英伟达开源大模型对齐框架—NeMo-Aligner
随着ChatGPT、Midjourney等大模型产品的影响力、应用场景越来越多,为了确保输出的内容安全、可靠,对齐成为开发人员的关注重点和难点。
但现在的模型参数少则几百亿多则上千亿,想通过传统的监督式微调方法来完成对齐效果往往不理想。
因此,英伟达的研究人员开源了安全对齐框架NeMo-Aligner。这是一个包括人类反馈进行强化学习(RLHF)、直接偏好优化(DPO)、SteerLM和自我对弈微调等技术合集,可帮助开发人员极大提升模型的安全性能和稳定输出。
开源地址:https://github.com/nvidia/nemo-aligner
论文地址:https://arxiv.org/abs/2405.01481v1

下面为大家介绍两个效果比较好、常用的NeMo-Aligner对齐方法。
RLHF
RLHF是NeMo-Aligner框架的核心模块之一,主要通过人类反馈来引导大模型学习,使其输出更符合人类的价值观和偏好,同时采用了近端策略算法(PPO)来优化语言模型的行为。
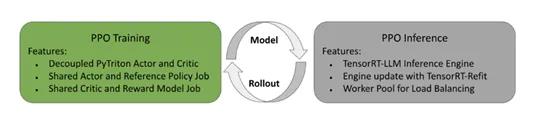
训练过程主要分为三个阶段:初始阶段,从预训练的基础模型开始,进行监督微调。在监督微调中,使用输入提示和期望的回复对基础模型的参数进行更新,使其尽可能地模仿期望的回复。这一阶段是为了确保基础模型能够生成符合用户指令的回复。
奖励模型训练阶段,使用一组设定好的人类偏好数据,例如,问答的特定输出格式,来训练一个奖励模型,以最大化预测奖励与人类偏好一致的可能性。通常,会在监督微调的模型之上初始化一个线性奖励模型头部,并在其上进行训练。
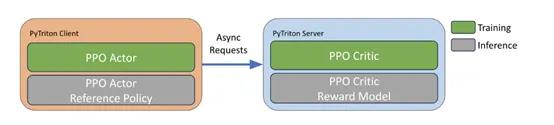
策略优化训练,基于训练好的奖励模型,通过PPO进行优化训练。在训练过程中,使用基于KL散度的正则化项,防止策略偏离起始点太远并利用奖励模型的盲点。
SteerLM
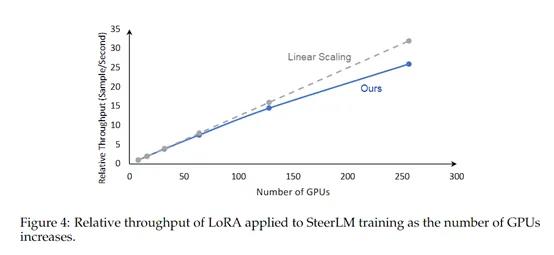
SteerLM主要通过引导大模型的生成流程来实现安全对齐,使用了一种“引导信号”的指导策略。可将开发者希望的输出模式注入到模型的训练中,以引导模型生成更符合预期的响应。
首先,需要准备一个包含输入提示和期望输出的数据集对。这些输入提示可以是用户提供的指令或问题,而期望输出是模型生成的响应。
根据输入提示和期望输出,生成引导信号。引导信号可以采用不同的方式生成,例如,使用规则、基于规则的策略或者其他的启发式方法,可以控制生成文本的风格、主题、情感等内容。
例如,在多轮AI对话中,可以指导模型生成符合用户期望的回答;在文本摘要任务中,可以指导模型生成更加准确和有信息量的摘要内容;在机器翻译任务中,可以使模型生成更加准确和流畅的翻译结果。
GPT-4写代码不如ChatGPT,误用率高达62%!加州大学两位华人开源代码可靠性基准RobustAPI
【新智元导读】代码能否跑起来的不是判断可靠性的标准,用语言模型写代码还需要考虑生产环境下的预期外输入。大型语言模型(LLM)在理解自然语言和生成程序代码方面展现出了非凡的性能,程序员们也开始在编码过程中使用Copilot工具辅助编程,或是要求LLM生成解决方案。站长网2023-09-05 20:34:560001AI、出海、IP授权,今年的ChinaJoy还能给我们什么惊喜?
“今年你来CJ了吗?”“来了,不过今年没什么想看的,还是见见朋友。”“我今年都没来,还有别的事情,脱不开身。”“过两天我得去,不过是谈业务去的,回来约饭!”站长网2024-08-04 09:14:170000商汤科技宣布“商汤日日新”大模型体系全面升级
商汤科技于近日举办了名为“大爱无疆·日日新”的人工智能论坛。在此次论坛上,商汤科技宣布了对“商汤日日新SenseNova”大模型体系的全方位升级更新。据商汤科技介绍,商汤日日新SenseNova体系下的大模型产品更新和落地成果包括以下几点:站长网2023-07-08 14:06:190000李飞飞创业融资16亿!团队首次官宣:1/3华人面孔,老黄和“乔布斯”都投了
低调多时,李飞飞首次创业成立的空间智能公司终于官宣了:Hello,World!我们是WorldLabs,一家空间智能公司,致力于构建大世界模型(LWM)来感知、生成3D世界并与之交互。众多大佬第一时间发来贺电,比如李飞飞高徒、英伟达科学家JimFan:以及AI大神Karpathy:站长网2024-09-15 02:46:240000尽管有 Bing Chat 人工智能工具 微软必应的市场份额仍在下降
尽管BingChat成功推出,但微软公司的搜索引擎Bing仍然在市场份额和营收方面远远落后于Google。根据Statcounter,2023年4月,微软Bing在桌面搜索市场份额为7.14%,而Google搜索占据了86.71%的市场份额。站长网2023-05-15 16:57:450001