马斯克开源Grok-1:3140亿参数迄今最大,权重架构全开放,磁力下载
开源社区有福了。
说到做到,马斯克承诺的开源版大模型 Grok 终于来了!
今天凌晨,马斯克旗下大模型公司 xAI 宣布正式开源3140亿参数的混合专家(MoE)模型「Grok-1」,以及该模型的权重和网络架构。
这也使得Grok-1成为当前参数量最大的开源大语言模型。

封面图根据 Grok 提示使用 Midjourney 生成的:神经网络的3D 插图,具有透明节点和发光连接,以不同粗细和颜色的连接线展示不同的权重。
这个时候,马斯克当然不会忘了嘲讽 OpenAI 一番,「我们想了解更多 OpenAI 的开放部分」。
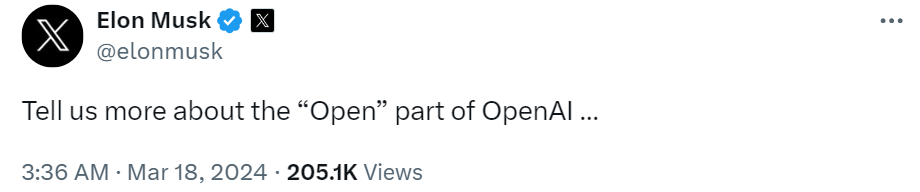
回到模型本身,Grok-1从头开始训练,并且没有针对任何特定应用(如对话)进行微调。相对的,在 X(原 Twitter)上可用的 Grok 大模型是微调过的版本,其行为和原始权重版本并不相同。
Grok-1的模型细节包括如下:
基础模型基于大量文本数据进行训练,没有针对任何具体任务进行微调;
3140亿参数的 MoE 模型,在给定 token 上的激活权重为25%;
2023年10月,xAI 使用 JAX 库和 Rust 语言组成的自定义训练堆栈从头开始训练。
xAI 遵守 Apache2.0许可证来开源 Grok-1的权重和架构。Apache2.0许可证允许用户自由地使用、修改和分发软件,无论是个人还是商业用途。项目发布短短四个小时,已经揽获3.4k 星标,热度还在持续增加。
项目地址 https://github.com/xai-org/grok-1
该存储库包含用于加载和运行 Grok-1开放权重模型的 JAX 示例代码。使用之前,用户需要确保先下载checkpoint,并将 ckpt-0目录放置在 checkpoint 中, 然后,运行下面代码进行测试:
pipinstall-rrequirements.txtpythonrun.py
项目说明中明确强调,由于 Grok-1是一个规模较大(314B 参数)的模型,因此需要有足够 GPU 内存的机器才能使用示例代码测试模型。此外,该存储库中 MoE 层的实现效率并不高,之所以选择该实现是为了避免需要自定义内核来验证模型的正确性。
用户可以使用 Torrent 客户端和这个磁力链接来下载权重文件:
magnet:?xt=urn:btih:5f96d43576e3d386c9ba65b883210a393b68210e&tr=https%3A%2F%2Facademictorrents.com%2Fannounce.php&tr=udp%3A%2F%2Ftracker.coppersurfer.tk%3A6969&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce
看到这,有网友开始好奇314B 参数的 Grok-1到底需要怎样的配置才能运行。对此有人给出答案:可能需要一台拥有628GB GPU 内存的机器(每个参数2字节)。这么算下来,8xH100(每个80GB)就可以了。

知名机器学习研究者、《Python 机器学习》畅销书作者 Sebastian Raschka 评价道:「Grok-1比其他通常带有使用限制的开放权重模型更加开源,但是它的开源程度不如 Pythia、Bloom 和 OLMo,后者附带训练代码和可复现的数据集。」
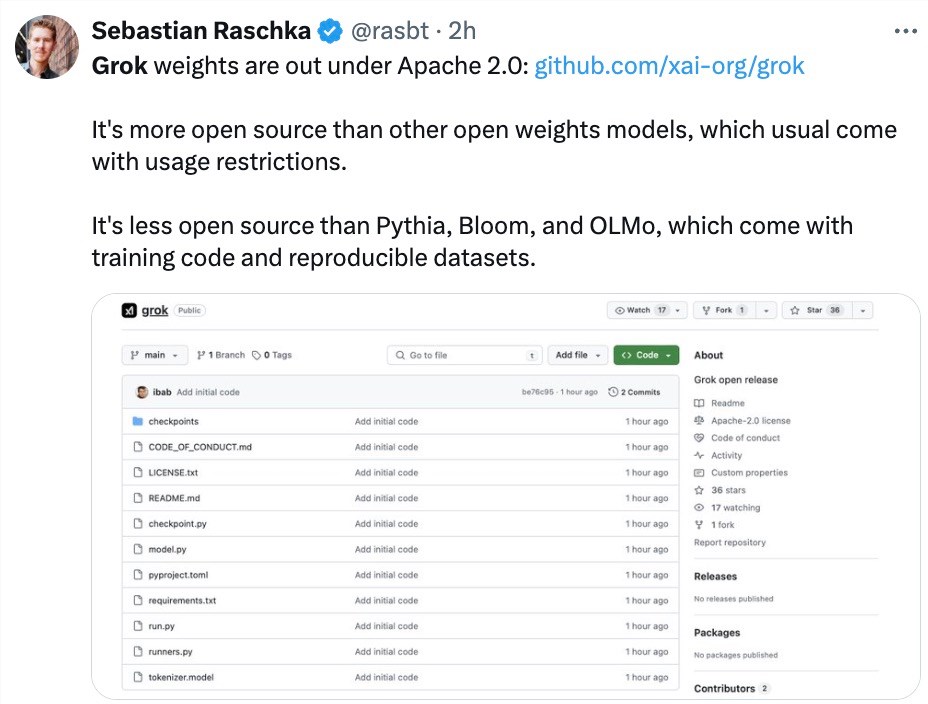
DeepMind 研究工程师 Aleksa Gordié 则预测,Grok-1的能力应该比 LLaMA-2要强,但目前尚不清楚有多少数据受到了污染。另外,二者的参数量也不是一个量级。

还有一位推特用户 @itsandrewgao 详细分析了 Grok-1的架构细节,并做出了一下几点总结。
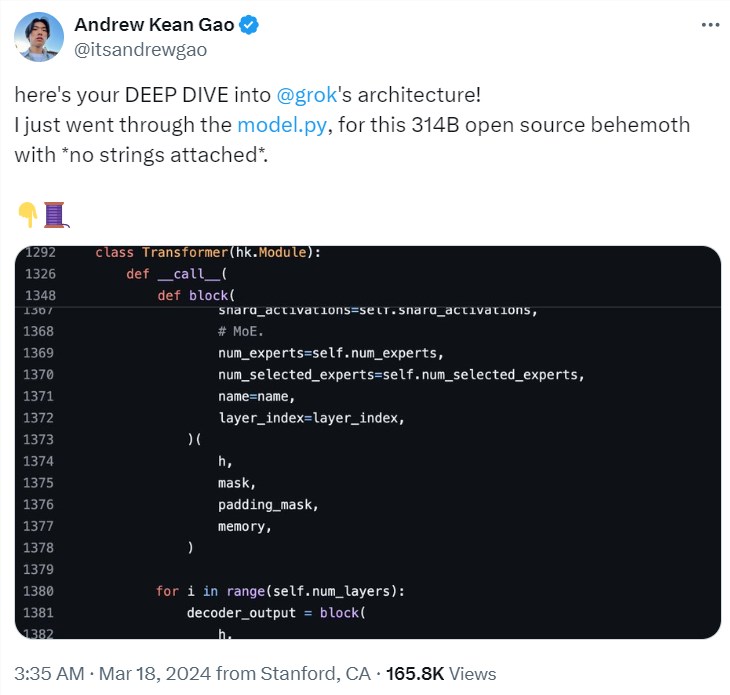
首先 Grok-1是8个专家的混合(2个活跃)、860亿激活参数(比Llama-270B还多),使用旋转嵌入而非固定位置嵌入。
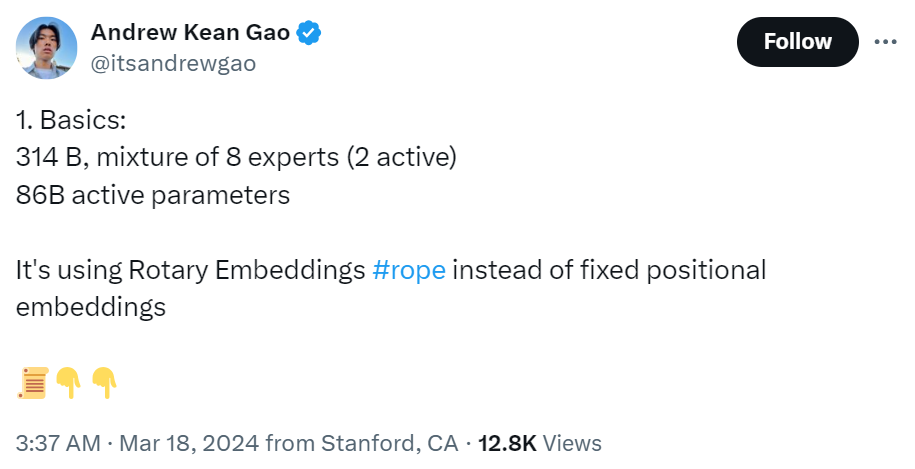
tokenizer 词汇大小为131,072(类似于 GPT-4)2^17,嵌入大小6,144(48*128),64个 transformer 层(sheesh), 每层都有一个解码器层:多头注意力块和密集块,键值大小128。
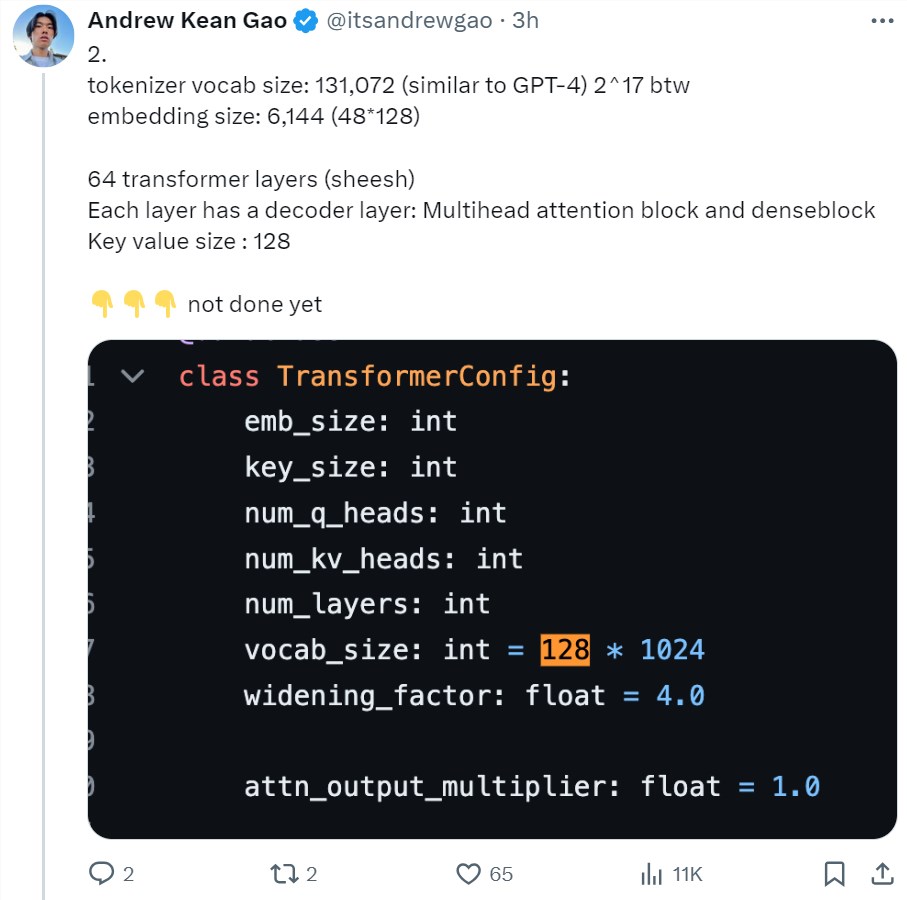
多头注意力块:48个 head 用于查询,8个用于键 / 值(KV)。KV 大小为128。密集块(密集前馈块):加宽因子8,隐藏层大小32768。每个 token 从8个专家中选择2个。
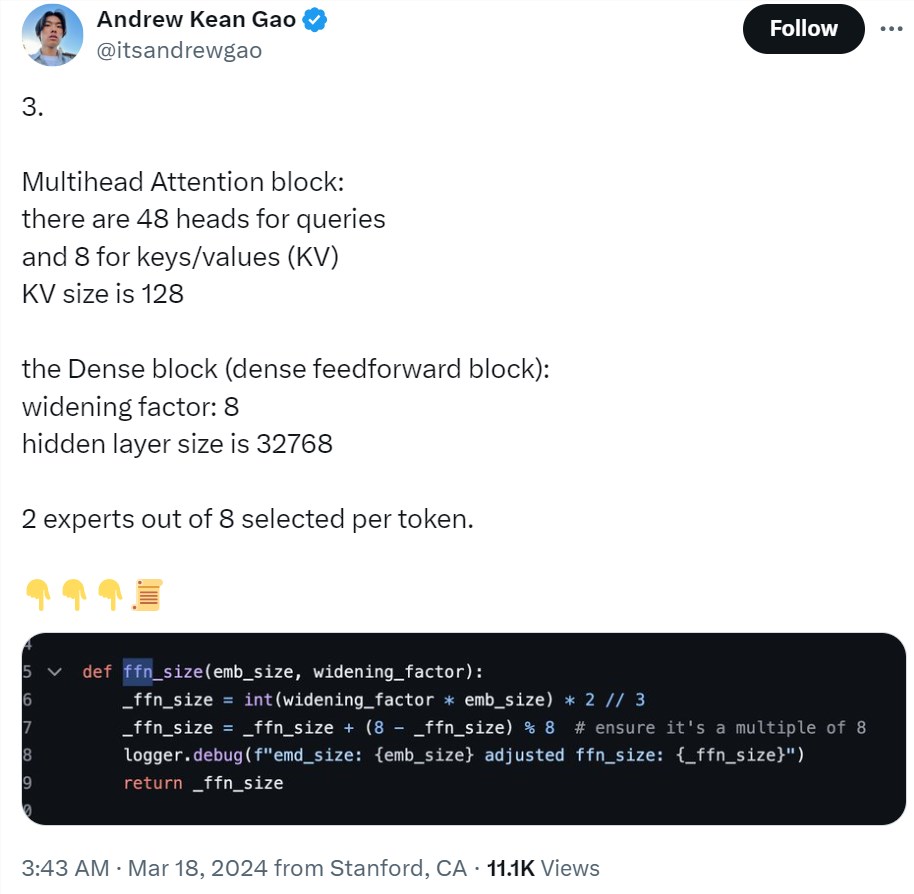
旋转位置嵌入大小为6144,与输入嵌入大小相同。上下文长度为8192tokens,精度为 bf16。
此外还提供了一些权重的8bit 量化内容。
当然,我们还是希望 xAI 官方能够尽快公布 Grok-1的更多模型细节。
Grok-1是个什么模型?能力如何?
Grok 是马斯克 xAI 团队去年11月推出的一款大型语言模型。在去年11月的官宣博客中(参见《马斯克 xAI 公布大模型详细进展,Grok 只训练了2个月》), xAI 写道:
Grok 是一款仿照《银河系漫游指南》设计的 AI,可以回答几乎任何问题,更难能可贵的是,它甚至可以建议你问什么问题!
Grok 在回答问题时略带诙谐和叛逆,因此如果你讨厌幽默,请不要使用它!
Grok 的一个独特而基本的优势是,它可以通过 X 平台实时了解世界。它还能回答被大多数其他 AI 系统拒绝的辛辣问题。
Grok 仍然是一个非常早期的测试版产品 —— 这是我们通过两个月的训练能够达到的最佳效果 —— 因此,希望在您的帮助下,它能在测试中迅速改进。
xAI 表示,Grok-1的研发经历了四个月。在此期间,Grok-1经历了多次迭代。
在公布了 xAI 创立的消息之后,他们训练了一个330亿参数的 LLM 原型 ——Grok-0。这个早期模型在标准 LM 测试基准上接近 LLaMA2(70B) 的能力,但只使用了一半的训练资源。之后,他们对模型的推理和编码能力进行了重大改进,最终开发出了 Grok-1,这是一款功能更为强大的 SOTA 语言模型,在 HumanEval 编码任务中达到了63.2% 的成绩,在 MMLU 中达到了73%。
xAI 使用了一些旨在衡量数学和推理能力的标准机器学习基准对 Grok-1进行了一系列评估:
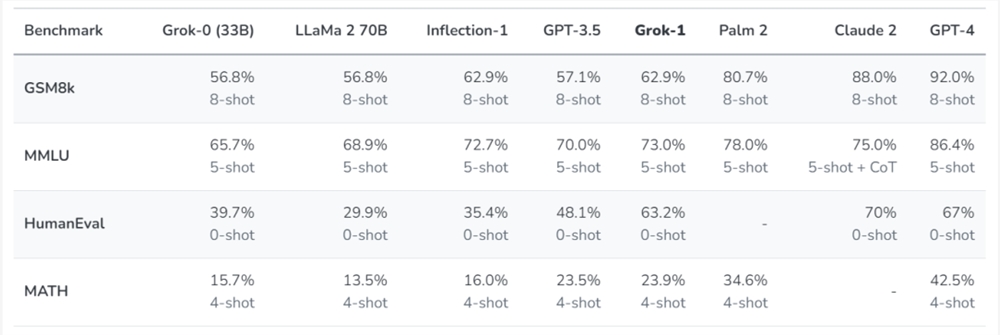
在这些基准测试中,Grok-1显示出了强劲的性能,超过了其计算类中的所有其他模型,包括 ChatGPT-3.5和 Inflection-1。只有像 GPT-4这样使用大量训练数据和计算资源训练的模型才能超越它。xAI 表示,这展示了他们在高效训练 LLM 方面取得的快速进展。
不过,xAI 也表示,由于这些基准可以在网上找到,他们不能排除模型无意中在这些数据上进行了训练。因此,他们在收集完数据集之后,根据去年5月底(数据截止日期之后)公布的2023年匈牙利全国高中数学期末考试题,对他们的模型(以及 Claude-2和 GPT-4模型)进行了人工评分。结果,Grok 以 C 级(59%)通过考试,Claude-2也取得了类似的成绩(55%),而 GPT-4则以68% 的成绩获得了 B 级。xAI 表示,他们没有为应对这个考试而特别准备或调整模型。

下面这个表格展示了 Grok-1的更多信息(来自2023年11月的博客,部分信息可能存在更新):
模型细节:Grok-1是一个基于 Transformer 的自回归模型。xAI 利用来自人类和早期 Grok-0模型的大量反馈对模型进行了微调。初始的 Grok-1能够处理8192个 token 的上下文长度。模型于2023年11月发布。
预期用途:Grok-1将作为 Grok 背后的引擎,用于自然语言处理任务,包括问答、信息检索、创意写作和编码辅助。
局限性:虽然 Grok-1在信息处理方面表现出色,但让人类检查 Grok-1的工作以确保准确性至关重要。Grok-1语言模型不具备独立搜索网络的能力。在 Grok 中部署搜索工具和数据库可以增强模型的能力和真实性。尽管可以访问外部信息源,但模型仍会产生幻觉。
训练数据:Grok-1发布版本所使用的训练数据来自截至2023年第三季度的互联网数据和 xAI 的 AI 训练师提供的数据。
评估:xAI 在一系列推理基准任务和国外数学考试试题中对 Grok-1进行了评估。他们与早期 alpha 测试者合作,以评估 Grok-1的一个版本,包括对抗性测试。目前,Grok 已经对一部分早期用户开启了封闭测试访问权限,进一步扩大测试人群。

在博客中,xAI 还公布了 Grok 的构建工程工作和 xAI 大致的研究方向。其中,长上下文的理解与检索、多模态能力都是未来将会探索的方向之一。
xAI 表示,他们打造 Grok 的愿景是,希望创造一些 AI 工具,帮助人类寻求理解和知识。
具体来说,他们希望达到以下目标:
收集反馈,确保他们打造的 AI 工具能够最大限度地造福全人类。他们认为,设计出对有各种背景和政治观点的人都有用的 AI 工具非常重要。他们还希望在遵守法律的前提下,通过他们的 AI 工具增强用户的能力。Grok 的目标是探索并公开展示这种方法;
增强研究和创新能力:他们希望 Grok 成为所有人的强大研究助手,帮助他们快速获取相关信息、处理数据并提出新想法。
他们的最终目标是让他们的 AI 工具帮助人们寻求理解。
在 X 平台上,Grok-1的开源已经引发了不少讨论。值得注意的是,技术社区指出,该模型在前馈层中使用了 GeGLU,并采用了有趣的 sandwich norm 技术进行归一化。甚至 OpenAI 的员工也发帖表示对该模型很感兴趣。
不过,开源版 Grok 目前还有些事情做不到,比如「通过 X 平台实时了解世界」,实现这一功能目前仍需要订阅部署在 X 平台上的付费版本。
鉴于马斯克对开源的积极态度,有些技术人员已经在期待后续版本的开源了。
微信下拉小程序新增音乐和音频 可限时免费听QQ音乐VIP歌曲
微信更新到8.0.38版本后,下拉小程序新增了音乐和音频功能,用户可以更方便地进入播放界面。其中,音乐板块由“今天”、“推荐歌单”和“视频号音乐人”三部分组成,用户可以直接播放歌曲,并支持滚动歌词和评论功能。站长网2023-07-18 17:22:560000AIGC撒下的种子,开出了不同香气的花
“不知道妙鸭都不懂最近的朋友圈了。”最近,一款名为“妙鸭相机”的AI相机小程序在朋友圈走红,引发了一轮朋友圈“个人写真”的分享热潮。这是一款基于AI人脸识别的AIGC应用,用户花费9.9元上传多张个人照片后就可以获得一个专属的数字分身,生成一套系统模板下的“个人写真”。然而面对上传21张清晰正面照片的操作,许多用户也表示了担忧。能否上传他人照片、照片是否会有其他用处等争议相继出现。站长网2023-08-09 20:03:260000开源机器学习库vLLM 提升大语言模型推理速度
要点:1、PagedAttention注意力算法通过采用类似虚拟内存和分页技术,可有效管理LLM推理中的关键值缓存内存。2、vLLM服务系统几乎零浪费关键值缓存内存,内部和请求之间灵活共享缓存,大大提升吞吐量。3、配备PagedAttention的vLLM相比HuggingFaceTransformers提升了24倍吞吐量,无需改变模型架构,重新定义了LLM服务的最佳水准。站长网2023-09-18 11:42:450004科技巨头工程师薪酬大揭秘:OpenAI工程师年薪达90万美元
划重点:⭐️OpenAI工程师年薪高达90万美元。⭐️谷歌、苹果、Facebook、微软等公司的工程师薪资水平各异,但均在百万美元以上。⭐️工程师在不同公司晋升至高级职位后,年薪可达数百万美元。站长网2024-04-26 12:14:210000DALL·E 3内部实测效果惊人!Karpathy生成逼真灵动「美国小姐」,50个物体一图全包
OpenAI作图神器DALL·E3内测开启,网友纷纷上手实测后,感慨强到令人发指。文生图从此告别「提示词时代」?一直以来,Midjourney横扫设计界,效果惊艳,让许多网友惊呼将淘汰一波打工人。如今,OpenAI官宣了新一代作图模型——DALL·E3,还将其与ChatGPT合并,画作细腻度令人发指。甚至,不用prompt,它能准确还原细节,为图片配上文字。站长网2023-09-25 09:15:560001