新型稀疏LVLM架构MoE-LLaVA 解决模型稀疏性相关的性能下降问题
要点:
1、MoE-LLaVA是一种新型稀疏LVLM架构,使用路由算法仅激活top-k专家。
2、MoE-LLaVA在各种视觉理解数据集上表现相当甚至超越了LLaVA-1.5-7B。
3、MoE-LLaVA采用三阶段的训练策略,以降低稀疏模型学习的难度。
MoE-LLaVA是一种新型稀疏LVLM架构,通过使用路由算法仅激活top-k专家,解决了通常与多模态学习和模型稀疏性相关的性能下降问题。研究者联合提出了一种新颖的LVLM训练策略,名为MoE-Tuning,以解决大型视觉语言模型(LVLM)的扩大参数规模会增加训练和推理成本的问题。
项目地址:https://github.com/PKU-YuanGroup/MoE-LLaVA
Demo地址:https://huggingface.co/spaces/LanguageBind/MoE-LLaVA
此外,MoE-LLaVA在各种视觉理解数据集上表现相当甚至超越了LLaVA-1.5-7B。该架构采用三阶段的训练策略,以降低稀疏模型学习的难度,从而建立稀疏LVLMs的基准,为未来研究开发更高效和有效的多模态学习系统提供宝贵的见解。
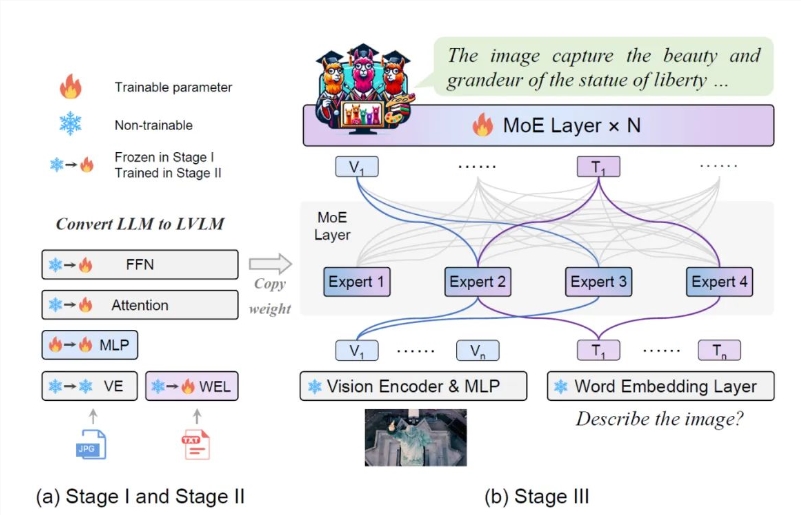
论文提出了MoE-LLaVA的三阶段训练策略。第一阶段的目标是让视觉token适应到LLM,使LLM具备理解图片实体的能力。第二阶段的目标是用多模态的指令数据来微调,以提高大模型的能力和可控性。
第三阶段使用第二阶段的权重作为初始化以降低稀疏模型学习的难度。在模型构建中,MoE-LLaVA是第一个基于LVLM搭载soft router的稀疏模型。研究团队在5个图片问答benchmark上验证了MoE-LLaVA的性能,并报告了激活的参数量和图片分辨率。
为了验证MoE-LLaVA的多模态理解能力,研究在4个benchmark toolkit上评估了模型性能。结果显示,MoE-LLaVA可以用更少的激活参数达到和稠密模型相当甚至超过的性能。研究还采用POPE评估pipeline验证MoE-LLaVA的物体幻觉,结果表明MoE-LLaVA展现出最佳的性能,以较少的激活参数超过了LLaVA。
MoE-LLaVA能够帮助我们更好地理解稀疏模型在多模态学习上的行为,为未来研究和开发提供了有价值的见解。
字节提出新方法GPE AI看视频可自动找“高能时刻”
要点:1、字节跳动联合中科院自动化研究所提出新方法,用AI快速检测视频中的高光片段,实现对输入视频长度和高光长度的灵活提取。2、字节跳动联合中科院自动化研究所标注了用于域增量学习的美食视频数据集LiveFood,提出了基于原型学习的解决方案。3、GPE使用高光原型学习的方案,在视频帧级别上做二分类任务,判断视频帧属于高光还是非高光,取得了良好的高光检测性能。站长网2024-01-22 09:39:510000小心,又一波封号潮正在进行
最近几天,在见实会员群和交流群中,不断有运营团队表示自己名下企微账号被封,且频次越来越频繁。其实早在去年,见实就已发出两篇文章提出预警:违规的原因比较多,比如使用外挂、发恶意信息、发违法信息等。很多企业基本上不存在发布违法信息的情况,只是想通过外挂来提效。但通过群友们反馈可见,企微在甄别第三方外挂的敏感程度越来越高,外挂导致的封号风险正急剧攀升。站长网2024-04-24 17:17:400000网易天成刷屏,抖音电商会员日做对了什么?
会员有礼、入会领券、进群拿折扣、升级赢福利……在人们的消费生活中,这些字眼正变得越来越常见。如今,“会员”已然成为电商领域不容忽视的关键词。放眼望去,大小商家们不约而同地投身会员体系建设,摸索出了多种多样的VIP玩法。站长网2023-08-26 17:53:390000百度:在未来几个季度加大对大语言模型和生成式AI的投入
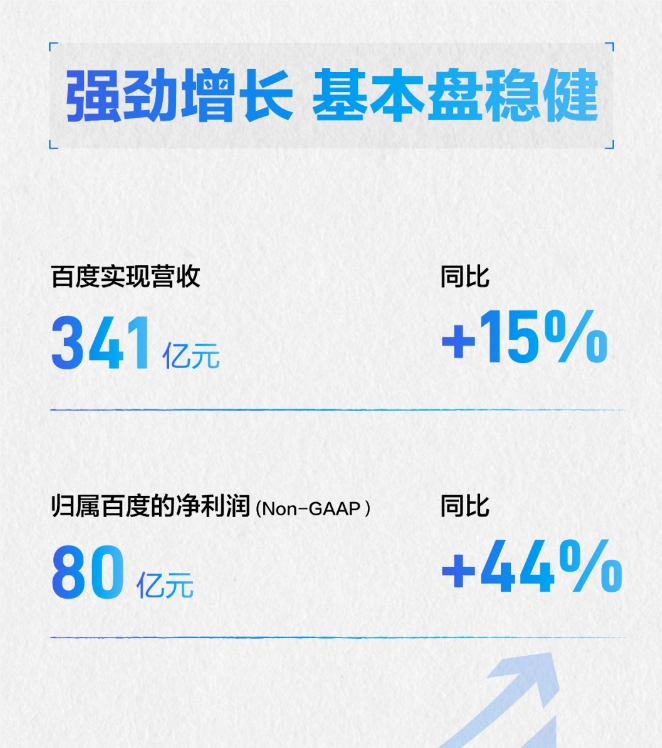
今日,百度发布了2023年第二季度财报,该季度百度总营收达到了341亿元,同比增长15.2%。站长网2023-08-22 22:30:450000蔚来推出自研智能驾驶芯片“神玑”:性能超业界旗舰2.5倍
在蔚来2023NIODay上,李斌宣布推出首颗自研智能驾驶芯片神玑NX9031。这颗芯片的目标是实现业界四颗旗舰智能驾驶芯片的性能,同时优化效率和成本。神玑NX9031采用5纳米车规工艺,拥有超过500亿颗晶体管,并首次采用三色和CPU架构。据介绍,该芯片每秒能运行超6万亿条指令,性能超业界旗舰2.5倍,能并行处理多项实时任务,包括感知、计算、规控、数据闭环和群体智能等。0000