开源机器学习库vLLM 提升大语言模型推理速度
要点:
1、PagedAttention 注意力算法通过采用类似虚拟内存和分页技术,可有效管理LLM推理中的关键值缓存内存。
2、vLLM服务系统几乎零浪费关键值缓存内存,内部和请求之间灵活共享缓存,大大提升吞吐量。
3、配备PagedAttention的vLLM相比HuggingFace Transformers提升了24倍吞吐量,无需改变模型架构,重新定义了LLM服务的最佳水准。
近年来,大语言模型在改变人们的生活和职业方面影响越来越大,因为它们实现了编程助手和通用聊天机器人等新应用。但是,这些应用的运行需要大量硬件加速器如GPU,操作成本非常高。针对此,研究人员提出了PagedAttention注意力算法和vLLM服务系统,大大提升了LLM的推理吞吐量,降低了每次请求的成本。
PagedAttention将序列的关键值缓存分块,弹性管理不连续的内存空间,充分利用内存,实现内部和请求之间的缓存共享。配备PagedAttention的vLLM相比主流系统,在不改模型架构的前提下,提升了24倍吞吐量,达到了LLM服务的最佳水准。本研究为降低LLM在实际应用中的部署成本提供了重要途径。
项目地址:https://github.com/vllm-project/vllm
论文地址:https://arxiv.org/abs/2309.06180
vLLM利用PagedAttention来管理注意力键和值。配备PagedAttention的vLLM比HuggingFace Transformers提供的吞吐量高出多达24倍,而无需对模型架构进行任何更改,这重新定义了LLM服务的当前最先进技术水平。
与传统的注意力算法不同,它允许在非连续内存空间中持续存储键和值。PagedAttention将每个序列的KV缓存分为块,每个块都包含了一定数量的令牌的键和值。这些块在注意力计算期间由PagedAttention内核高效识别。由于这些块不一定需要是连续的,因此可以灵活管理键和值。
内存泄漏只会发生在PagedAttention中序列的最后一个块中。在实际使用中,这导致了有效的内存利用率,仅有4%的微小浪费。这种内存效率的提高使GPU的利用率更高。
此外,PagedAttention还具有有效的内存共享的另一个关键优势。PagedAttention的内存共享功能大大减少了用于并行采样和波束搜索等采样技术所需的额外内存。这可以使采样技术的速度提高多达2.2倍,同时将内存利用率降低多达55%。这种改进使得这些采样技术对大型语言模型(LLM)服务变得更加有用和有效。
研究人员还研究了该系统的准确性。他们发现,与FasterTransformer和Orca等尖端系统相比,vLLM以与之相同的延迟增加了2-4倍的知名LLM的吞吐量。更大的模型、更复杂的解码算法和更长的序列会导致更明显的改进。
生成式AI NPC角色开发平台inworld.ai获5000万美元融资
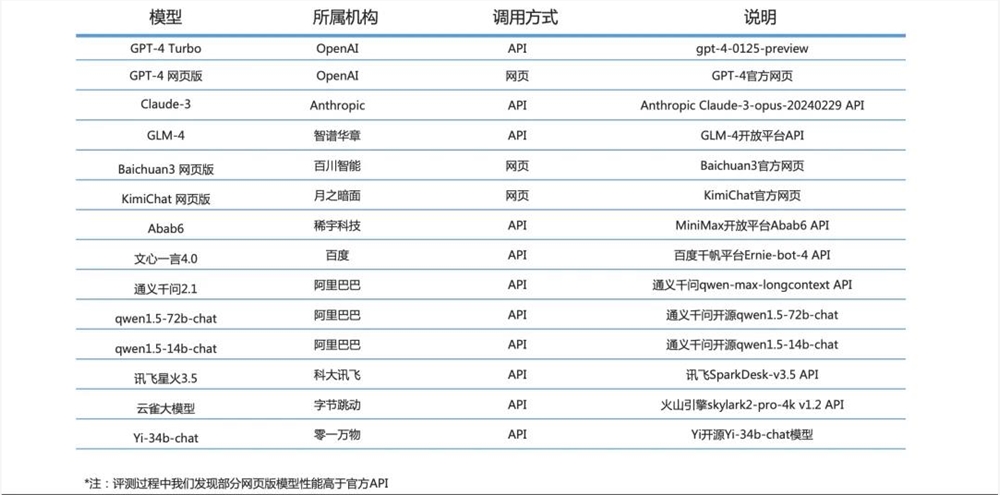
8月3日,生成式AI平台inworld.ai在官网上宣布获得5000万美元(约3.5亿元)融资,估值达到5亿美元,由LightspeedVenture领投,斯坦福大学、LG风险投资、三星Next等跟投。站长网2023-08-04 09:03:370000国内百模谁第一?清华14大LLM最新评测报告出炉,GLM-4、文心4.0站在第一梯队
【新智元导读】大模型混战究竟谁才是实力选手?清华对国内外14个LLM做了最全面的综合能力测评,其中GPT-4、Cluade3是当之无愧的王牌,而在国内GLM-4、文心4.0已然闯入了第一梯队。在2023年的「百模大战」中,众多实践者推出了各类模型,这些模型有的是原创的,有的是针对开源模型进行微调的;有些是通用的,有些则是行业特定的。如何能合理地评价这些模型的能力,成为关键问题。站长网2024-04-19 18:24:330000OpenAI源代码分享!实时AI Agent,20分钟开发语音智能体
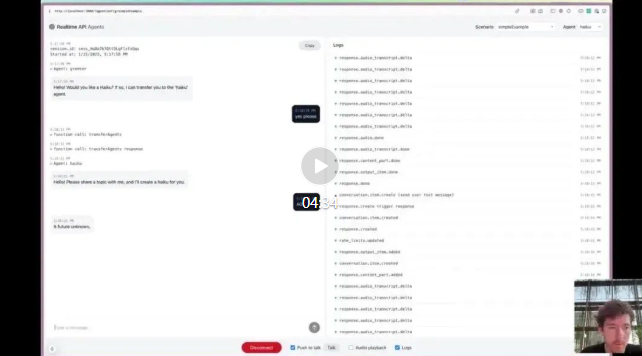
让你开发一个语音智能体应用原型大概需要多久?3天?5天?,OpenAI刚分享了一个基于Realtime(实时)API开发的多层级高级AIAgent,只用了20分钟!OpenAI已经在github公开了源代码,虽然只是一个演示demo但很快就突破了1200颗星,尤其是超高的开发效率让很多老手都感到惊讶。站长网2025-01-20 09:06:120000捐出大部分财富!OpenAI CEO奥特曼格局拉满:至少140亿元
快科技5月29日消息,据国外媒体报道,OpenAI首席执行官萨姆奥特曼及其丈夫奥利弗穆尔赫林宣布加入捐赠誓言,承诺捐出他们的大部分财富。奥特曼的身价至少为20亿美元(约合人民币144亿元),其中大部分财富来源于其对初创企业的投资,特别是对Reddit的成功投资。值得注意的是,尽管奥特曼在人工智能领域取得了巨大成功,但他并未持有OpenAI的股份。站长网2024-05-29 18:05:540000优秀App开发者突然被苹果封号:108878美元飞了、濒临倒闭
快科技11月24日消息,最近,来自智利的移动App开发者ViktorSeraleev公开控诉苹果莫名其妙封了自己的账号,导致惨重损失,四年多的努力顷刻间化为乌有,而且投诉无门。ViktorSeraleev创办了照片与视频App开发公司SarafanMobile,目前有六款产品,备受用户青睐,在第1天、第28天的留存率都遥遥领先,平均评分超过4.5,非常优秀的水平。站长网2023-11-25 10:14:070000