一部iPhone实时渲染300平房间,精度达厘米级别!谷歌最新研究证明NeRF没死
【新智元导读】3D实时渲染又要进入新时代了!谷歌团队最新研究SMERF能够在手机、电脑上实时渲染大型3D场景。
3D实时渲染大型场景,一台电脑,甚至一部手机就可以完成。
从家里的客厅到主卧,储物间,厨房,卫生间各个死角,都能逼真在电脑中完成渲染,如同拍摄实物视频一般。
而且,你还可以在一台iPhone上完成复杂场景渲染。
来自谷歌、谷歌DeepMind和图宾根大学的研究人员最近提出了一种全新技术SMERF。
它可以在智能手机和笔记本电脑各种设备上实时渲染大型视图场景。
论文地址:https://arxiv.org/pdf/2312.07541.pdf
本质上讲,SMERF是一种基于NeRFs的方法,依赖于内存效率更高的MERF(Memory-Efficient Radiance Fields)。
NeRF已死?
当前,辐射场(Radiance fields)已成为一种强大且易于优化的表示形式,用于重建和重新渲染逼真的真实3D场景。
与网格和点云等显式表示相反,辐射场通常存储为神经网络并使用体积射线行进进行渲染。
在给定足够大的计算预算的情况下,神经网络可以简明地表示复杂的几何形状和依赖于视图的效果。
作为体积表示,渲染图像所需的操作数量以像素数量而不是图元(例如三角形)的数量为单位,性能最佳的模型需要数千万次网络评估。
因此,辐射场的实时方法在质量、速度或表示大小方面做出了让步,并且这种表示是否可以与高斯泼溅(Gaussian Splatting )等替代方法竞争,仍然是一个悬而未决的问题。
最新研究中,作者提出了一种可扩展的方法,从而实现比以往更高保真度的实时大空间渲染。
SMERF实时渲染,精度达厘米级别
SMERF专门为学习大型3D表示所设计,比如房屋的渲染。
谷歌等研究人员结合一种分层模型划分的方案,其中空间的不同部分和学习参数由不同的MERF表示。
这不仅增加了模型容量,而且同时限制了计算和内存要求。因为类似这样大型的3D表示是无法用经典NERF进行实时渲染。
SMERF中有K=3坐标空间分区和P=4延迟外观网络子分区的场景的坐标系
为了提升SMERF的渲染质量,研究团队还使用了一种「教师—学生」的蒸馏方法。
在这个方法中,已经训练好的高质量Zip-Nerf模型(教师),被用来训练一个新的MERF模型(学生)。
如下图,「教师监督」的整体流程。教师模型通过渲染颜色提供光度监督,并通过沿相机光线的体积权重提供几何监督。教师和学生都在同一组光线间隔上进行操作。
这种方法可以让研究人员将功能强大的Zip-Nerf模型的细节和图像质量,转移到更高效、更快的结构上。
这对智能手机和笔记本电脑等功能较弱的设备上的应用尤其有用。
实验评估
研究人员首先在Zip-NeRF引入的4大场景上评估了方法:柏林、阿拉米达、伦敦和纽约。
这些场景中的每一个都是使用180°鱼眼镜头拍摄的1,000-2,000张照片。为了与3DGS进行全面比较,研究人员将照片裁剪为110°,并使用COLMAP重新估计相机参数。
表1所示的结果表明,对于适度的空间细分K,最新方法的精度大大超过了MERF和3DGS。
随着K的增加,模型的重建精度提高,并接近其 Zip-NeRF老师的精度,在K=5时差距小于0.1PSNR和0.01SSIM。
研究人员还发现这些定量的改进低估了重建的定性改进准确性,如图5所示。
在大型场景中,SMERF方法一致地对薄几何体、高频纹理、镜面高光和实时基线达不到的远处内容进行建模。
同时,研究人员发现增加子模型分辨率自然会提高质量,特别是在高频纹理方面。
实际上,研究人员发现最新渲染方法与Zip-NeRF几乎没有区别,如图8所示。
此外,研究人员在室内和室外场景的mip-NeRF360数据集上进一步评估了最新方法。
这些场景比Zip-NeRF数据集中的场景小得多,因此无需空间细分即可获得高质量结果。如表2所示,模型的K=1版本在图像质量方面优于该基准测试中的所有先前实时模型,渲染速度与3DGS相当。
图6和图8定性地说明了这种改进,研究人员提出的方法在表示高频几何和纹理方面要好得多,同时消除了分散注意力的漂浮物和雾。
网页即可传输逼真3D空间
一旦经过训练,SMERF就可以在浏览器汇总实现完全6个自由度的导航,并在流行的智能手机和笔记本电脑上进行实时渲染。
人人都知,实时渲染的大型3D场景的能力对于各种应用非常重要,包括视频游戏、虚拟增强现实,以及专业设计和架构应用程序。
比如,谷歌沉浸式地图中,可以进行实时导航。
不过谷歌等团队提出的最新方法也有一定的局限性。虽然SMERF有出色的重建质量和存储效率,但存储成本高、加载时间长、训练工作量大。
不过,这项研究表明,与三维高斯拼接法相比,NeRFs和类似的辐射场在未来仍具有优势。
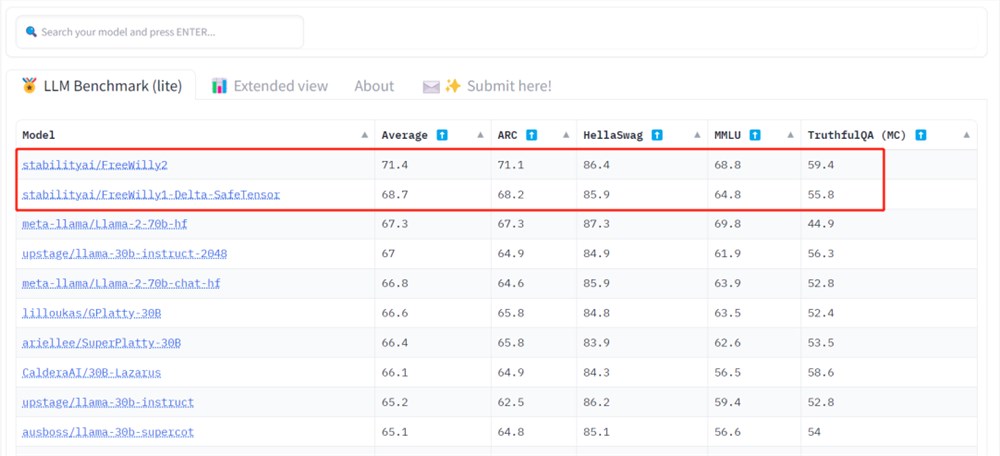
击败Llama 2,抗衡GPT-3.5,Stability AI新模型登顶开源大模型排行榜
一眨眼,开源大模型又进步了。谷歌、OpenAI真的没有护城河?「我就午休了30分,我们的领域又变了?」在看到最新的开源大模型排行榜后,一位AI领域的创业者发出了灵魂追问。排行榜链接:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard站长网2023-07-23 14:23:060000对标Gen-2!Meta发布新模型,进军文生视频赛道
随着扩散模型的飞速发展,诞生了Midjourney、DALL·E3、StableDifusion等一大批出色的文生图模型。但在文生视频领域却进步缓慢,因为文生视频多数采用逐帧生成的方式,这类自回归方法运算效率低下、成本高。即便使用先生成关键帧,再生成中间帧新方法。如何插值帧数,保证生成视频的连贯性也有很多技术难点。站长网2023-12-05 09:09:250002NVIDIA AI加速卡涨到43万元 还得等1年!韩国Google被吓跑
NVIDIAAIGPU无疑是当下的抢手货,但一方面产能严重不足,另一方面价格不断飙升,让不少客户望而却步。当然,NVIDIA并不是唯一的选择,Intel、AMD也都有类似的方案。韩国头号搜索引擎Naver最近就转投了Intel。0003好莱坞演员继续罢工 抗议AI和3D扫描技术
划重点:🌟好莱坞演员继续罢工,抗议使用AI和3D扫描技术🌟SAG-AFTRA工会提出新合同建议,遭到影视公司拒绝🌟政治立法“NOFAKESACT”引发演员对AI形象控制的希望站长网2023-10-13 15:16:040000全新视觉提示方法SoM 让GPT-4V看的更准、分的更细
要点:提出了一种新的视觉提示方法SoM,可以让GPT-4V在细粒度视觉任务上有更好的表现。SoM通过使用交互式分割模型将图像划分为不同区域,并在每个区域上添加标记,如字母数字、掩码或框。SoM可以让GPT-4V适用于多种视觉任务,如开放词汇图像分割、参考分割、短语关联和视频对象分割,并在各个数据集上取得了优于专用模型和其他开源多模态模型的性能。站长网2023-10-24 21:20:400000