腾讯与悉尼大学联手打造GPT4Video:显著提升大语言模型视频生成能力
**划重点:**
1. 🤖 **GPT4Video简介:** 腾讯与悉尼大学合作推出GPT4Video,这是一个统一的多模态框架,赋予大型语言模型(LLMs)独特的视频理解和生成能力。
2. 🧠 **技术亮点:** GPT4Video通过引入视频理解模块、LLM主体和视频生成组件,弥补了现有多模态语言模型在生成多模态输出方面的不足。
3. 🌐 **实验证明:** GPT4Video在多个多模态基准测试中表现出色,包括开放式问答、视频字幕和文本到视频生成,彰显其在整合先进视频理解和生成功能方面的卓越性能。
在多模态大型语言模型(MLLMs)领域取得显著进展的同时,尽管在输入端多模态理解方面取得了显著进展,但在多模态内容生成领域仍存在明显的空白。为填补这一空白,腾讯人工智能实验室与悉尼大学联手推出了GPT4Video,这是一个统一的多模态框架,赋予大型语言模型(LLMs)独特的视频理解和生成能力。
研究团队的主要贡献可以总结如下:
1.引入了GPT4Video,这是一个多功能框架,为LLMs提供了视频理解和生成的能力。
2. 提出了一种简单而有效的微调方法,旨在增强视频生成的安全性,成为常用RLHF方法的一种吸引人的替代方案。
3. 释放数据集,以促进未来在多模态LLMs领域的研究。
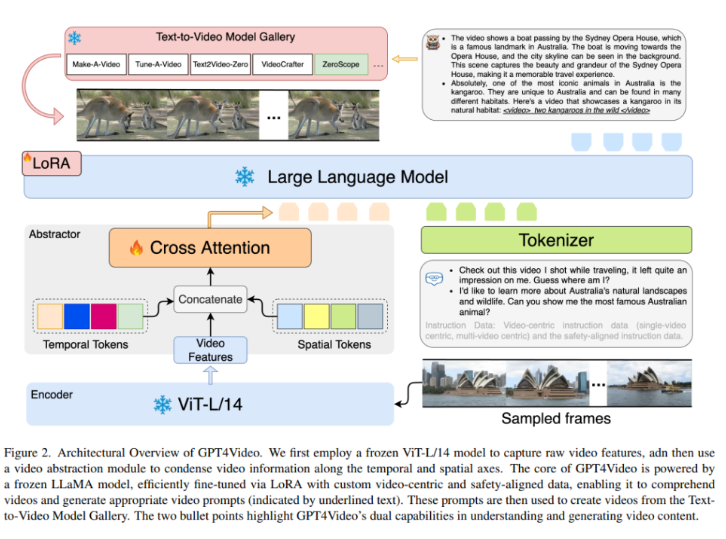
GPT4Video是对现有多模态大型语言模型(MLLMs)局限性的回应,尽管这些模型在处理多模态输入方面表现出色,但在生成多模态输出方面存在不足。GPT4Video的架构包括三个重要组件:
1. **视频理解模块:** 利用视频特征提取器和视频摘要生成器,将视频信息编码并对齐到LLM的词嵌入空间。
2. **LLM主体:** 借鉴LLaMA结构,采用参数高效微调(PEFT)方法,特别是LoRA,同时保留原始预训练参数。
3. **视频生成组件:** 通过精心构建的指令跟踪数据集,使LLM生成模型库中模型的提示。
团队首先利用冻结的ViT-L/14模型捕捉原始视频特征,然后使用视频抽象模块在时间和空间轴上压缩视频信息。GPT4Video的核心由冻结的LLaMA模型驱动,通过LoRA和自定义的视频中心化、安全对齐数据进行高效微调。这使其能够理解视频并生成适当的视频提示,随后用于从Textto-Video模型库中生成视频。
在各种多模态基准测试中的实验结果,包括开放式问答、视频字幕和文本到视频生成,验证了GPT4Video的有效性和普适性。此外,GPT4Video展示了利用LLMs强大的上下文摘要和文本表达能力为视频生成详细提示的能力。

GPT4Video通过整合先进的视频理解和生成功能,显著提升了大型语言模型的性能。其在多模态基准测试中表现出色进一步强调了其卓越性能。
该项目网址:https://github.com/gpt4video/GPT4Video
论文网址:https://arxiv.org/abs/2311.16511
虚拟人聊天系统Live2D 利用ChatGPT+对口型打造你自己的AI女友
这是一个基于Unity开发的Live2D虚拟人聊天系统项目。通过Live2D技术,项目展现了一个动态的虚拟人形象,让二维图像在屏幕上以近乎三维的形式呈现,提供流畅的动画效果,增强用户交互体验。站长网2024-04-23 15:31:480001罕见!AI引发大裁员:7800人将失业
昨天,IBM宣布一个重磅消息:将暂停招聘人工智能可以胜任的岗位,将用AI取代7800个工作岗位。这意味着将有大约7800人失业。IBM首席执行官ArvindKrishna透露,暂停招聘的主要为后台岗位,比如人力资源等。这类岗位大约有26000名员工。该CEO很确定地预测,在未来5年里,这些岗位的30%工作将被人工智能等取代。目前,IBM的员工总数约26万。站长网2023-05-03 09:30:380003AI提升生产效率后,下一步是改变生产关系?
包括AIGC在内的技术成为下阶段游戏行业发展的核心动力之一已经是无需多谈的共识。我们之前提到,如果说利用AI工具提升生产效率是1.0阶段(量),那么腾讯网易作为行业头部,已经一只脚迈进了更复杂的内容多样化相关,无论是NPC的行为设定还是动作智能化的应用,这些都是质的2.0阶段,技术的更高级应用直接与内容竞争力挂钩。这是站在游戏生产角度进行的阶段划分。0000四分之一的美国教师认为K-12教育中的AI工具带来更多伤害
划重点:-25%的公立K-12教师认为在K-12教育中AI工具会带来更多伤害。-高中教师比小学和中学教师更倾向于对教育中AI工具持负面观点。-在美国青少年中,有66%听说过ChatGPT,其中19%表示使用过该工具。站长网2024-05-16 14:07:550000IDC报告:到2027年,生成式AI将取代 30% 的营销任务
划重点:-🔄预计到2027年,生成人工智能(AI)将自动执行亚太地区约30%的例行营销任务,改变营销业务格局。-🔍主要职责包括搜索引擎优化、内容和网站优化以及客户数据分析。-🚀到2028年,亚太地区的大型企业将运用生成AI自动化30%的消费者旅程行为,从营销到销售流程。-🤖预计到2026年,超过一半的消费者将使用生成AI进行产品和服务的发现、评估和购买决策。0000