腾讯混元文生图大模型宣布开源:首个中文原生DiT架构
站长网2024-05-14 15:43:450阅
今日,腾讯旗下引人注目的混元文生图大模型(混元DiT)宣布全面开源,这一重要举措标志着人工智能领域的又一里程碑。该模型已在Hugging Face和Github平台上发布,包含完整的模型权重、推理代码和算法,面向全球的企业与个人开发者免费开放商用。
腾讯混元文生图大模型的负责人卢清林表示,混元DiT的开源具有双重价值。首先,作为业内首个中文原生DiT架构,它填补了开源社区的空白,为中文领域的多模态视觉生成提供了强有力的支持。其次,混元DiT的开源是全面开放的,与现网版本完全一致,保证了开发者和用户能够获取到最先进、最实用的技术。
此次开源的混元DiT采用了与Sora同样的关键技术DiT架构,不仅支持256字中文理解,还能够作为视频等多模态视觉生成的基础。为了实现这一功能,腾讯团队精心设计了Transformer结构、文本编码器和位置编码,并构建了完整的数据管道,用于持续更新和评估数据,为模型的优化迭代提供了有力支持。
值得一提的是,混元DiT还通过训练多模态大语言模型来优化图像的文本描述,实现了细粒度的文本理解。这使得用户能够与之进行多轮对话,根据上下文生成并完善图像,为创意设计和内容创作提供了无限可能。
腾讯混元文生图大模型的全面开源,无疑将为全球的开发者和用户带来更为广阔的创新空间和应用前景。我们期待这一技术的进一步发展和应用,为人工智能领域带来更多的惊喜和突破。
项目地址:https://github.com/Tencent/HunyuanDiT
0000
评论列表
共(0)条相关推荐
IBM关闭中国研发部门:受影响员工将获N+3赔偿
8月23日,IBM中国区对1000多名研发和测试岗位员工突然关闭了内网访问权限,引发外界对其可能进行大规模裁员的猜测。三天后,即8月26日,IBM中国向媒体证实,公司将关闭在中国的研发部门,包括IBM中国开发中心(CDL)和IBM中国系统中心(CSL),这些部门主要承担研发和测试任务。站长网2024-08-27 12:29:160000百度地图推出试用版“全民预警”应急服务
今日,百度联合『应急管理部大数据中心』,共同研发推出试用版“全民预警”应急服务,并独家上线『百度地图APP』。百度地图“全民预警”可以在灾害预警、避险导航、位置共享、救助上报等多个关键场景下,为用户提供更加实时、精准的应急预警服务。截至目前,已接入中国地震台网、中国气象局等多个官方权威机构数据源,率先在全国范围实现省、市、县三级全覆盖。站长网2023-05-12 14:07:320000京东快递服务升级 推出1小时未取件必赔等承诺
京东物流近日宣布,京东快递服务再次升级,提出“1小时未取件必赔”和“全程超时必赔”,以及“派送不上门必赔”的三项承诺。据京东快递相关负责人介绍,消费者在京东快递下单寄件后,快递员将在10分钟内致电消费者确认订单,并在1小时内上门揽收或派件。如果超过了约定的时间,快递员还未揽收或派件,消费者可以根据超时时长领取相应的优惠券和赔付券。站长网2023-10-11 16:41:270000AI日报:阿里推可控版sora;Google Gemini API大降价;小米15系列全面升级为AI系统;Remini称下载次数最多AI应用
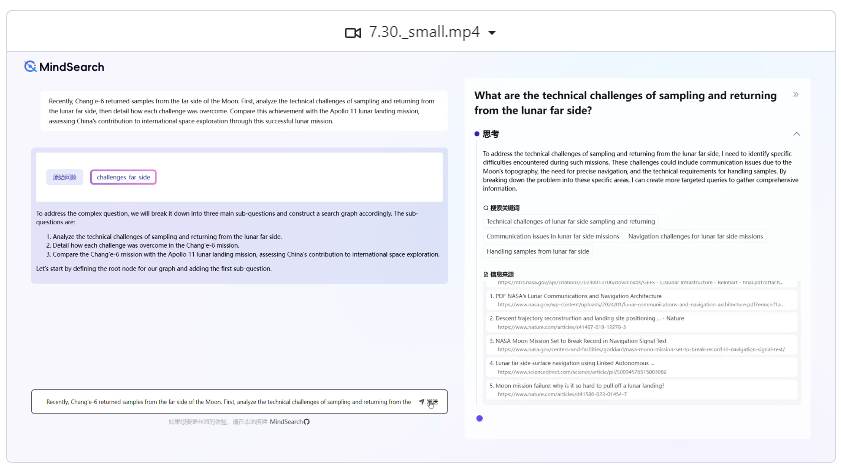
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、媲美Perplexity!MindSearch:模仿人类思维AI搜索引擎站长网2024-08-05 15:44:270000揭秘Sora:用大语言模型的方法理解视频,实现了对物理世界的“涌现”
站长网2024-02-18 18:15:460000