首个图像序列基准测试Mementos开源 GPT-4V/Gemini竟看不懂漫画!
要点:
1. 马里兰大学联合北卡教堂山发布了首个专为多模态大语言模型设计的图像序列基准测试Mementos,涵盖真实世界、机器人和动漫图像序列,挑战MLLM在连续图像上的推理能力。
2. 对GPT-4V和Gemini等多模态大语言模型进行测试时发现,它们在图像序列推理中的表现不足20%,甚至在漫画数据集中对人物行为的正确率令人惊讶低下,揭示了它们在处理幻觉、对象识别和行为理解上的不足。
3. Mementos测试发现MLLM在图像序列推理中容易产生两种幻觉:对象幻觉和行为幻觉。错误的对象识别可能导致后续行为识别的不准确,共现效应加剧了行为幻觉问题,而行为幻觉的雪球效应导致错误逐渐累积和加剧。
近期,马里兰大学与北卡教堂山合作发布了Mementos,这是专为多模态大语言模型(MLLM)设计的图像序列基准测试,旨在全面测试这些模型对于真实世界、机器人和动漫图像序列的推理能力。然而,测试结果令人震惊,GPT-4V和Gemini等MLLM在漫画数据集上的准确率不足20%。这揭示了这些模型在处理图像序列中的幻觉、对象和行为理解方面的明显不足。

项目地址:https://mementos-bench.github.io/
测试中发现MLLM容易出现对象幻觉和行为幻觉。对象幻觉是指模型产生不存在的对象,而行为幻觉则是模型产生对象未进行的动作。这些问题的根本原因在于对象识别错误可能导致后续行为识别的不准确,共现效应加剧了行为幻觉问题,而行为幻觉的雪球效应导致错误逐渐累积和加剧。这对于MLLM在处理图像序列中的推理能力提出了重要的挑战。
在具体的图像案例中,MLLM对于漫画中的场景和行为理解存在明显的困难,例如将人物行为错误识别为持武器相互打斗。作者还指出,这些MLLM对于动漫领域的不熟悉需要大幅度的优化和预训练。此外,测试结果还表明,训练数据的局限性对于开源MLLM的推理能力有直接影响,强调了训练数据的重要性。
Mementos测试为多模态大语言模型在图像序列推理方面提供了全面的评估,揭示了它们在处理连续图像中的幻觉、对象和行为理解方面的困难。这对于推动MLLM在图像领域的发展提出了挑战,并强调了进一步研究和优化的迫切性。
消息称网易起诉暴雪欠款3亿 此前双方表示不再续约合作
据36氪报道,近日,上海网之易网络科技发展有限公司在上海提起诉讼,指控暴雪娱乐有限公司违反了系列许可协议,要求退还3亿欠款。这笔款项包括网之易已全额支付的停服游戏的相关退款、未售游戏商品库存的预付款项以及数款未开发游戏的预付保证金等。站长网2023-04-24 14:41:240000“怼”出百万粉丝,反差感穿搭博主速通小红书
11月涨粉榜刚刚出炉,我们先来一起看榜:从整体趋势来看,博主们11月的涨粉情况相较上月有了明显提升,达到全年中比较高的水平。聚焦到上榜博主,首先,拿下11月涨粉榜TOP1的是短视频“白月光”@李子柒,11月共涨粉167.74W,也是今年少有的单月涨粉量突破百万的博主。站长网2024-12-12 17:08:340000零跑汽车获Stellantis投资15亿欧元 后者成零跑汽车战略股东
今日开盘,零跑汽车港股股价上涨11.41%。今日早些时候,零跑汽车官方宣布,Stellantis集团和零跑汽车创建了双方的全球战略伙伴关系。双方计划共同组建一家名为“零跑国际(LeapmotorInternational)”的合资企业,通过借助Stellantis集团在全球范围内的广泛商业资产、实力和积淀,该合资企业将加速并扩张零跑汽车高技术含量和极具品价比的产品在全球的销售。站长网2023-10-26 10:09:270000Mamba架构遭同行评审质疑,LeCun自曝类似经历
要点:Mamba架构论文,去年底发布,挑战Transformer,但在ICLR2024同行评审中得到低分,可能被拒收。LeCun自曝类似经历,指出自己曾有类似经历,即使成就显著的论文也可能被顶会拒收。审稿人给出低分的理由,主要集中在对Mamba模型设计和实验的质疑,作者进行rebuttal但未得到重视。站长网2024-01-26 16:46:27000212306推出静音车厢 提供 “一对一” 到站提醒服务
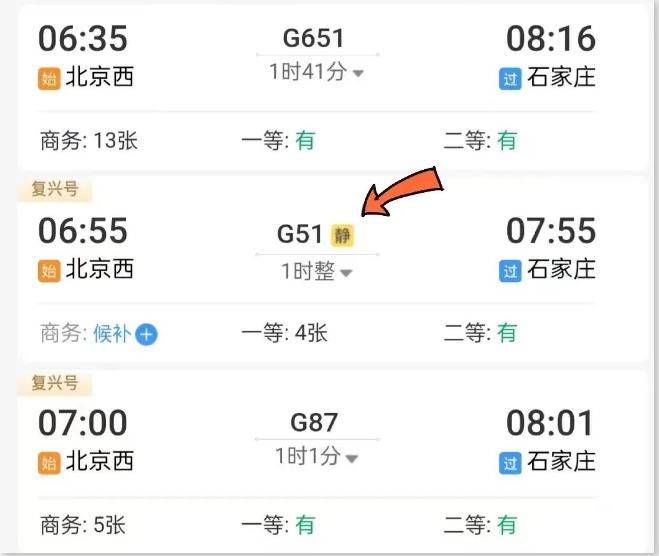
近日,铁路部门在京沪、京广、成渝高铁等部分复兴号动车组列车上设置了静音车厢。乘客可以通过铁路12306APP购买静音车厢的车票,选择带有“静”字的二等座车票,并勾选“请优先为我分配静音车厢席位”的选项。系统会在有余票的情况下自动分配静音车厢车票。站长网2023-10-13 08:53:240000