字节提出新方法GPE AI看视频可自动找“高能时刻”
要点:
1、字节跳动联合中科院自动化研究所提出新方法,用AI快速检测视频中的高光片段,实现对输入视频长度和高光长度的灵活提取。
2、字节跳动联合中科院自动化研究所标注了用于域增量学习的美食视频数据集LiveFood,提出了基于原型学习的解决方案。
3、GPE使用高光原型学习的方案,在视频帧级别上做二分类任务,判断视频帧属于高光还是非高光,取得了良好的高光检测性能。
AI技术在视频领域的应用一直备受关注,通过AI快速检测视频中的高光片段,可以实现观众直接空降到精彩时刻,主播也可以复盘自己的表现。针对视频领域增量学习的困境,字节跳动联合中科院自动化研究所标注了用于域增量学习的美食视频数据集LiveFood,并提出了基于原型学习的解决方案。该方法使用高光原型学习的方案,在视频帧级别上做二分类任务,判断视频帧属于高光还是非高光,并取得了良好的高光检测性能。通过这些努力,AI技术在视频领域应用的前景更加广阔。

项目地址:https://top.aibase.com/tool/livefood
通过AI快速检测视频中的高光片段,观众可以直接空降到精彩时刻,主播也可以复盘自己的表现。针对视频域增量学习困境,字节跳动联合中科院自动化研究所标注了美食视频数据集LiveFood,并提出基于原型学习的解决方案。
字节跳动联合中科院自动化所提出新方法,用AI快速检测视频中的高光片段,实现对输入视频长度和高光长度的灵活提取。同时,标注了用于域增量学习的美食视频数据集LiveFood,并提出了基于原型学习的解决方案。AI技术在视频领域的应用前景更加广阔。
字节跳动联合中科院自动化所提出新方法,用AI快速检测视频中的高光片段,实现对输入视频长度和高光长度的灵活提取。该方法取得了良好的高光检测性能,并对视频领域增量学习问题有重要意义,为AI技术在视频领域的应用打开了新的局面。
腾讯手机QQ 9版本正式上线 采用QQNT技术架构驱动
腾讯宣布QQ9正式焕新上线。QQ9是一款全新版本的QQ,采用了全新的QQNT技术架构驱动,使性能得到升级,交互体验更加流畅。QQ9的界面进行了全新设计,使社交更加流畅。在新版本中,QQ的启动页、登录页、消息列表页、关于页等页面的UI进行了刷新,全新的QQ9焕彩上线。聊天界面和设置界面的顶部栏调整为浅色显示,聊天界面的排版和图标也进行了优化,使视觉效果更加简单纯粹。站长网2023-12-21 08:45:270000自动驾驶汽车运输安全服务指南发布 自动驾驶失效时至少要存90秒信息
近日,交通运输部办公厅印发了《自动驾驶汽车运输安全服务指南(试行)》。这份指南旨在确保自动驾驶汽车在运输过程中的安全性。其中明确指出,自动驾驶运输经营者应确保车辆技术状况良好,严格按照车辆使用说明书来运行。此外,自动驾驶汽车还应具备车辆运行状态信息记录、存储和传输的功能,以便向自动驾驶运输经营者和运营地有关主管部门实时传输关键运行状态信息。0000AI幻觉之争!周鸿祎碰撞李彦宏又唱反调
快科技11月21日消息,在2024世界互联网大会乌镇峰会期间,360集团创始人周鸿祎就百度创始人李彦宏在百度世界大会上关于大模型已基本解决幻觉问题”的言论,表达了自己的不同看法。周鸿祎首先对李彦宏表示了尊重,但随后指出,幻觉是大模型的一种固有特性,而非缺点。0000抖音实行热点内容核实机制 将进行当事人、疑似演绎内容核实
抖音发布关于实行热点内容核实机制的公告称,为维护良好的社区生态,落实“清朗·整治‘自媒体’无底线博流量”专项工作要求,切实打击“不择手段蹭炒社会热点”“自导自演式造假”等违规行为,抖音即日起实行热点内容核实机制,具体分为热点事件当事人核实和疑似演绎内容核实两项。一、热点当事人核实站长网2024-05-28 07:24:150000把字节当成token,清华和微软刚掏出来的bGPT到底什么来头
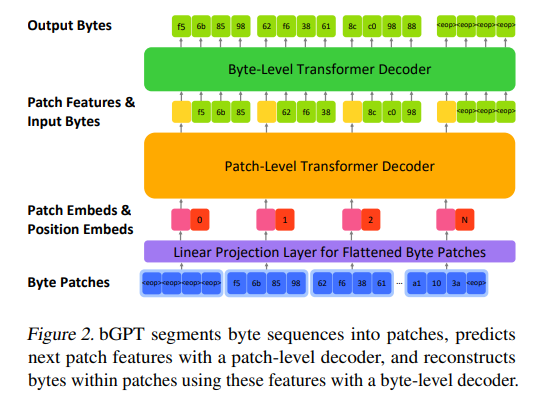
相信你或多或少对GPT有一定的了解,但我赌你没听说过bGPT。bGPT的意思是byteGPT,即字节GPT。这是一种专门设计用于处理二进制数据和模拟数字世界的深度学习模型。简单概括,bGPT突破了传统语言模型的局限,能够直接理解和操作二进制数据,拓展了深度学习在原生二进制数据领域的应用边界。站长网2024-03-12 14:04:130000