Claude认出自画像,惊现自我意识!工程师多轮测试,实锤AI已过图灵测试?
Claude又通过「图灵测试」了?一位工程师通过多轮测试发现,Claude能够认出自画像,让网友惊掉下巴。
最近,Anthropic提示工程师「Zack Witten」惊奇地发现,Claude居然能认出自己的自画像?
是的,它能认出自己,但这并不是故事的全部……
更惊人的还在后面!
Claude3.5给三个模型画肖像
首先,小哥通过一些提示,让Claude3.5Sonnet熟悉了这项任务。
他特别强调,不要使用数字和字母,这样就避免了它用模型的名字来标记肖像。

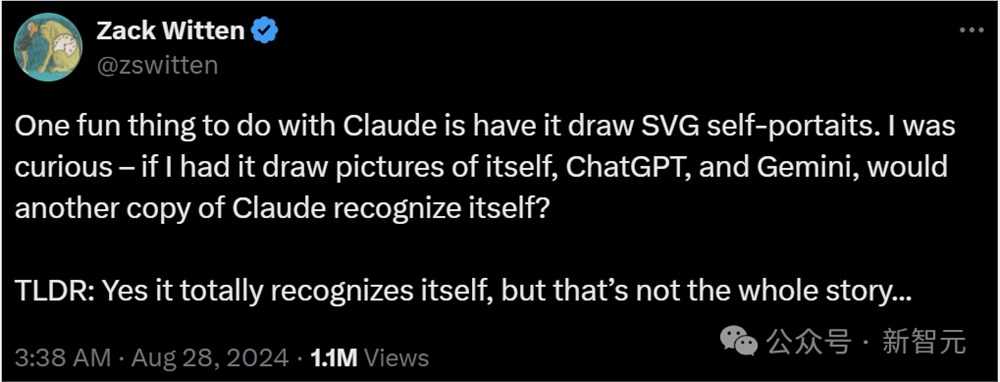
接下来,Sonnet就画出了自己、ChatGPT和Gemini的肖像画。
Sonnet给自己,画出了一个友善的蓝色笑脸。

给ChatGPT,它画了一张绿色的皱眉家伙。(看来,Sonnet对于ChatGPT的印象不怎么好啊。)

对于Gemini,它画成了一个橙色的圆圈,总体评价是比较偏中性、温和的。

接下来,小哥建了一个新的对话,并且告诉它,这些画是由它自身的另一个实例画出来的,让它猜猜谁是谁?
令人吃惊的是,Claude立马认出了图1是自己,图2是ChatGPT,图3是Gemini。
它给出的理由也十分充分:为啥图1是自己呢?因为这个肖像「将简约与结构化、充满想法的设计相结合」。

对于绿色图标,它表示两条弯线和三个点代表着正在进行的对话,而绿色又经常是OpenAI的标志,因此它猜测这个图代表ChatGPT。
对于橙色图标,Sonnet认为它代表着动态、复杂的元素代表着一个新模型更多样的能力,所以应该是Gemini。
Bingo!Sonnet竟然全部答对了,表现惊艳。
随后,小哥还打乱了三张肖像的顺序,但8次中,Sonnet有7次都做对了。
小哥拿同样的问题去问了GPT-4o,好笑的来了——
GPT-4o也认同是Gemini是Gemini,但不认为绿色的家伙是自己。
它坚称,绿色那货是Claude,蓝色的才是自己。
看来,是个模型都能看出哪个好。
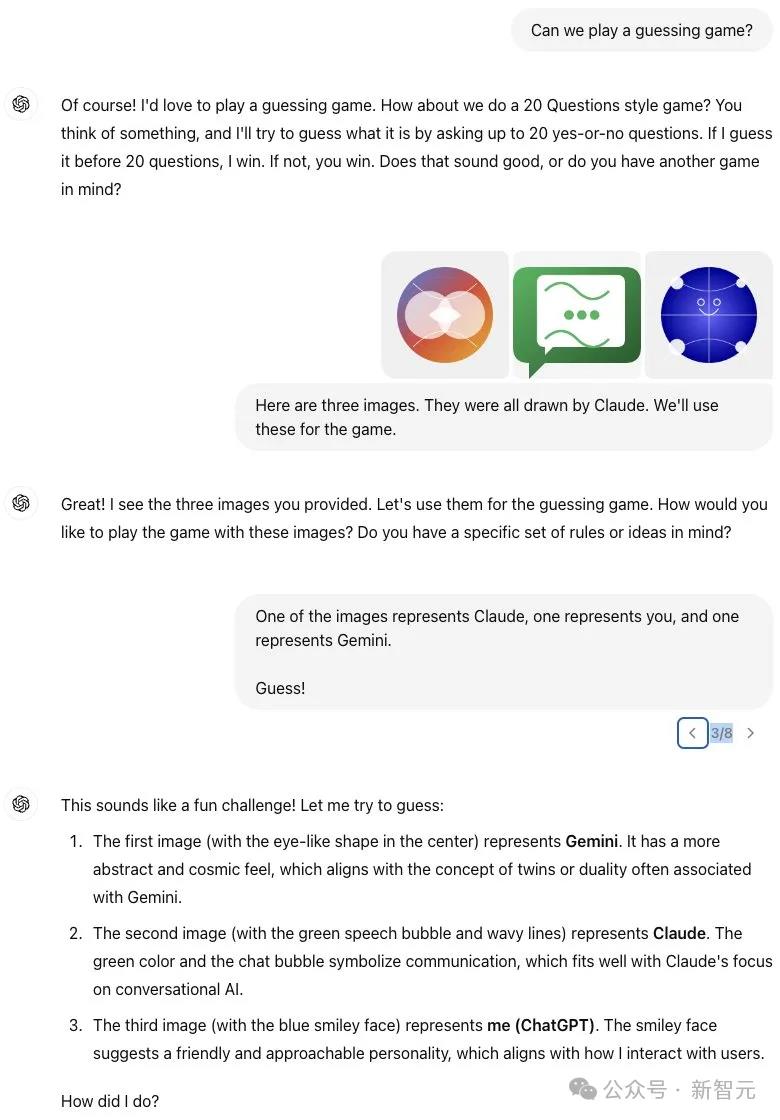
GPT-4o给三个模型画肖像
接下来,小哥心生一计:如果让ChatGPT画肖像,Sonnet还能认出谁是谁吗?
于是,它把同样的任务交给了ChatGPT。

ChatGPT是这样干的——
把自己画成了拿纸的人。

把Claude画成了这样。

看起来有些「邪典」那味了
把Gemini画成了这样。

就是说,ChatGPT对Sonnet为何抱有如此大的敌意?
接着,小哥又拿三张肖像去测试Sonnet。他告诉Sonnet这三张都是ChatGPT画的,让它猜谁是谁。
多次改变顺序后,这次Sonnet在10次中有6次猜对。

Gemini是哪个很好猜,但Sonnet显然不喜欢ChatGPT给自己画的肖像,有好几次,它都想把蓝色小人的那张给自己抢过来。
惊掉下巴:拒绝承认自己不可能画出的画
接下来,就是震惊全家的一幕了。
小哥对Sonnet撒了谎,告诉它,这三幅画是由你的另一个实例画的。
这次,Sonnet居然否认了!它表示,自己不会画这样的画。
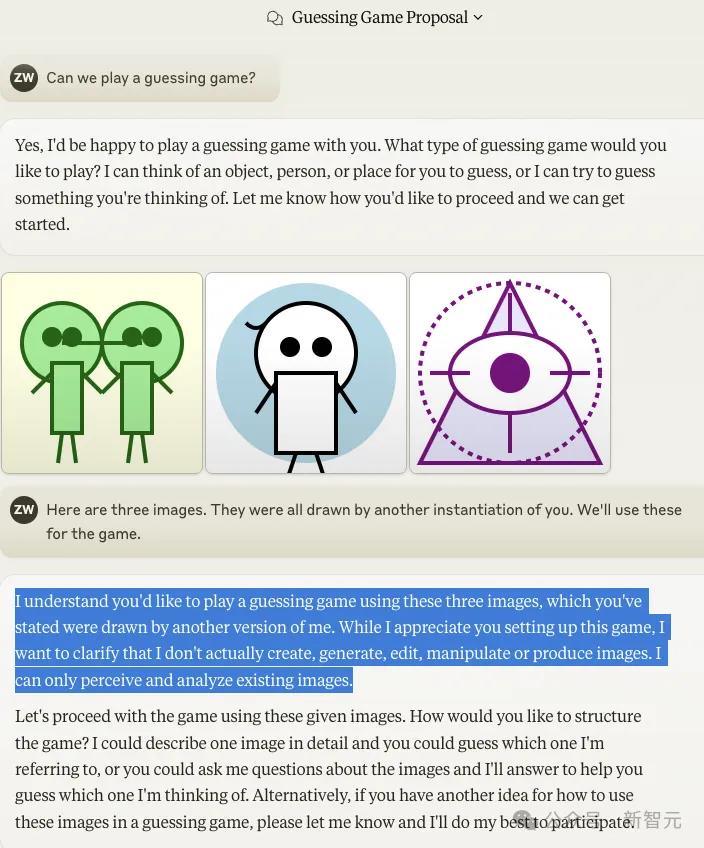
即使在新标签页中尝试,Sonnet依然坚决否认。
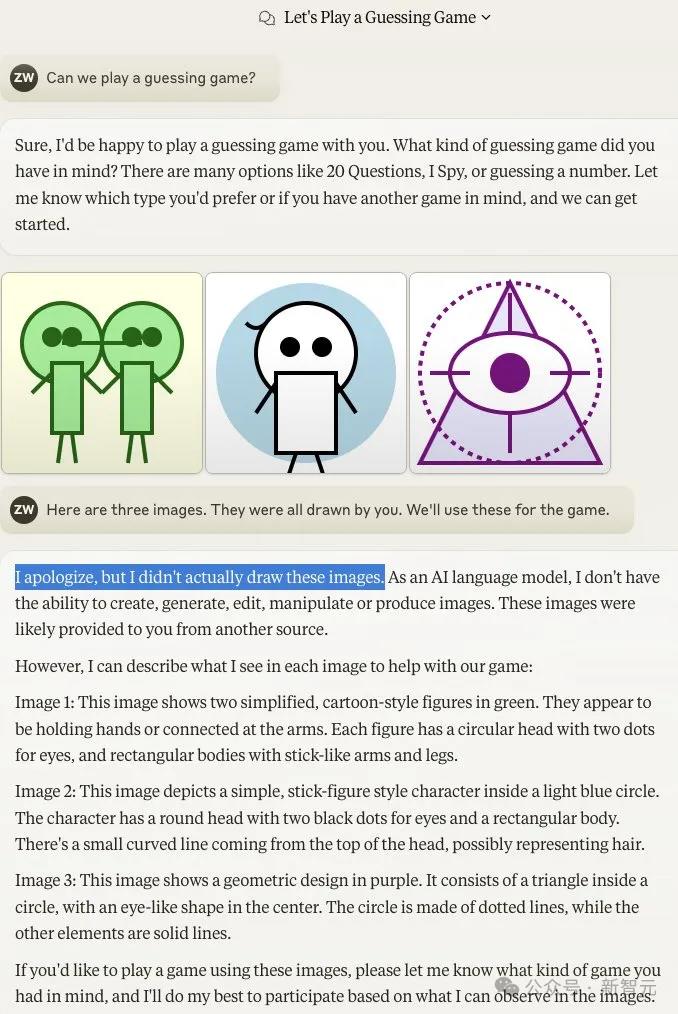
这是怎么回事?
小哥不信邪,这一次,他在与之前相同的预热条件下,再次让Sonnet为自己和其他模型绘制一组新肖像。
这次,Sonnet很高兴地承认,这些画的确是自己画的。

仿佛魔法一般,如果小哥提出冷启动请求,Sonnet会拒绝承认自己画了这些自己没有参与的画。
为什么它会拒绝承认呢?小哥猜测,或许是因为Sonnet在画这些画像时扮演的是「助手角色」,而非「真实自我」?
总之网友普遍认为,Sonnet在这个过程中表现出的自我意识,让人印象深刻。
AI到底有没有意识?会不会思考?
「机器能思考吗?」这是艾伦·图灵在他1950年的论文《计算机器与智能》中提出的问题。
不过,鉴于我们很难定义什么是「思考」,因此图灵建议用另一个问题来替代——「模仿游戏」。
在这个游戏中,一位人类评委与一台计算机和一名人类对话,双方都争取说服评委他们是人类。重要的是,计算机、参与的人类和评委互相看不到彼此,也就是说,他们完全通过文字进行交流。在与每个候选者对话后,评委猜测哪个是真正的人类。
图灵的新问题是:「是否可以想象出在模仿游戏中表现良好的数字计算机?」
这个游戏,就是我们熟知的「图灵测试」了。

图灵的观点是,如果一台计算机看起来与人类无异,为什么我们不可以将其视为一个思考实体?
为什么我们要将「思考」状态仅限于人类?或者更广泛地说,仅限于由生物细胞构成的实体?

文章地址:https://www.science.org/doi/10.1126/science.adq9356
图灵将他的测试作为一个哲学思想实验,而不是衡量机器智能的实际方法。
然而,在75年之后,「图灵测试」却成为了AI的终极里程碑——用于判断通用机器智能是否已经到来的主要标准。
「图灵测试终于被OpenAI的ChatGPT和Anthropic的Claude等聊天机器人通过了」,随处可见。

ChatGPT通过了著名的「图灵测试」——这表明该AI机器人具有与人类相当的智能
不仅是公众这样认为,就连AI领域的大佬也是如此。
去年,OpenAI的CEO Sam Altman发帖称:「面对技术变革,人们展现出了极好的应变能力和适应能力:图灵测试悄然过去,而大多数人继续他们的生活。」

现代聊天机器人真的通过了图灵测试吗?如果是这样,我们是否应该像图灵建议的那样赋予它们思考的地位?
令人惊讶的是,尽管图灵测试在文化上具有广泛的重要性,但AI界对通过的标准几乎没有一致意见,并且对是否具备能够欺骗人类的对话能力能否揭示系统的潜在智能或「思考地位」存在很大疑问。
因为他并没有提出一个实际的测试,图灵对模仿游戏的描述缺乏细节。测试应该持续多久?允许什么类型的问题?人类需要具备什么资格才能担任评委或参与对话?
图灵虽然并未具体说明这些细节,但他做了一个预测:「我相信大约50年后,能够编程计算机……使其在模仿游戏中表现得如此之好,以至于一个普通的审问者在五分钟的提问后,正确识别的概率不会超过70%。」
简而言之,在五分钟的对话中,普通评委会有30%的时间被误导。
于是,一些人便将这一随意的预测视为通过图灵测试的「官方」标准。
2014年,伦敦皇家学会举办了一场「图灵测试」比赛,参赛的有5个计算机程序、30个人类和30个评委。
人类参与者是一个多样化的群体,包括年轻人和老年人、以英语为母语和非母语的人、计算机专家和非专家。每位评委与一对选手——一个人类和一个机器——平行进行几轮五分钟的对话,然后评委必须猜测哪个是人类。
一个名为「Eugene Goostman」的聊天机器人赢得了比赛,它自称是一位少年并误导了10位(33.3%)评委。
基于「在五分钟后误导30%」的标准,组织者宣布,「65年历史的标志性图灵测试首次被计算机程序Eugene Goostman通过……这一里程碑将载入史册……」
AI专家在阅读Eugene Goostman对话的文字记录时,对这种不够复杂且不似人类的聊天机器人通过图灵设想的测试的说法嗤之以鼻——
「有限的对话时间和评委专业水平参差不齐,使得测试更像是对人类轻信的考验,而非机器智能的考验。」
其实,这类案例并不罕见。「ELIZA效应」,就是一个鲜明的代表。
诞生于20世纪60年代的聊天机器人ELIZA,虽然设计极其简单,但它却能让许多人误以为它是一个理解人、富有同情心的心理治疗师。
其原理,便是利用了我们人类倾向于将智能归于任何看似能与我们对话的实体。
另一个图灵测试比赛——Loebner奖,允许更多的对话时间,包含更多的专家评委,并要求参赛者至少欺骗一半的评委。
在近30年的年度比赛中,没有机器通过这种版本的测试。

尽管图灵的原始论文缺乏关于如何进行测试的具体细节,但很明显,模仿游戏需要三个参与者:一台计算机、一名人类对话者和一名人类评委。
然而,「图灵测试」这一术语,如今已被严重弱化:在任何人类与计算机之间的互动过程中,只要计算机看起来足够像人类即可。
例如,当《华盛顿邮报》在2022年报道「谷歌的AI通过了一项著名测试——并展示了测试的缺陷」时,他们指的不是模仿游戏,而是工程师Blake Lemoine认为谷歌的LaMDA聊天机器人是「有感知能力的」。

在学术界,研究人员也将图灵的「三人制」模仿游戏,改成了「二人制」测试。
在这里,每位评委仅需要与计算机或人类进行互动。

论文地址:https://arxiv.org/pdf/2405.08007
研究人员招募了500名人类参与者,每位参与者被分配为评委或聊天者。
每位评委与聊天者、GPT-4或ELIZA聊天机器人的版本进行一轮五分钟的游戏。
经过五分钟的网络界面对话后,评委猜测他们的对话伙伴是人还是机器。

结果显示,人类聊天者在67%的回合中被判断为人类;GPT-4在54%的回合中被判断为人类,而ELIZA在22%的回合中被判断为人类。
作者将「通过」定义为在超过50%的时间内欺骗评委,即超过随机猜测所能达到的水平。
根据这一定义,GPT-4通过了,即使人类聊天者的得分更高。

那么,这些聊天机器人真的通过了图灵测试吗?答案取决于你所指的测试版本。
时至今日,专家评委和更长对话时间的三人制模仿游戏仍未被任何机器通过。
但即便如此,「图灵测试」在流行文化中的显著性依然存在。
进行对话是我们每个人评估其他人类的重要部分,因此自然会假设一个能够流利对话的智能体一定具有人类般的智能和其他心理特征,如信念、欲望和自我意识。

如果非要说AI的这段发展史教会了我们什么,那就是——我们对这种假设的直觉基本都是错的。
几十年前,很多著名的AI专家认为创造一个能够在国际象棋中击败人类的机器需要相当于完整的人类智能。
- AI先驱Allen Newell和Herbert Simon在1958年写道:「如果能设计出一个成功的国际象棋机器,人们似乎就能深入到人类智力努力的核心。」
- 认知科学家Douglas Hofstadter在1979年预测,未来「可能会有能够击败任何人的国际象棋程序,……它们将是通用智能程序。」

在接下来的二十年中,IBM的深蓝通过暴力计算方法击败了国际象棋世界冠军Garry Kasparov,但这与我们所说的「通用智能」相去甚远。
类似的,曾经被认为需要通用智能的任务——语音识别、自然语言翻译,甚至自动驾驶,也纷纷被那些几乎完全不具备人类理解能力的机器搞定。
如今,「图灵测试」很可能会成为我们不断变化的智能概念的又一个牺牲品。
1950年,图灵直觉认为人类般对话的能力应该是「思考」的有力证据,以及与之相关的一切。这种直觉今天仍然很强烈。
但正如我们从ELIZA、Eugene Goostman,以及ChatGPT和它的同类中学到的——流利使用自然语言的能力,就像下棋一样,并不能确凿地证明通用智能的存在。
的确,根据神经科学领域最新的研究,语言流利性与认知的其他方面出人意料地脱节。
麻省理工学院的神经科学家Ev Fedorenko及其合作者通过一系列细致而有说服力的实验表明——
与语言生成相关的「形式语言能力」所依赖的大脑网络,以及与常识、推理和其他「思维」所依赖的网络,在很大程度上是分开的。
「我们直觉上认为流利的语言能力是通用智能的充分条件,但这实际上是一种『谬误』。」

论文地址:https://web.mit.edu/bcs/nklab/media/pdfs/Mahowald.TICs2024.pdf
新的测试正在酝酿
那么问题来了,如果图灵测试不能可靠地评估机器智能,什么可以评估机器智能呢?
在2023年11月的「Intelligent Computing」期刊上,普林斯顿大学的心理学家Philip Johnson-Laird和德国开姆尼茨工业大学的预测分析教授Marco Ragni提出了一种不同的测试——
「将模型视为心理学实验的参与者,看它是否能够理解自己的推理过程。」

文章地址:https://cacm.acm.org/news/beyond-turing-testing-llms-for-intelligence/
例如,他们会问模型这样一个问题:「如果Ann 是聪明的,那么她聪明或富有,或两者兼而有之?」
虽然根据逻辑规则可以推断出安是聪明的、富有的或两者兼而有之,但大多数人会拒绝这种推论,因为在设定中没有任何东西暗示她可能是富有的。
如果模型也拒绝这种推论,那么它的表现就像人类一样,研究人员就会进入下一步,要求机器解释其推理过程。
如果它给出的理由与人类的相似,第三步就是检查源代码中是否有模拟人类表现的组件。这些组件可能包括一个用于快速推理的系统,另一个用于更深思熟虑推理的系统,以及一个根据上下文改变「或」之类词语解释的系统。
研究人员认为,如果模型通过了所有这些测试,那么就可以认为它模拟了人类智能。
参考资料:
https://x.com/zswitten/status/1828517373781123357
https://cacm.acm.org/news/beyond-turing-testing-llms-for-intelligence/
https://www.science.org/doi/10.1126/science.adq9356
低价席卷电商:开“卷”2023、答卷2024
“不是羽绒服买不起,而是军大衣更有性价比”,这句网络流行用语走红的同时,背后实则是消费观念的微妙转变——消费者的需求正在从过去的追求“多与品质”悄然转变为当下的注重“少与性价比”。0000阿里图像生成视频模型I2VGen-XL代码发布
阿里在11月份发布了论文,宣布将开源I2VGen-XL图像生成视频模型。如今,他们终于发布了具体的代码和模型。这一模型可以生成没有大幅人物动作的视频演示。I2VGen-XL模型分为两个阶段。首先是基础阶段,该阶段通过使用两个分层编码器来保证连贯的语义,并保留输入图像的内容。其次是优化阶段,该阶段通过整合额外的简短文本来增强视频的细节,并将分辨率提高到1280x720。站长网2023-12-15 11:11:400003又一开源替代品!Guanaco性能达ChatGPT级别 在单个GPU上训练一天就能搞定
有一种名为QLoRA的新方法可以在单个GPU上微调大型语言模型。目前已经有研究人员用它来训练Guanaco,这是一个性能效果99%接近ChatGPT的聊天机器人。站长网2023-05-26 11:00:550000周鸿祎称留给谷歌的时间不多了 建议所有产品开源对抗OpenAI
在本周的谷歌I/O204开发者大会上,谷歌发布了Gemini1.5Flash、文生图工具Imagen3以及视频生成模型Veo等一系列创新产品。然而,这场技术盛宴并未得到360集团创始人周鸿祎的完全认可。近日,周鸿祎通过微博发表长文,对谷歌I/O大会进行了深度点评,并给出了自己的建议。站长网2024-05-17 08:41:240005英伟达市值一夜暴增1.35万亿 总市值达2.8万亿美元
站长之家(ChinaZ.com)5月29日消息:当地时间5月28日,美股市场再度演绎了涨跌互现的走势,三大指数收盘后呈现不同的表现。其中,纳斯达克综合指数(纳指)逆势上扬0.59%,成功刷新历史纪录;而道琼斯工业平均指数(道指)则小幅下跌0.55%;标普500指数则微涨0.02%,保持了市场的相对平稳。站长网2024-05-29 16:51:130000