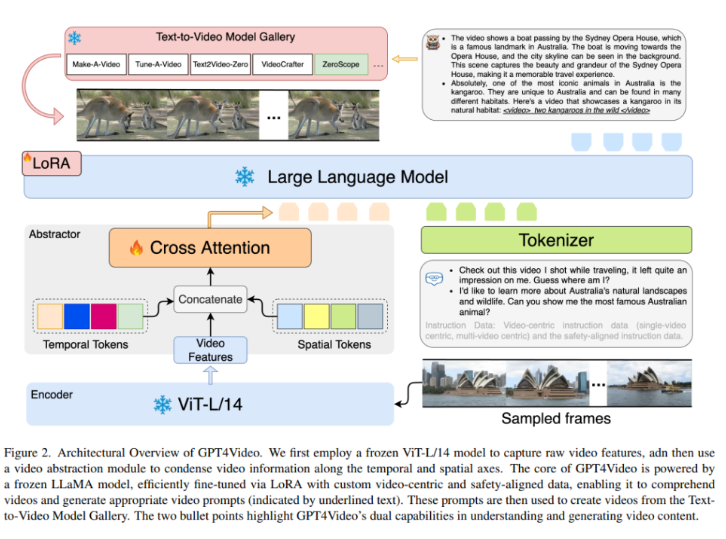
ConvNet与Transformer谁更强?Meta评测4个领先视觉模型,LeCun转赞
【新智元导读】当前的视觉模型哪个更好?Meta团队最新一波研究来了。
如何根据特定需求选择视觉模型?
ConvNet/ViT、supervised/CLIP模型,在ImageNet之外的指标上如何相互比较?
来自MABZUAI和Meta的研究人员发表的最新研究,在「非标准」指标上全面比较了常见的视觉模型。

论文地址:https://arxiv.org/pdf/2311.09215.pdf
就连LeCun称赞道,非常酷的研究,比较了相似大小的ConvNext和VIT架构,无论是在监督模式下训练,还是使用CLIP方法进行训练,并在各种属性上进行了比较。

超越ImageNet准确性
计算机视觉模型格局,变得越来越多样复杂。
从早期的ConvNets到Vision Transformers的演进,可用模型的种类在不断扩展。
类似地,训练范式已经从ImageNet上的监督训练,发展到自监督学习、像CLIP这样的图像文本对训练。

在标志着进步的同时,这种选择的爆炸式增长给从业者带来了重大挑战:如何选择适合自己的目标模型?
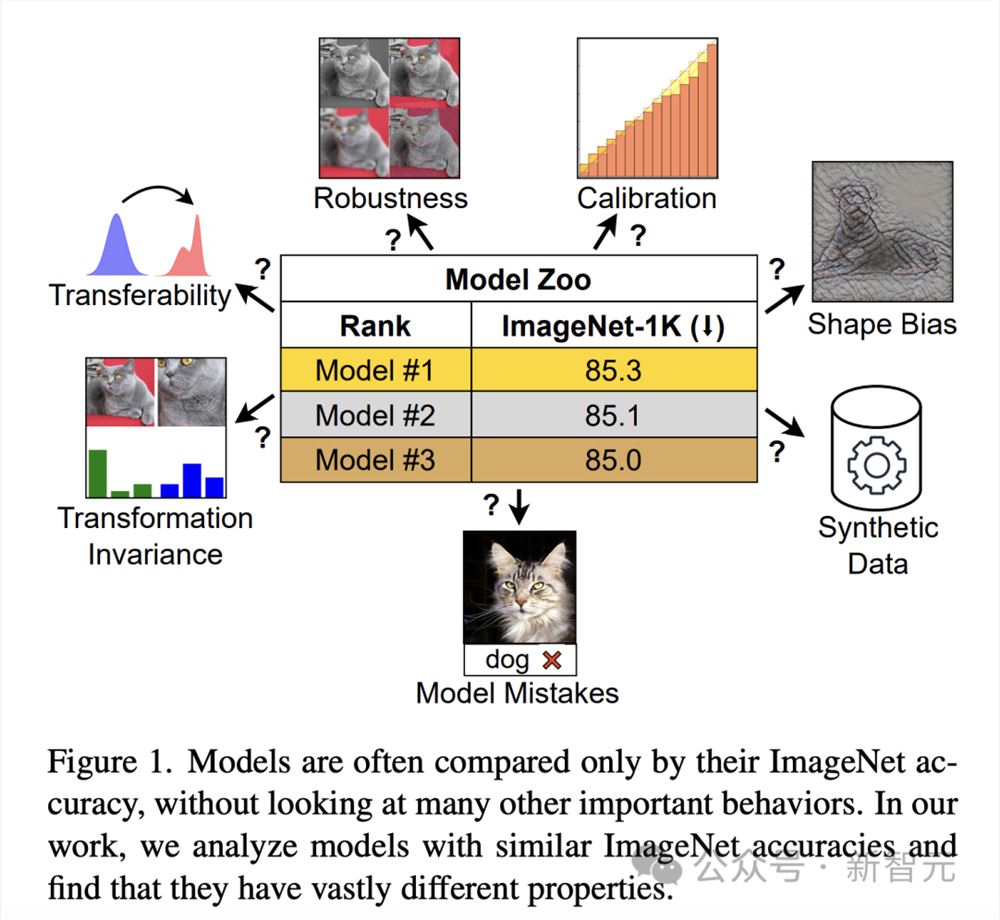
一直以来,ImageNet准确率一直是评估模型性能的主要指标。自从引发深度学习革命以来,它已经推动了人工智能领域显著的进步。
不过,它却无法衡量因不同架构、训练范式和数据而产生的细微差别的模型。
如果仅根据ImageNet的准确度来判断,具有不同属性的模型可能看起来很相似(图1)。随着模型开始过度拟合ImageNet的特性,精度达到饱和,这种局限性就会变得更加明显。
为了弥补差距,研究人员对ImageNet准确性之外的模型行为进行了深入探索。
为了研究架构和训练目标对模型性能的影响,具体比较了Vision Transformer (ViT)和ConvNeXt。这两种现代架构的ImageNet-1K验证精度和计算要求相当。
此外,研究对比了以DeiT3-Base/16和ConvNeXt-Base为代表的监督模型,以及OpenCLIP基于CLIP模型的视觉编码器。

结果分析
研究人员的分析旨在,研究无需进一步训练或微调即可评估的模型行为。
这种方法对于计算资源有限的从业人员尤为重要,因为他们通常依赖于预训练模型。
具体分析中,虽然作者认识到对象检测等下游任务的价值,但重点是那些能以最小的计算需求提供洞察力的特性,以及反映对真实世界应用非常重要的行为的特性。
模型错误
ImageNet-X是一个对ImageNet-1K进行了扩展的数据集,其中包含16个变化因素的详细人工标注,从而能够深入分析图像分类中的模型错误。
它采用错误率(越低越好)来量化模型在特定因素上,相对于整体准确性的表现,从而对模型错误进行细致入微的分析。ImageNet-X 的结果表明:
1. 相对于其ImageNet准确性,CLIP模型比受监督的模型犯的错误更少。
2. 所有模型都主要受到遮挡等复杂因素的影响。
3. 纹理是所有模型中最具挑战性的因素。

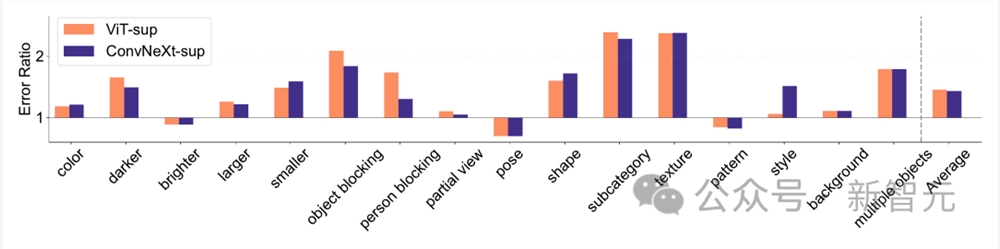
形状/纹理偏差
形状/纹理偏差会检验模型,是否依赖于纹理快捷方式,而不是高级形状提示。
这种偏向可以通过结合不同类别的形状和纹理的提示冲突图像来研究。
这种方法有助于了解与纹理相比,模型的决策在多大程度上是基于形状的。
研究人员对提示冲突数据集上的形状-纹理偏差进行了评估,发现CLIP模型的纹理偏差小于监督模型,而ViT模型的形状偏差高于ConvNets。

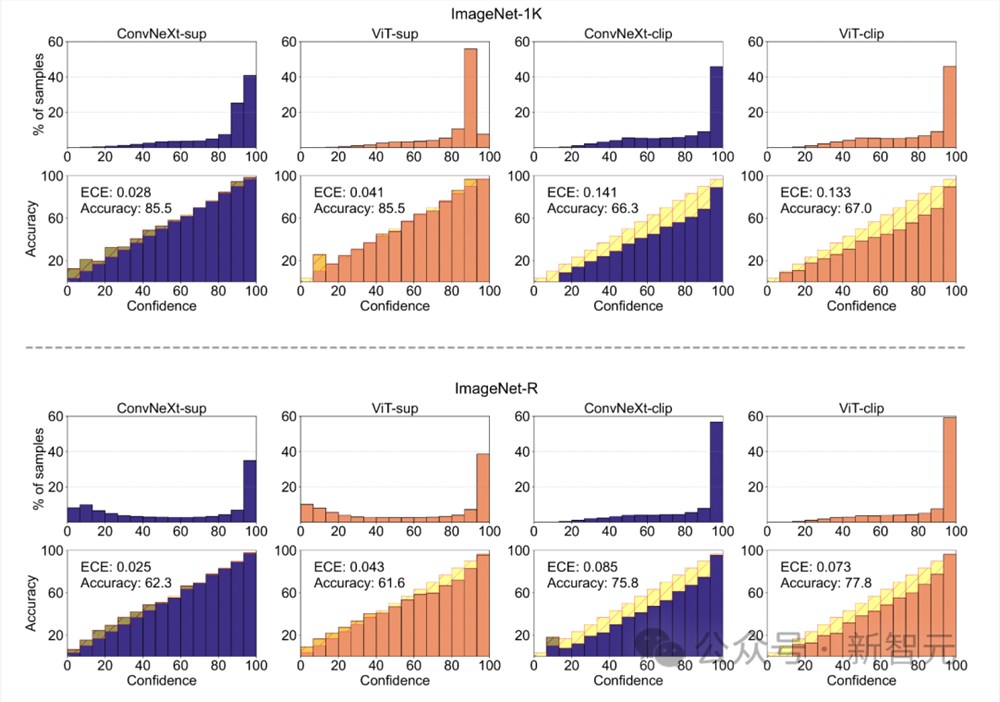
模型校准
校准可量化模型的预测置信度与其实际准确度是否一致。
这可以通过预期校准误差 (ECE) 等指标,以及可靠性图和置信度直方图等可视化工具进行评估。
研究人员在ImageNet-1K和ImageNet-R上对校准进行了评估,将预测分为15个等级。在实验中,观察到以下几点:
- CLIP模型置信度高,而监督模型则略显不足。
- 有监督的ConvNeXt比有监督的ViT校准得更好。
健壮性和可移植性
模型的健壮性和可移植性,是适应数据分布变化和新任务的关键。
研究人员使用不同的ImageNet变体评估了稳健性,发现虽然ViT和ConvNeXt模型具有类似的平均性能,但除了ImageNet-R和ImageNet-Sketch之外,监督模型在稳健性方面通常优于CLIP。
在可移植性方面,使用VTAB基准测试对19个数据集进行评估,监督ConvNeXt优于ViT,几乎与CLIP模型的性能相当。

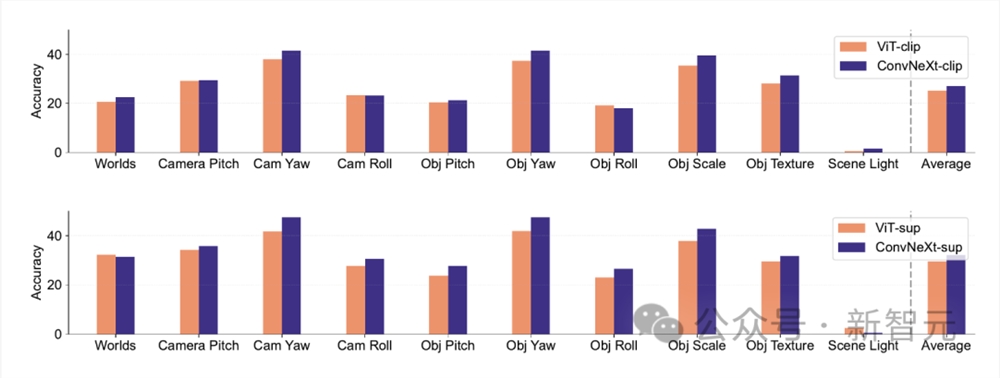
合成数据
像PUG-ImageNet这样的合成数据集,可以精确控制相机角度和纹理等因素,成为一种很有前途的研究途径,因此研究人员根据合成数据分析模型的性能。
PUG-ImageNet包含逼真的ImageNet图像,这些图像具有照明等因素的系统变化,性能以绝对最高准确率来衡量。
研究人员提供了PUG-ImageNet中不同因素的结果,发现ConvNeXt在几乎所有因素上都优于ViT。
这表明ConvNeXt在合成数据上优于ViT,而CLIP模型的差距较小,因为CLIP模型的准确率低于监督模型,这可能与原始ImageNet的准确率较低有关。
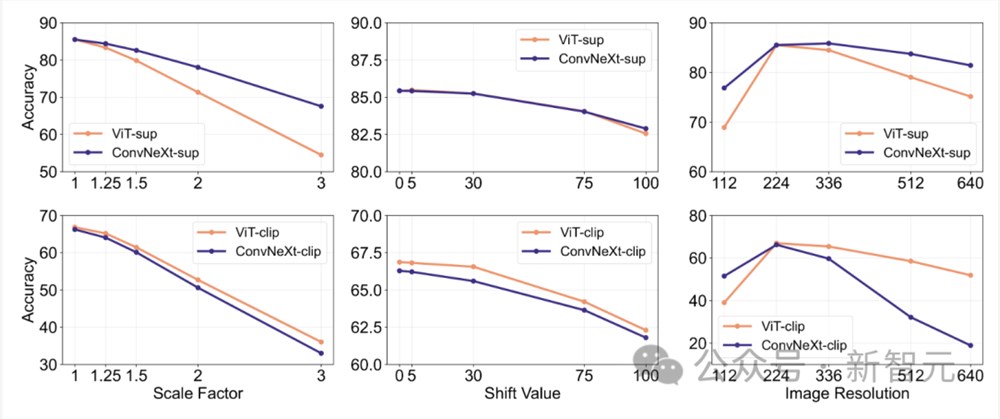
特征不变性
特征不变性是指模型能够产生一致的表征,不受输入转换的影响,从而保留语义,如缩放或移动。
这一特性使模型能够在不同但语义相似的输入中很好地泛化。
研究人员的方法包括,调整图像大小以实现比例不变性,移动裁剪以实现位置不变性,以及使用内插位置嵌入调整ViT模型的分辨率。
在有监督的训练中,ConvNeXt的表现优于ViT。
总体而言,模型对尺度/分辨率变换的鲁棒性高于对移动的鲁棒性。对于需要对缩放、位移和分辨率具有较高鲁棒性的应用,研究结果表明有监督的ConvNeXt可能是最佳选择。
研究人员发现,每种模型都有自己独特的优势。
这表明模型的选择应该取决于目标用例,因为标准的性能指标可能会忽略关键任务特定的细微差别。
此外,许多现有的基准是从ImageNet派生出来的,这对评估有偏见。开发具有不同数据分布的新基准,对于在更具现实代表性的背景下评估模型至关重要。
ConvNet vs Transformer
- 在许多基准测试中,有监督的ConvNeXt比有监督的VIT具有更好的性能:它更好地校准,对数据转换不变,表现出更好的可转移性和健壮性。
- 在合成数据上,ConvNeXt的表现优于ViT。
- ViT有较高的形状偏向。
Supervised vs CLIP
- 尽管CLIP模型在可转移性方面更好,但监督的ConvNeXt在这项任务上表现出了竞争力。这展示了有监督的模型的潜力。
- 监督模型更擅长稳健性基准,这可能是因为这些模型是ImageNet的变体。
- CLIP模型具有较高的形状偏差,与其ImageNet精度相比,分类错误较少。
Adobe回应了有关AI生成加沙爆炸图像的争议
日前,Adobe对有关AI生成的加沙爆炸图像的争议做出回应。这一争议爆发在拜登总统关于AI使用潜在社会危害的讲话后的一周,涉及一张未标记为AI生成的加沙爆炸库存图像被多家小型博客和网站使用。澳大利亚新闻媒体Crikey首次报道了这一图像,以及AdobeStock上的其他逼真加沙图像,引发了X(前身为Twitter)上的抵制浪潮。站长网2023-11-08 11:53:400000腾讯与悉尼大学联手打造GPT4Video:显著提升大语言模型视频生成能力
**划重点:**1.🤖**GPT4Video简介:**腾讯与悉尼大学合作推出GPT4Video,这是一个统一的多模态框架,赋予大型语言模型(LLMs)独特的视频理解和生成能力。2.🧠**技术亮点:**GPT4Video通过引入视频理解模块、LLM主体和视频生成组件,弥补了现有多模态语言模型在生成多模态输出方面的不足。站长网2023-12-07 09:36:470000用iPhone 5s拍照火了!取代CCD成小姐姐最爱
快科技9月2日消息,苹果已经宣布9月13日召开发布会,届时iPhone15系列将正式登场。最近一段时间,iPhone15系列也成了毫无疑问的机圈热门产品,但同时火起来的还有十年前的iPhone5s。最近在多个社交平台上,都出现很多女性用户喜欢用iPhone5s拍照,直呼YYDS”。这么一款在2013年9月10日发布的老古董走红,让很多人意想不到。站长网2023-09-02 15:45:590001今年双十一各家都怎么玩?电商向左,主播向右
近几年,随着直播带货等多种购物形式的丰富以及消费观的演变,电商大促的热度远远不比以前了。曾经凑满减、抢红包、熬夜剁手的促销戏码也逐渐在做减法,剁手族们也更加理性了。那么,面对新的消费趋势,各大电商平台和头部带货主播们又该如何玩出新花样?不如我们一起来看看。首先双十一的主力——电商平台们。淘宝天猫主打“全网最低价”近日,淘天集团在天猫双11启动会上宣布,将把“全网最低价”定为核心目标。站长网2023-10-18 23:49:000000从找眼镜到当导购,我和豆包的24小时“室友”体验
“太麻烦了。”周二晚上,我们在北京最繁华的商圈随机询问了10位年轻人,询问他们使用AI助手的习惯。答案出奇一致:都曾抱着好奇心尝试过,但因为使用体验与日常生活脱节,最终都放弃了。什么叫“麻烦”?下载独立app、思考问什么问题、反复调试prompt——每一步都是门槛。这让我们反思:AI产品的使用门槛能否再低一点?低到真正“无感”的程度?0000