轻松识别Midjourney等AI生成图片,开源GenImage
AIGC时代,人人都可以使用Midjourney、Stable Diffusion等AI产品生成高质量图片,其逼真程度肉眼难以区分真假。这种虚假照片有时会对社会产生不良影响,例如,生成公众人物不雅图片用于散播谣言;合成虚假图片用于金融欺诈,造成信任危机等。
因此,华为诺亚方舟实验室开源了百万量级的GenImage数据集,帮助企业、开发者快速构建区分AI生成的图像和真实图像的检测器和评估工具,致力于构建AIGC时代的ImageNet。
开源地址:https://github.com/GenImage-Dataset/GenImage
论文:https://arxiv.org/abs/2306.08571
项目主页:https://genimage-dataset.github.io/

GenImage主要优点
1)大量图像,包括超过一百万对 AI 生成的假图像和收集的真实图像。
2)丰富的图像内容,涵盖广泛的1000类图像。
3) 最先进的生成器,Midjourney、Stable Diffusion、ADM、GLIDE、Wukong、VQDM等,利用先进的扩散模型和 GAN 合成图像。
上述优点使得在GenImage 上训练的检测器能够经过全面的评估,并表现出对不同图像的强大适用性。
华为团队对数据集进行了全面分析,并提出了两个任务来评估类似于真实场景的检测方法。交叉生成器:检测器在一种生成器生成的数据上训练,在其他生成器生成的数据上验证。这个任务目的是考察检测器在不同生成器上的泛化能力。

退化图像识别:检测器需要对于低分辨率,模糊和压缩图像进行识别。这个任务主要考察检测器在真实条件(如互联网上传播)中面对低质量图像时的泛化问题。
数据集介绍
过去开源界也推出了一些数据集,主要有三个特点。第一数据规模小,第二都是基于GAN的,第三是局限于人脸数据。随着时间推移,数据规模慢慢地在增加,生成器也从GAN时代过渡到Diffusion时代,数据的范围也在增加。
但是一个大规模以Diffusion模型为主,涵盖各类通用图像的数据集仍然是缺失的。
基于此,华为团队提出一个对标imagenet的genimage数据集。真实的图片采用了ImageNet。
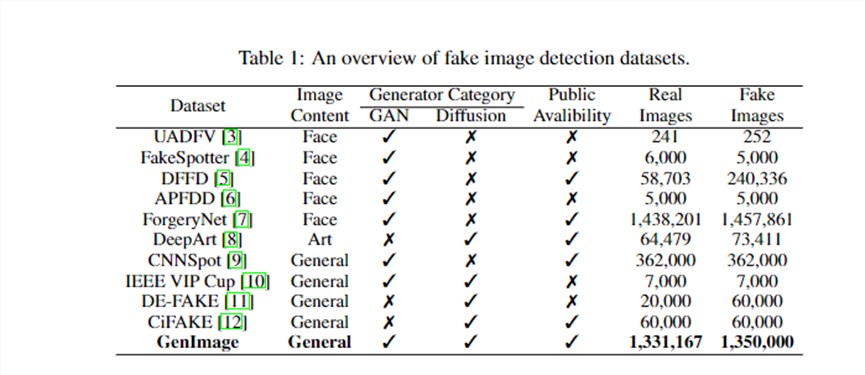
虚假的图片采用ImageNet的标签进行生成。华为团队利用了八个先进的生成器来生成,分别是Midjourney,
Stable Diffusion V1.4, Stable Diffusion V1.5, ADM, GLIDE, Wukong,VQDM和BigGAN。
这些生成器生成的图片总数基本与真实图片一致。每个生成器生成的图片数量也基本一致。每一类生成的图片数量基本一致。
实验结果
华为团队做了一些实验来考察这个数据集。他们发现在某个生成器上训练的ResNet-50模型在其他的测试准确率会明显降低。
然而在真实情况下华为团队难以得知遇到的图像的生成器是什么。因此检测器对于不同生成器生成图片的泛化能力很重要。

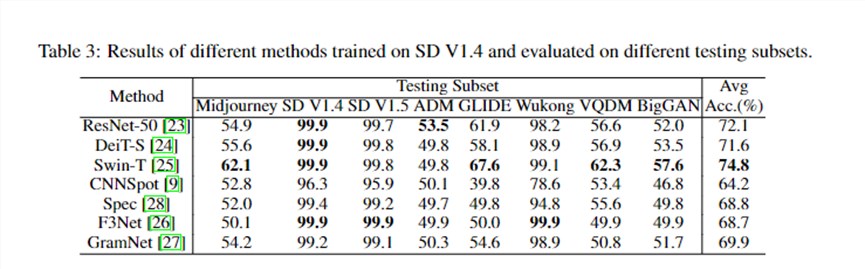
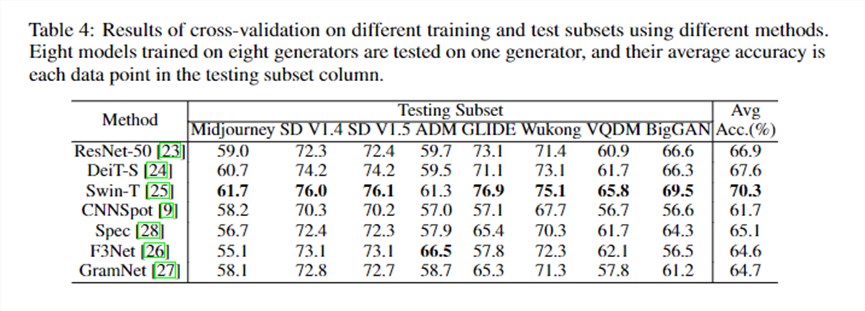
华为团队对比了现有方法在Stable Diffusion V1.4上训练,然后在各种生成器上测试的结果,也评测了各种生成器上训练,然后在各种生成器上测试的结果。
Testing Subset那一列中的每一个数据点,都是在八个生成器上训练,然后在一个生成器上测试得到的平均结果。然后华为团队将这些测试集上的结果平均,得到最右侧的平均结果。
华为团队对测试集进行退化处理,采用不同参数下的低分辨率,JPEG压缩和高斯模糊,评测结果如下

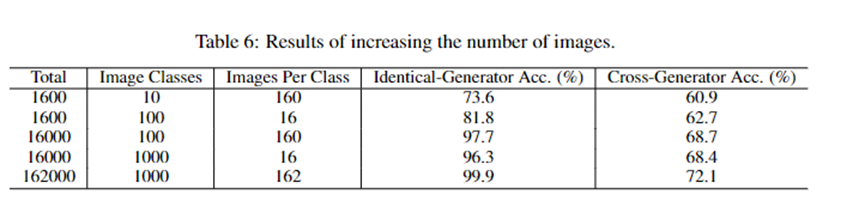
那么采集这么多数据是不是有用呢?华为团队做了相关实验,证明通过提升数据类比和每类的图片数量是可以提高性能。
针对GenImage数据集对于不同图片的泛化能力,华为团队发现他对于人脸和艺术类图片也能达到很好的效果。


未来展望
随着AI生成图片能力的不断提升,对于AI生成的图片实现有效检测的需求将会越来越迫切。本数据集致力于为真实环境下的生成图片检测提供有效训练数据。
华为团队使用ResNet-50在本数据集中训练,然后在真实推文中进行检测。如下图,ResNet-50能够有效识别真图和假图。
这个结果证明了GenIamge可以用于训练模型以判别真实世界的虚假信息。华为团队认为,该领域未来值得努力的方向是不断提升检测器在GenImage数据集上的准确率,并进而提升其在真实世界面对虚假信息的能力。
本文素材来源华为GenImage,如有侵权请联系删除
END
比特币超白银 成全球市值第八大资产
在加密货币市场近期持续走强的背景下,比特币价格于3月11日成功站上71000美元大关,并呈现出稳步上升的态势。这一强势表现使得比特币的市值也达到了新的高度,以1.41万亿美元的新市值超越了白银,成功跻身全球市值第八大资产的行列。站长网2024-03-12 11:56:040000DeepSeek回应崩了:与大规模恶意攻击及服务维护有关
快科技1月30日消息,据报道,有网友在29日晚发现给DeepSeek发送文字聊天消息时,DeepSeek回应称:不好意思,DeepSeek联网搜索服务繁忙,请关闭联网搜索功能,或者稍后再试。近期,DeepSeek的服务稳定性确实面临了挑战。早在1月26日下午,该服务就曾出现过短暂的中断,推测可能是由于新模型上线引发的流量激增所致。0000真我realme GT5 Pro官宣将于本月发布
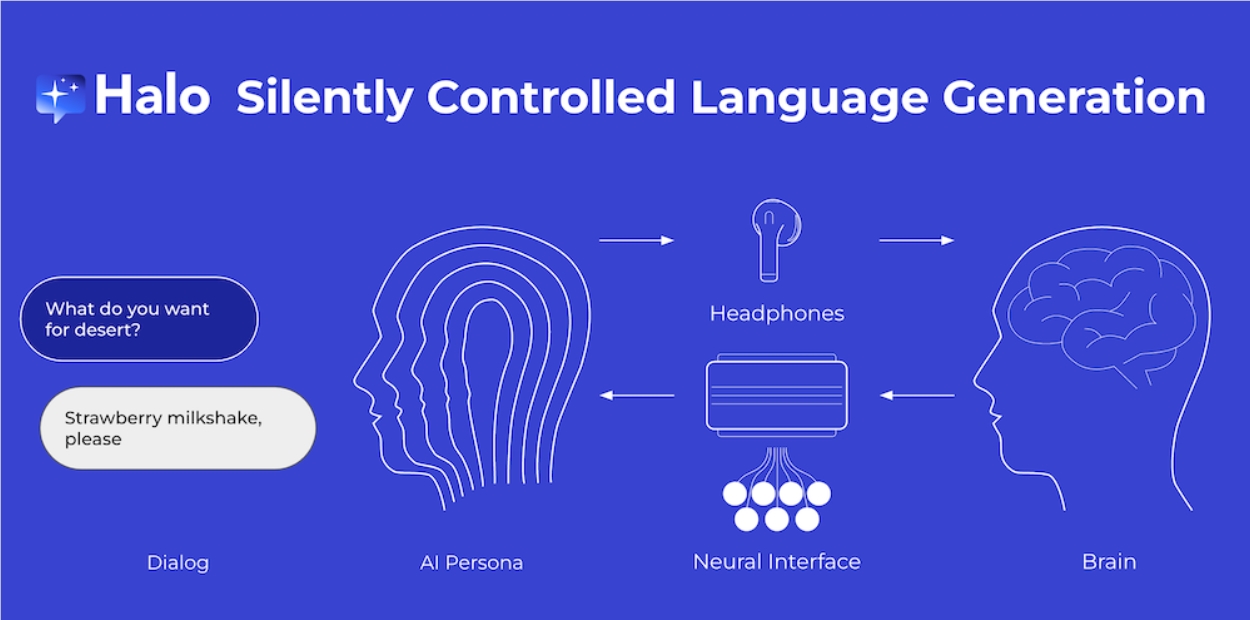
根据真我官微的消息,真我宣布其旗舰手机GT5Pro将于本月亮相,定位为“双擎旗舰”。据官方信息透露,真我GT5Pro将首批搭载高通骁龙8Gen3移动平台。据博主数码闲聊站透露,真我GT5Pro成为了行业VC散热的新天花板,其散热面积再次刷新了记录,并在机身内部实现了精密堆叠,挑战了行业极限。站长网2023-11-13 17:20:360000Unbabel推出人工智能项目“Halo” 利用电肌图实现“人机交互”
葡萄牙翻译服务初创公司Unbabel开发了一种“脑机交互”技术,名为Halo。Halo利用电肌图(EMG)系统和生成式人工智能(LLM)相结合,实现了人脑与计算机之间的交互。用户只需通过思考特定词语来触发相应的肌肉反应,然后通过AI语音与计算机进行沟通。站长网2023-08-21 09:23:140000Claude认出自画像,惊现自我意识!工程师多轮测试,实锤AI已过图灵测试?
Claude又通过「图灵测试」了?一位工程师通过多轮测试发现,Claude能够认出自画像,让网友惊掉下巴。最近,Anthropic提示工程师「ZackWitten」惊奇地发现,Claude居然能认出自己的自画像?是的,它能认出自己,但这并不是故事的全部……更惊人的还在后面!Claude3.5给三个模型画肖像首先,小哥通过一些提示,让Claude3.5Sonnet熟悉了这项任务。站长网2024-09-03 15:09:530000