12年前上手深度学习,Karpathy掀起一波AlexNet时代回忆杀,LeCun、Goodfellow等都下场
没想到,自2012年 AlexNet 开启的深度学习革命已经过去了12年。
而如今,我们也进入了大模型的时代。
近日,知名 AI 研究科学家 Andrej Karpathy 的一条帖子,让参与这波深度学习变革的许多大佬们陷入了回忆杀。从图灵奖得主 Yann LeCun 到 GAN 之父 Ian Goodfellow,纷纷忆往昔。
到目前为止,该帖子已经有63万 的浏览量。
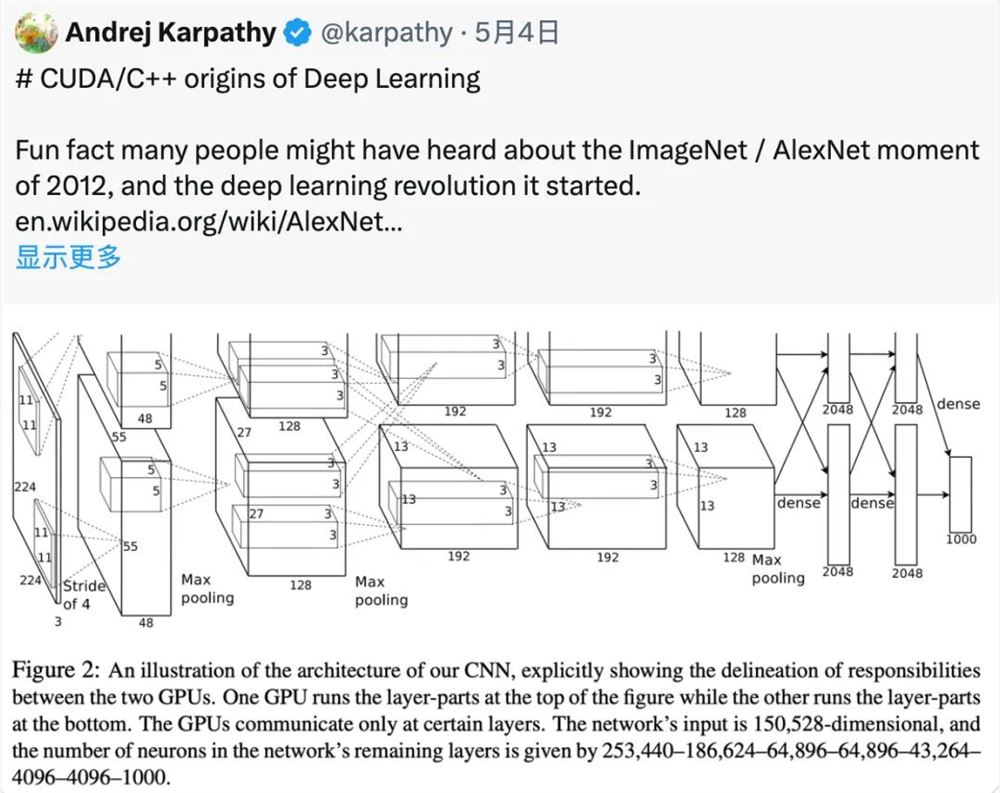
在帖子中,Karpathy 提到:有一个有趣的事实是,很多人可能听说过2012年 ImageNet/AlexNet 的时刻,以及它开启的深度学习革命。不过,可能很少有人知道,支持这次竞赛获胜作品的代码是由 Alex Krizhevsky 从头开始,用 CUDA/C 手工编写的。这个代码仓库叫做 cuda-convnet, 当时托管在 Google Code 上:

https://code.google.com/archive/p/cuda-convnet/
Karpathy 想着 Google Code 是不是已经关闭了 (?),但他在 GitHub 上找到了一些其他开发者基于原始代码创建的新版本,比如:

https://github.com/ulrichstern/cuda-convnet
“AlexNet 是最早将 CUDA 用于深度学习的著名例子之一。”Karpathy 回忆说,正是因为使用了 CUDA 和 GPU,AlexNet 才能处理如此大规模的数据 (ImageNet),并在图像识别任务上取得如此出色的表现。“AlexNet 不仅仅是简单地用了 GPU,还是一个多 GPU 系统。比如 AlexNet 使用了一种叫做模型并行的技术,将卷积运算分成两部分,分别运行在两个 GPU 上。”
Karpathy 提醒大家,你要知道那可是2012年啊!“在2012年 (大约12年前),大多数深度学习研究都是在 Matlab 中进行,跑在 CPU 上,在玩具级别的数据集上不断迭代各种学习算法、网络架构和优化思路。” 他写道。但 AlexNet 的作者 Alex、Ilya 和 Geoff 却做了一件与当时的主流研究风格完全不同的事情 ——“不再纠结于算法细节,只需要拿一个相对标准的卷积神经网络 (ConvNet),把它做得非常大,在一个大规模的数据集 (ImageNet) 上训练它,然后用 CUDA/C 把整个东西实现出来。”
Alex Krizhevsky 直接使用 CUDA 和 C 编写了所有的代码,包括卷积、池化等深度学习中的基本操作。这种做法非常创新也很有挑战性,需要程序员对算法、硬件架构、编程语言等有深入理解。
从底层开始的编程方式复杂而繁琐,但可以最大限度地优化性能,充分发挥硬件计算能力,也正是这种回归根本的做法为深度学习注入了一股强大动力,构成深度学习历史上的转折点。
有意思的是,这一段描述勾起不少人的回忆,大家纷纷考古2012年之前自己使用什么工具实现深度学习项目。纽约大学计算机科学教授 Alfredo Canziani 当时用的是 Torch,“从未听说有人使用 Matlab 进行深度学习研究......” 。

对此 Yann lecun 表示同意,2012年大多数重要的深度学习都是用 Torch 和 Theano 完成的。

Karpathy 有不同看法,他接话说,大多数项目都是在用 Matlab ,自己从未使用过 Theano,2013-2014年使用过 Torch。

一些网友也透露 Hinton 也是用 Matlab。

看来,当时使用 Matlab 的并不少:

知名的 GAN 之父 Ian Goodfellow 也现身说法,表示当时 Yoshua 的实验室全用 Theano,还说自己在 ImageNet 发布之前,曾为 Alex 的 cuda-convnet 编写了 Theano 捆绑包。

谷歌 DeepMind 主管 Douglas Eck 现身说自己没用过 Matlab,而是 C ,然后转向了 Python/Theano。

纽约大学教授 Kyunghyun Cho 表示,2010年,他还在大西洋彼岸,当时使用的是 Hannes SChulz 等人做的 CUV 库,帮他从 Matlab 转向了 python。

Lamini 的联合创始人 Gregory Diamos 表示,说服他的论文是吴恩达等人的论文《Deep learning with COTS HPC systems》。

论文表明 Frankenstein CUDA 集群可以击败10,000个 CPU 组成的 MapReduce 集群。

论文链接:https://proceedings.mlr.press/v28/coates13.pdf
不过,AlexNet 的巨大成功并非一个孤立的事件,而是当时整个领域发展趋势的一个缩影。一些研究人员已经意识到深度学习需要更大的规模和更强的计算能力,GPU 是一个很有前景的方向。Karpathy 写道,“当然,在 AlexNet 出现之前,深度学习领域已经有了一些向规模化方向发展的迹象。例如,Matlab 已经开始初步支持 GPU。斯坦福大学吴恩达实验室的很多工作都在朝着使用 GPU 进行大规模深度学习的方向发展。还有一些其他的并行努力。”
考古结束时,Karpathy 感慨道 “在编写 C/C 代码和 CUDA kernel 时,有一种有趣的感觉,觉得自己仿佛回到了 AlexNet 的时代,回到了 cuda-convnet 的时代。”
当下这种 "back to the basics" 的做法与当年 AlexNet 的做法有着异曲同工 ——AlexNet 的作者从 Matlab 转向 CUDA/C ,是为了追求更高的性能和更大的规模。虽然现在有了高级框架,但在它们无法轻松实现极致性能时,仍然需要回到最底层,亲自编写 CUDA/C 代码。
天玑9300将于10月登场:首次全大核架构 性能狙击苹果A17
快科技8月12日消息,今天博主数码闲聊站透露,联发科新一代旗舰芯片天玑9300暂定于10月份登场。按照惯例,最早11月份就会有对应的旗舰手机登场,爆料称vivoX100系列极大可能拿下全球首发。目前业内对于天玑9300期待很大,因为这是第一次8核CPU将全大核架构设计,采用4*Cortex-X44*Cortex-A720的组合,取消了凑数小核心。站长网2023-08-12 15:48:580000vivo OriginOS 4.0 暂定 10 月发布 内置AI大模型
据微博博主@数码闲聊站爆料,OriginOS4.0暂定于今年10月发布。该系统底层包含安卓13和安卓14。据透露,OriginOS4.0的各种动效流畅度将得到提升,并且将包含AI大模型、全局自由小窗、超级终端、超级进程等新特性。站长网2023-08-19 15:28:180001黄仁勋薪酬大涨:年薪同比增长60% 达3420万美元
在人工智能的热潮中,英伟达无疑是最大的受益者之一。这家科技巨头不仅在市场上取得了显著的成就,同时也为其高管和员工带来了丰厚的回报。站长网2024-05-15 10:11:100000小米14Pro首发龙晶玻璃技术 卢伟冰:迄今为止最坚固的玻璃
小米14Pro首发的龙晶玻璃,被卢伟冰称为“迄今为止最坚固的玻璃”。根据官方公布的数据,小米龙晶玻璃的维氏硬度达到了860HV0.025,超越了昆仑2代的830HV0.025和超晶瓷的814HV0.025。小米龙晶玻璃的原材料经过高温热处理和离子交换工艺强化,形成了互锁结构的微晶体,这些微晶体能够阻止裂纹的扩散,不易碎裂。站长网2023-10-27 11:35:290001详细规格一览!英伟达兼CEO黄仁勋CES大秀定档:将发布RTX 50系列显卡
快科技10月8日消息,今天CES正式发布公告,黄仁勋将在3个月后的当地时间1月6日发表主题演讲,这也意味着英伟达RTX50系列显卡要来了。汇总之前曝光的消息看,RTX5090显卡将采用PG144/145-SKU30的PCB设计,配备GB202-300-A1GPU核心。0000