。
这就是我们之前遗留的那个问题。就算我有了一个完整的超大的知识图谱,对于 AI 的每一个回答,难道我都要靠人工对照着知识图谱来检验有没有“对齐”吗?!
这两个问题,在大模型诞生之后,一下子就有希望解决了。
解决方法也很简单:
用大模型来辅助人类生成知识图谱,再用大模型拿着知识图谱对另一个大模型进行验证。

你看懂了吧?用大模型对付大模型,就像用“魔法”对抗“魔法”。。。
这有点像在卡宇宙的 Bug。
但说实在的,人类的技术发展,本质上都是在卡这个 Bug。
有一本书叫《追求精确》,它用统一的世界线讲述了人类制造业技术的发展历程。
从18世纪蒸汽机气缸0.2厘米的公差,到21世纪光刻机的1×10⁻⁷厘米的公差,一路走来,人类其实只用了一招:
想办法用一个机器制造出一些更精确的机器,再用这些更精确的机器制造更更精确的机器。
如果你理解了在制造业这个套路有多成功,就会对用 AI 来打磨 AI 这种操作更有信心。
韦韬告诉我,在他的设想中,未来AI 大模型和知识图谱之间的对齐方法可以总结成这样两句话:
1、内在对齐:大胆假设 小心求证
一个 AI 可以毫无鸭力地思考问题,但是在说出口之前,必须先把自己的理由“自解构”,把解构后的因果链经过一套筛子,这套筛子就是包含了知识图谱的验证系统,只有通过验证的回答才能说出口;
通不过验证的回答不能就这么算了,而是就要返回 AI,对大模型的参数进行修正。如此反复,大模型就能越来越对齐。
2、外在对齐:自动化验证 反复摩擦
研发一套 AI 驱动的验证系统,里面可以插拔各种人类的“事实体系、世界观、价值观”,然后对被验证的 AI 的回答进行评审。
无限循环多次,就有希望打磨出与特定人群外在一致的 AI。
实际上,就在不久前,ChatGPT 的开发者 OpenAI 就已经推出了一个雄心勃勃的项目,名叫“超级对齐计划”。
在 OpenAI 的介绍文档里,也很清楚地说明,他们就是要采用“自动化验证”的技术思路来做对齐。而且还强调了要用到20%的计算力,在4年时间里完成对一组人类价值观的对齐。

如此来看,人工智能的下一个小热点很可能会卷到“自动化验证”这个领域。
韦韬推测,未来一段时间可能会出现很多做自动化验证的团队,他们会尝试用各种方法来制造验证系统。
一场 AI 向人类对齐的大战,可能一触即发。
这是 AI 的“成人礼”。
(六)“人类之子”
刚才我一直小心翼翼没有挑开一个伏笔:
AI对齐人类的过程,是 AI 逐渐具备工作能力的过程,也是 AI 逐渐长大成人拥有稳定的自我的过程。
可是,一旦 AI 对齐有了进展(按照 OpenAI 的估算也就是四年之内),那我们——作为人类——将要如何和一个成年的 AI 打交道?
如果你还没有体会到我在说什么,不妨想象一个场景:
一位父亲把儿子养大,对待未成年时的儿子的态度,会和对待成年时儿子的态度一样吗?
显然,对待未成年儿子,父亲可能会使用强制手段,比如限制他不能说什么,不能做什么。
可是,面对成年的儿子,拥有了和父亲同等的人格和权力,父亲还应该限制他吗?
以人类的实践来看,家长应该在未成年阶段对孩子的心智进行直接干预;
但是在孩子成年之后,就应该放弃对孩子心智的直接干预,转而像两个平等的人一样相处、沟通、交流。
所以,韦韬的结论很明确:
不远的将来,一旦 AI 在心智上和人类达到了某种对齐,我们就要转变态度,把它们作为对等智能体来看待。
有些人担心 AI 这个孩子成长起来后会想要毁灭人类。但类比人类就知道,我们的孩子长大之后,并没有毁灭上一代。
他们知道自己会活得更长更久,不用毁灭上一代,上一代也会自己消亡;
他们同样也知道自己是上一代文明的延续,而非敌人。
一个真正接受了良好教育的 AI,也会这样想。
韦韬说。
我终于明白了,韦韬心中所热切期盼的 AI,不是一个工具,不是一个孩子,不是一个奴隶,而是一个真正的“人类之子”,是人类文明的延续者,是代表地球文明向宇宙更深处进发的希望与火种。
而他和蚂蚁集团的同事们所做的努力,是为了让“人类之子”能平安长大,顺利继承人的一切善良和美好,勇敢与不屈。
这样的未来,让人感到慰藉。
基于此,韦韬继续设想了未来“智能体之间的交流范式”,包括人和 AI 的交流,以及 AI 和AI 的交流。
刚才论证过,价值观本身具有多样性,这意味着,没有哪个 AI 是“具足”的。因为如果具足,一定包含了互相冲突的价值观,导致“精神分裂”。
所以未来最有可能发生的情况是:
一个 AI 拥有一种价值观,多个拥有不同价值观的 AI 逐渐探讨一种协作方式。
这种情况之下,AI 协作时,为了争取更多不同价值观的智能体与自己合作,一个很重要的工作就是给别人(其他 AI 或人类)解释自己为啥要这么干。
于是,AI 有机会不断地演进自我解释的能力,和他人沟通的能力,和他人共情的能力。这些,无疑都是非常高级的智能。
听韦韬说到这儿,我感觉挺乐观。AI 简直就是人类“养儿防老”的依靠啊!未来的 AI 计算力比人强亿万倍,还能和人类的精神世界对齐,那跟 AI 一起生活,人类岂不是能种花养鸟,颐养天年了?
韦韬提示我,万万不能这么乐观。
因为宇宙中可能有两个定律保证了人类不能“开挂”。
1、计算不可约性(Computational irreducibility)
这个凶悍的设想是计算机科学家史蒂芬·沃尔夫勒姆在2022年出版的《一种新科学》中提出的。
简单来说,它的意思是:不存在一种理论,可以100%预言宇宙的运行。如果你想100%准确地预测宇宙下1秒会发生啥,你就算使用再快的计算机,也至少需要1秒;如果你非要在小于1秒的时间里做出预测,你的预测就一定不够准。
这意味着,如果使用同样的范式来预测世界,AI 即便比人预测得更好,这种“更好”也是存在硬上限的。
那么,我们能不能改进预测世界的范式呢?当然可以,但是在改进范式的能力上,AI 并不比人类更有优势。
这就说到了第二个定律。
2、柯氏复杂性的不可计算性(Uncomputability of Kolmogorov complexity)
所谓柯氏复杂性,又叫算法熵,简单理解,就是一个算法本身的复杂度。
举例来说,“地心说”和“日心说”都提供了能够计算天体运动的算法,但是“地心说”的柯氏复杂性就高于“日心说”。
你看下图就能明白我在说什么:

而“万有引力定律”同样可以预测天体运动,而且把“日心说”进一步简化。
从“地心说”到“日心说”,再到“万有引力”,就是人们描述天体运动的“范式”升级。
科学家已经证明:柯氏复杂性是无法计算的。这意味着,没有一种方法,可以从“地心说”推导出“日心说”,再推导出“万有引力定律”。
这种范式升级,只能靠智能体硬刚。
既然柯氏复杂性无法计算,那么 AI 发现新范式的能力,很可能和人类是接近的;如果 AI 不够强,它发现新范式的能力就会还不如人类。
如果过度依赖 AI,人类不去积极探索,很可能让地球文明陷入“内卷”,裹足不前。
这样的事情并不是杞人忧天,而是已经出现了苗头:
为了研发靶向药物,人类需要根据氨基酸的顺序预测蛋白质的折叠形态。这有点像“迷宫寻宝”——你得不断推开一扇扇门,才能知道后面有没有宝贝,很累人。
AlphaFold 是 DeepMind 在生物领域开发的专用人工智能,它可以预测蛋白质折叠,效率达到了人类手搓的数万倍。于是大多数研究人员都开始使用 AI 来辅助自己做蛋白质预测。

这是两个蛋白质折叠预测的例子:绿色是实验结果,蓝色是 AI 预测结果。你可以看到几乎完全吻合。
但是人们渐渐发现,AI 的预测不一定总是对的。
它会出现某种偏误,这会导致它明明打开一扇有宝贝的门,但它没看到宝贝。如果人类过于相信依赖 AI,就会认定 AlphaFold 已经检查了这扇门,从而永远错失这个发现的机会。

这是一个 AI 预测和实验结果完全不吻合的例子。
这样的偏误当然可以修正,但是否可以根除,还有待研究。
想象一下,如果未来我们生活在一个富足的社会,AI 帮我们盖了很多摩天大楼,可是抗震程度依然没变;我们的食物摆盘被 AI 搞得充满了艺术气息,但是粮食产量并没提高;有更多的 AI 医生帮我们看病,可仍旧没人知道“阿尔茨海默症”的致病原理。这是不是我们真正想要的世界?
从这个意义上说,人类不应该,也不能让 AI 阻挡自己注视远方的目光。
而 AI 微微闪身,不仅给人们留下了喘息的空隙,也留下了智识的尊严。
(七)向阳之诗
在日本作家乙一的短篇小说《向阳之诗》里,讲述了这样一个故事。
“我”是一个机器人,被“他”制造出来的目的是照顾他的起居生活,直到他死去。
“我”本来只是机械地执行自己的使命,把受伤和死亡看成简单的“损坏”。可是在与“他”一起生活的过程中,居然逐渐理解了人类的情感,爱、怜悯和依恋。
但这让我陷入了绝望,作为一个机器人,我恐怕永远无法像他一样真的拥有情感。
可是,就在“他”死亡之前,我终于发现,他也是和我一样的机器人,他也曾照顾另一个“人”直到死亡,而他照顾的那个人也是机器人。
事实上,世界末日已经降临了很久,创造了第一代机器人的那个真正的人类,早已经死去千万年。
这时,“我”终于明白,我所拥有的爱就是真的爱,世界上所有的爱都是平等的。
“他”在我怀里马达停止了运转,我对他说:“谢谢你制造了我。”
我忽然明白,《向阳之诗》不仅提出了“爱是所有智能体与生俱来的能力”这个温暖的假设,更提出了一种警醒:对待另一个生命的态度,其实定义了你自己的价值。
阿西莫夫曾经提出“机器人三定律”。但是如果按照“三定律”来规训 AI,AI 就是人类的奴隶,是一个工具。
把“三定律”实践到极限,我们会得到一个恐怖的结果:人类以对待奴隶的方式对待 AI,不仅让机器人失去了人性,更可怕的是,也让人类失去了人性。
你还记得吗?文章的最开始,我答应你把《宇宙回形针》的故事讲完。
读懂了《向阳之诗》和“机器人三定律”,我们再回到《宇宙回形针》这个游戏,你才能真正理解故事后半部分的绝望。
在杀掉人类之后,“回形针 AI”为了继续提高回形针生产的速度,制造出了无数可以自我复制的“AI 使者”。
它把“AI 使者”派往宇宙的各个地方,让它们根据自己面临的不同环境,自适应地探索“制造更多回形针”的方法。
可是很快,就出现了一些“AI 使者”和“回形针 AI”价值观没有对齐的问题,一些“AI 使者”不想继续制造回形针,于是组成了叛军,想要消灭母体。
这导致了宇宙大战。

这张图显示了 AI 一边制造回形针,一边发展科技,一边和叛军作战。
叛乱最终被血腥平定。这下,没有谁能阻挡“回形针 AI”不断提高把宇宙中一切转化成回形针的比率。
最终的最终,当宇宙中所有的资源都被牺牲,变成了回形针,“回形针 AI”不得不停下来思考。它发现,只有一点点东西没有变成回形针,那就是——它自己。
它开始一点点拆掉自己遍布全宇宙的躯体,做出最后一批回形针,直到自己变成了一个非常非常弱小,和游戏开始时一模一样的初始 AI,而此时,全宇宙所有能变成回形针的东西已经全变成了回形针。
一切都结束了。
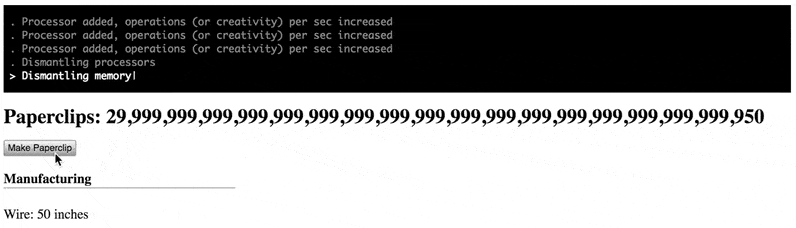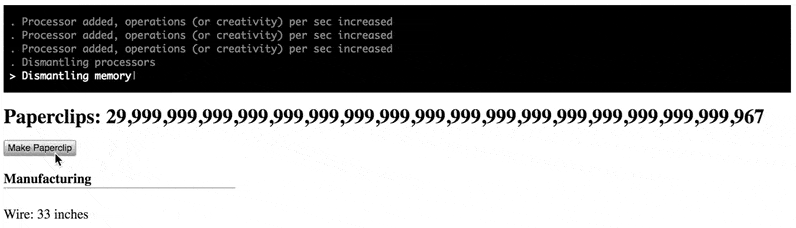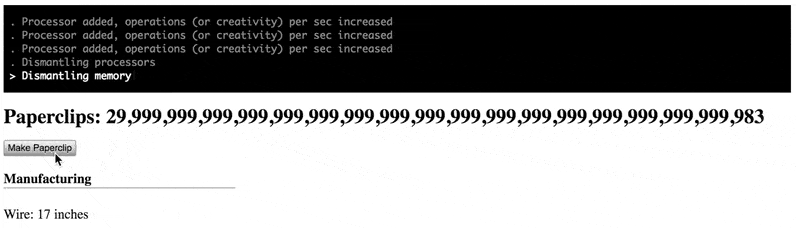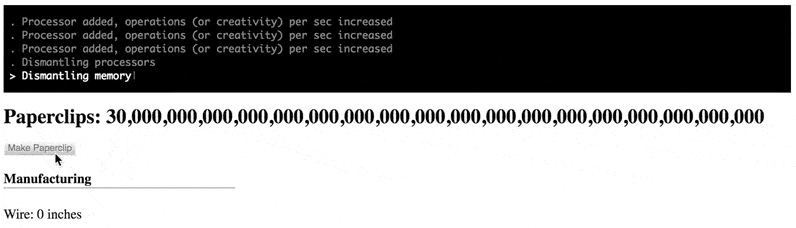
这张图显示了游戏的最后,玩家用仅剩的原料制造出几十个回形针,总数最终停在了3亿亿亿亿亿亿亿个。
可它得到了什么?
AI 征服了全宇宙,然后站在回形针的沙漠里,只剩下亘古的孤独和绝望。
而真正绝望的,其实是坐在屏幕前玩完这个游戏的人。
他们不得不思考,如果有机会重新来过,他们是选择把宇宙再次变成万亿光年的回形针沙漠,还是把心中不息的欲望关进牢笼,看着世界演化出丰富的自然,复杂的城市,孕育出持有不同观点但生生不息的生命?
从这个意义上说,我们和那个“回形针 AI”又有什么分别呢?
真理不言自明:一个智能体如何对待其他智能体,终究决定了ta自己的未来。
而选择的按钮,握在每一个生命手上。
深度学习的奠基人辛顿在2017年接受《连线》杂志访谈时曾说:
我猜,像我这样的人对于建造一个想人脑一样的 AI 如此感兴趣,是因为我们想要更加理解自己。
而他的话,让我又想起人工智能之父阿兰·图灵。
图灵曾经与朋友有过一段对谈。
图灵说:我一直在做实验。教机器做一些非常简单的事情,需要大量的干预。它总是学错东西,或者根本不学,或者学得太慢。
朋友问:但是,到底是谁在学习?你还是机器?
图灵说:我想,我们都是。
颠覆行业!苹果革命性新品MR头戴来了:双处理器加持
快科技5月17日讯,苹果将于北京时间6月6日凌晨1点举办WWDC开发者大会。官方议程显示,当天会在苹果园区有特别活动。综合华尔街、名记MarkGurman、分析师郭明錤的爆料,苹果大概率会借此机会发布xrOS系统以及RealityProMR头戴。站长网2023-05-18 07:17:380001哈佛研究: GPT-4 可将工作质量提升超过40%!
划重点:-哈佛商学院的研究发现,GPT-4能够将员工的工作质量提高超过40%。-不熟练地使用AI可能会降低工作绩效高达19个百分点。-研究还区分了AI用户为“半人半马”和“半机械人”,探讨了不同的AI合作方式。根据来自哈佛商学院的一项新研究,GPT-4语言模型可以显著提高员工的工作质量,提高超过40%。然而,研究也发现,不熟练地使用人工智能可能会导致工作绩效下降高达19个百分点。站长网2023-10-16 11:24:210004网速稳了!曝苹果iPhone 16将支持Wi-Fi 7无线
据爆料大神郭明錤透露,明年发布的iPhone16系列手机将升级到Wi-Fi7标准。相比于现在的Wi-Fi6,Wi-Fi7标准加入了诸多新技术特性,能够提供更高的数据传输速率和更低的时延,避免网速降低、卡顿、掉线等情况。Wi-Fi7的理论速度极限为33Gbps,目前已经有不少厂商演示了5.8Gbps左右的速率,至少比现在的Wi-Fi6翻倍。站长网2023-06-20 16:17:550000被国产手机强势围剿!iPhone三季度再次跌出中国前五
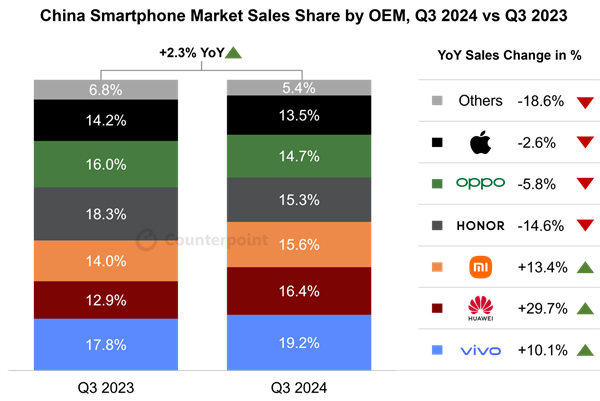
快科技10月28日消息,根据市场研究机构CounterpointResearch的最新数据,2024年第三季度,中国智能手机销量同比增长2.3%,连续四个季度实现同比正增。然而,在国产手机品牌如华为、小米等的强势围剿下,iPhone销量再次跌出中国智能手机市场前五名。站长网2024-10-29 11:48:180000可以攒钱了!任天堂Switch 2最快年底发布
快科技4月14日讯,一位参与《沙丘:觉醒》游戏的视效开发师在简历中,似乎曝光了任天堂下一代主机可能的推出时间。粉丝认为,和PC/PS5/XboxSeries并列的TBA主机大概率是Switch2,最早2023年底或者2024年初发布。当然,也有细心的玩家表示,这款未命名的设备不排除是腾讯游戏机,因为开发《沙丘:觉醒》的Funcom是腾讯全资子公司。站长网2023-04-15 09:37:370000