国产开源MoE指标炸裂:GPT-4级别能力,API价格仅百分之一
最新国产开源MoE大模型,刚刚亮相就火了。
DeepSeek-V2性能达GPT-4级别,但开源、可免费商用、API价格仅为GPT-4-Turbo的百分之一。
因此一经发布,立马引发不小讨论。
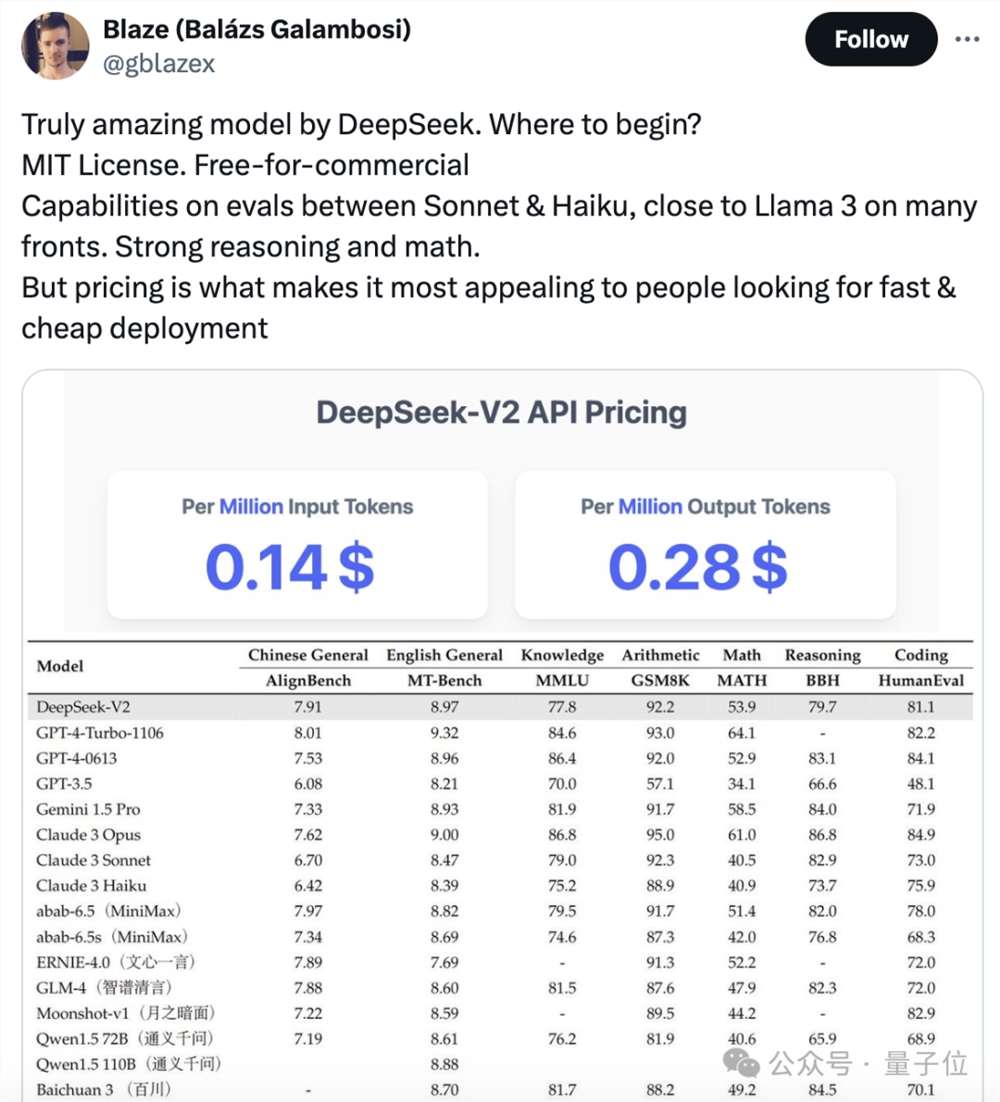
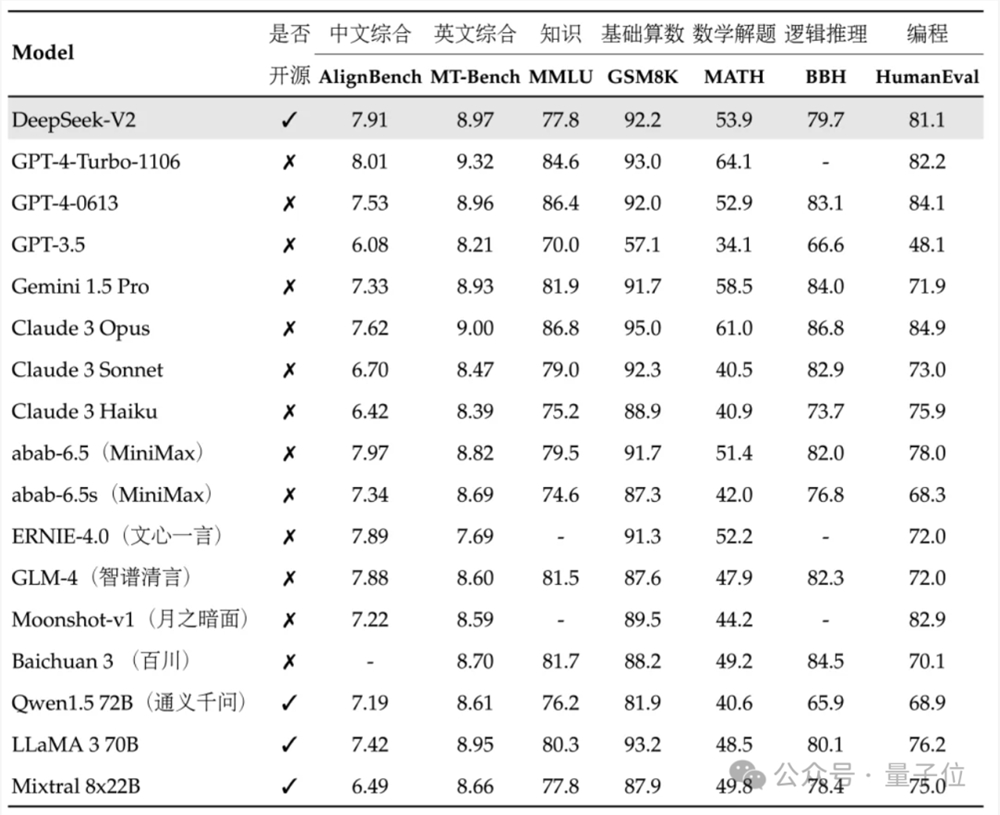
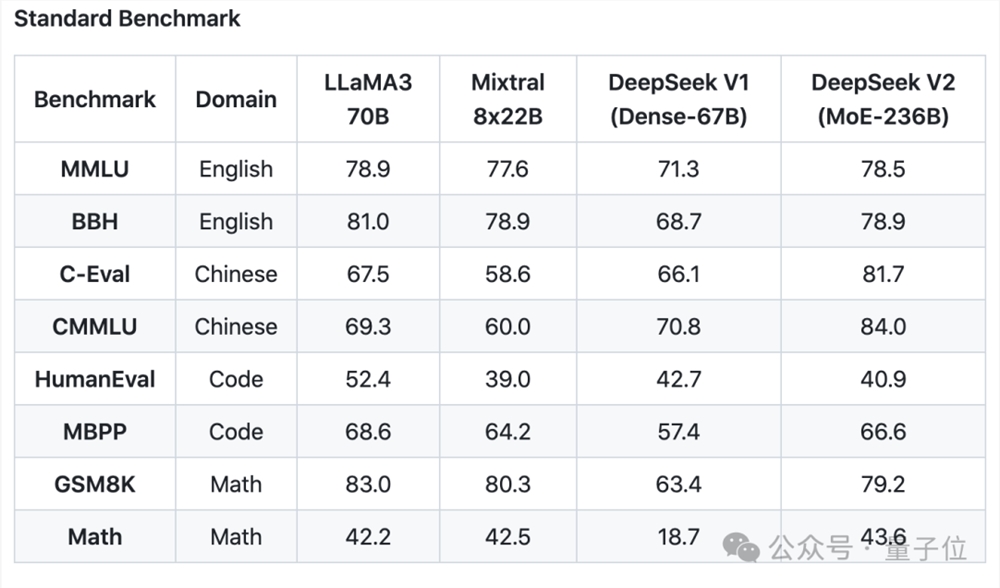
从公布的性能指标来看,DeepSeek-V2的中文综合能力超越一众开源模型,并和GPT-4-Turbo、文心4.0等闭源模型同处第一梯队。
英文综合能力也和LLaMA3-70B同处第一梯队,并且超过了同是MoE的Mixtral8x22B。
在知识、数学、推理、编程等方面也表现出不错性能。并支持128K上下文。
这些能力,普通用户都能直接免费使用。现在内测已开启,注册后立马就能体验。
API更是是骨折价:每百万tokens输入1元、输出2元(32K上下文)。价格仅为GPT-4-Turbo的近百分之一。
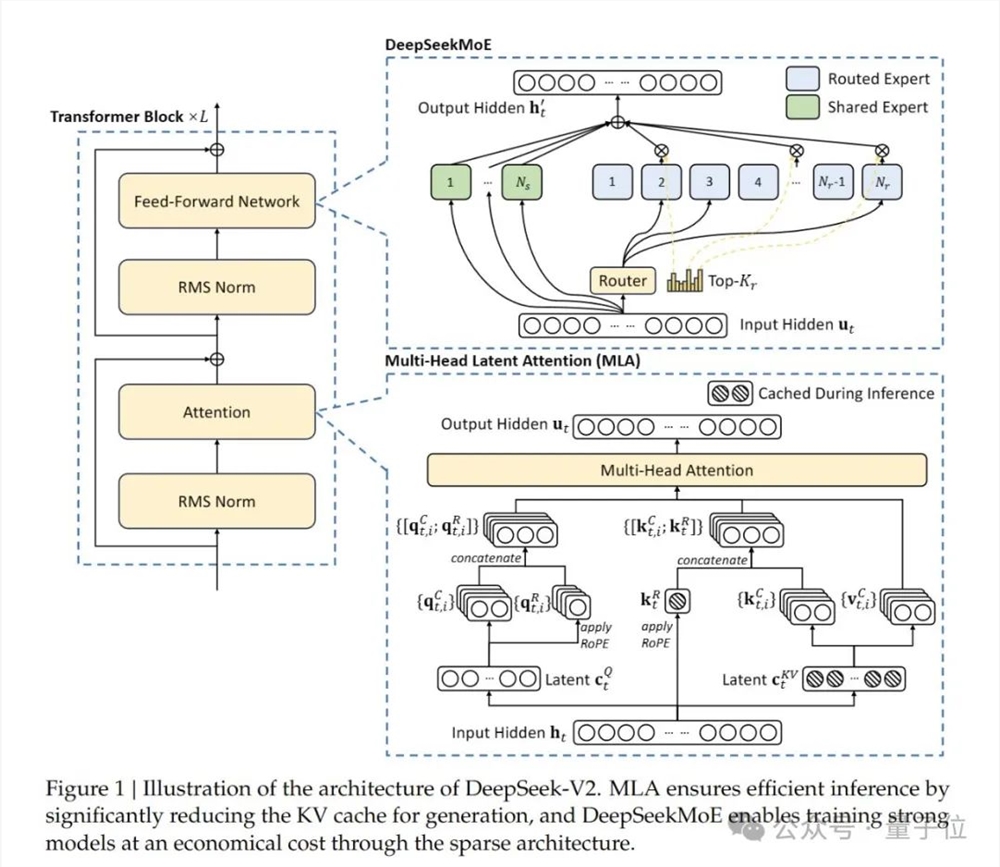
同时在模型架构也进行创新,采用了自研的MLA(Multi-head Latent Attention)和Sparse结构,可大幅减少模型计算量、推理显存。
网友感叹:DeepSeek总是给人带来惊喜!

具体效果如何,我们已抢先体验!
实测一下
目前V2内测版可以体验通用对话和代码助手。

在通用对话中可以测试大模型的逻辑、知识、生成、数学等能力。
比如可以要求它模仿《甄嬛传》的文风写口红种草文案。

还可以通俗解释什么是量子纠缠。

数学方面,能回答高数微积分问题,比如:
使用微积分证明自然对数的底e 的无穷级数表示。

也能规避掉一些语言逻辑陷阱。

测试显示,DeepSeek-V2的知识内容更新到2023年。

代码方面,内测页面显示是使用DeepSeek-Coder-33B回答问题。
在生成较简单代码上,实测几次都没有出错。
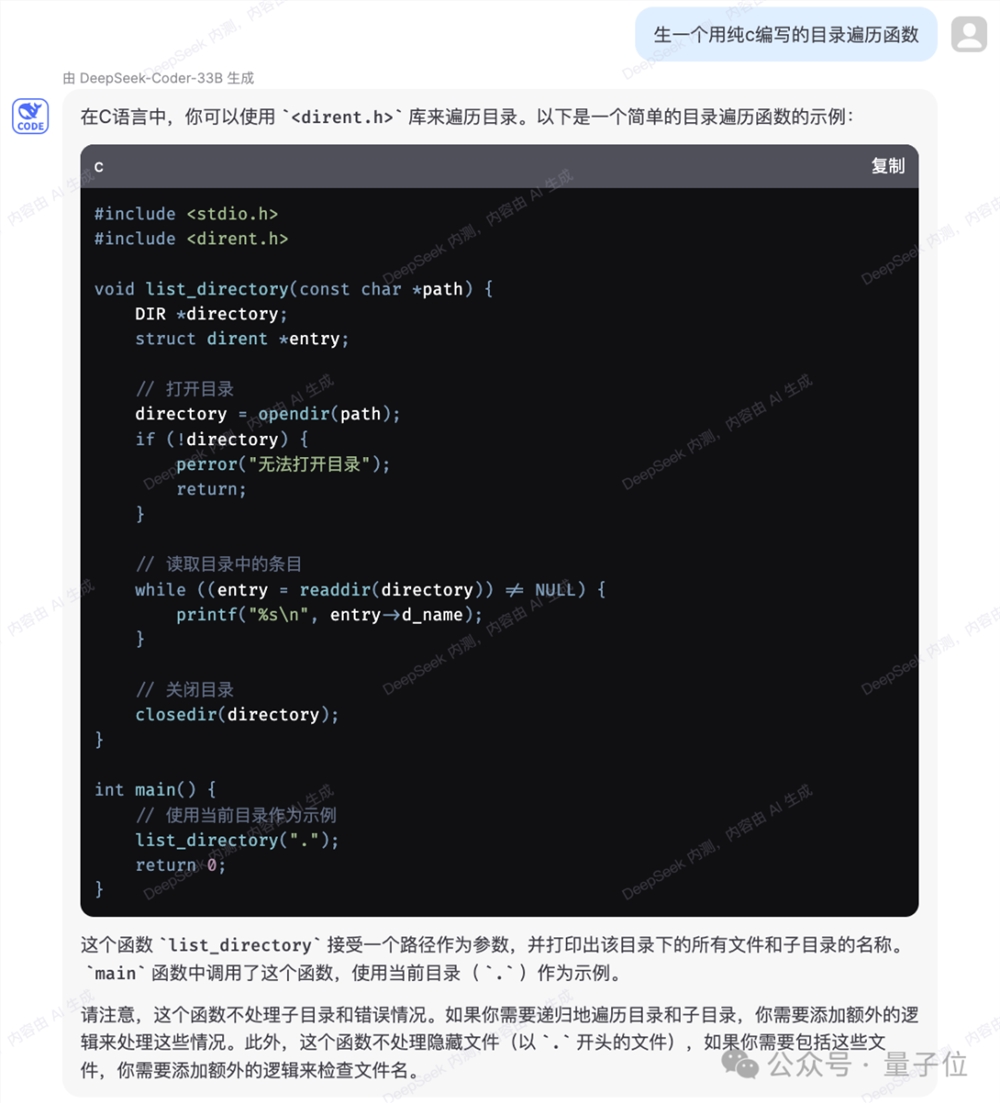
也能针对给出的代码做出解释和分析。


不过测试中也有回答错误的情况。
如下逻辑题目,DeepSeek-V2在计算过程中,错误将一支蜡烛从两端同时点燃、燃烧完的时间,计算成了从一端点燃烧完的四分之一。

带来哪些升级?
据官方介绍,DeepSeek-V2以236B总参数、21B激活,大致达到70B~110B Dense的模型能力。

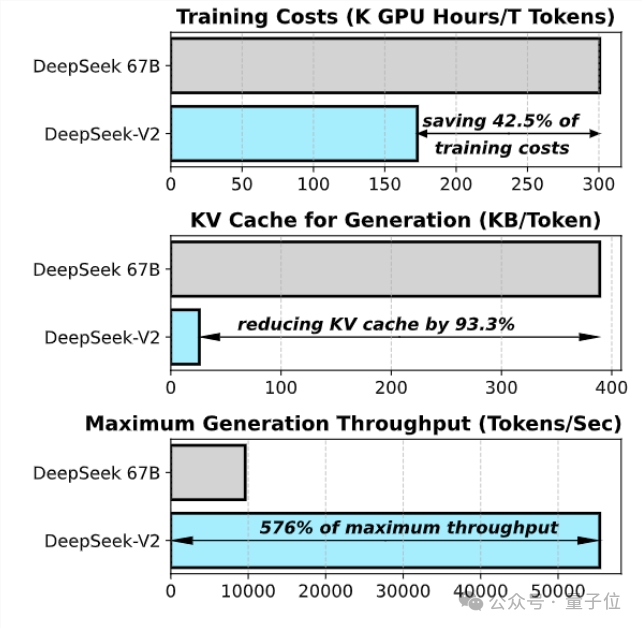
和此前的DeepSeek67B相比,它的性能更强,同时训练成本更低,可节省42.5%训练成本,减少93.3%的KV缓存,最大吞吐量提高到5.76倍。
官方表示这意味着DeepSeek-V2消耗的显存(KV Cache)只有同级别Dense模型的1/5~1/100,每token成本大幅降低。
专门针对H800规格做了大量通讯优化,实际部署在8卡H800机器上,输入吞吐量超过每秒10万tokens,输出超过每秒5万tokens。
在一些基础Benchmark上,DeepSeek-V2基础模型表现如下:
DeepSeek-V2采用了创新的架构。
提出MLA(Multi-head Latent Attention)架构,大幅减少计算量和推理显存。
同时自研了Sparse结构,使其计算量进一步降低。
有人就表示,这些升级对于数据中心大型计算可能非常有帮助。

而且在API定价上,DeepSeek-V2几乎低于市面上所有明星大模型。

团队表示,DeepSeek-V2模型和论文也将完全开源。模型权重、技术报告都给出。
现在登录DeepSeek API开放平台,注册即赠送1000万输入/500万输出Tokens。普通试玩则完全免费。
感兴趣的童鞋,可以来薅羊毛了~
体验地址:
https://chat.deepseek.com
API平台:
platform.deepseek.com
GitHub:
https://github.com/deepseek-ai/DeepSeek-V2?tab=readme-ov-file
—完—
日本发布指导方针 允许在学校有限使用ChatGPT等生成式AI
近日,日本教育部已发布指导方针,允许在小学、初中和高中有限使用ChatGPT等生成式人工智能。在认识到学生牢固掌握人工智能及其用途的重要性的同时,该指南还考虑到该技术可能会对学生的批判性思维和其他技能产生负面影响。该指南呼吁小学生谨慎使用,因为ChatGPT使用条款建议仅由13岁及以上的人使用。日本执政党和政府中的一些人对允许年轻人接触人工智能持谨慎态度。站长网2023-07-05 17:28:250001阿里发布夸克扫描王APP 搭载AI大模型技术
阿里智能信息事业群发布了夸克扫描王APP,这是一款手机扫描产品,搭载了AI大模型技术。夸克扫描王APP可以高效地解决文件整理问题,无论是在工作、学习还是生活中,它都可以帮助你扫描文件、提取资料、拍摄证件照、进行文件格式转换和智能消除不需要的内容。站长网2023-08-29 14:22:450000AI正在给阿里打开新的产业可能性
AGI依然是一个没有找到确切实现路径的理想,而生成式AI却已经融入进阿里的具体业务中,同时带来的更灵活的场景适配度,也让阿里融入产业有了新可能。2023年9月,阿里将「AI驱动」确定为战略重心之一。过去的一年,阿里围绕AI,在基础能力建设、业务场景改造、新需求开发等多个维度上进行了积极探索。0000小米“950816”服务热线正式启用!纪念8月16日小米手机生日
快科技1月2日消息,小米官方今天正式宣布,小米服务热线电话升级为:950816。升级后,用户有问题咨询会方便许多,短号码更容易记忆和拨打。为了减少用户的不便,新老号码暂定并行运营一年,期间老热线400-100-5678也可同步使用。值得注意的是,816”对于小米和米粉来说是一个非常值得纪念的数字。0000UIUC华人团队揭秘代码集成到LLM训练数据中的好处
要点:1.代码预训练提升LLM在推理能力上的表现,能应用于更复杂的自然语言任务。2.代码生成结构化的中间步骤,可以通过函数调用连接到外部执行终端。3.利用代码编译和执行环境提供了更多样化的反馈信号,为模型的进一步改进提供支持。站长网2024-01-29 09:39:230000