20倍的压缩比例!微软发布LLMLingua:压缩长提示并加快模型推理速度
划重点:
🔍微软团队推出 LLMLingua,一种独特的粗细压缩技术,用于压缩长提示并加快模型推理速度。
🔍LLMLingua 采用动态预算控制、逐标记迭代压缩算法和指令调整方法,确保在大比例压缩下保持提示的语义完整性。
🔍实验结果表明,LLMLingua 在不同情境中都达到了最先进的性能,并能实现高达20倍的压缩比例。
微软的研究团队开发了一种名为 LLMLingua 的独特粗细压缩技术,旨在解决大型语言模型(LLMs)中长提示带来的问题。LLMs 以其强大的泛化和推理能力显著推动了人工智能(AI)领域的发展,展示了自然语言处理(NLP)、自然语言生成(NLG)、计算机视觉等方面的能力。然而,最新的发展,如上下文学习(ICL)和思维链(CoT)提示,导致了部署更长提示的需求,有时甚至超过数万个标记。这在模型推理方面带来了成本效益和计算效率的问题。
为了克服这些挑战,微软团队引入了 LLMLingua,一种独特的粗细压缩技术。LLMLingua 的主要目标是减少处理长提示的费用,并加快模型推理速度。为此,LLMLingua 采用了以下几种关键策略:
1. 预算控制器:设计了一个动态预算控制器,用于在原始提示的各个部分之间分配压缩比例。这确保了即使在大比例压缩下,提示的语义完整性也得到保留。
2. 标记级迭代压缩算法:LLMLingua 集成了一种标记级迭代压缩算法,通过捕捉压缩元素之间的相互依赖关系,实现更复杂的压缩,并保持关键提示信息。
3. 指令调整方法:团队提出了一种基于指令调整的方法,用于解决语言模型之间的分布不一致问题。调整语言模型的分布可以提高用于快速压缩的小型语言模型与预期 LLM 之间的兼容性。
团队使用来自不同情境的四个数据集进行了分析和实验,以验证 LLMLingua 的实用性。这些数据集包括推理的 GSM8K 和 BBH,对话的 ShareGPT 以及摘要的 Arxiv-March23。结果显示,该方法在每种情境下都实现了最先进的性能。结果甚至表明,LLMLingua 在牺牲很少性能的情况下允许高达20倍的压缩。
实验中使用的小型语言模型是 LLaMA-7B,闭合的 LLM 是 GPT-3.5-Turbo-0301。LLMLingua 在最大压缩比例为20倍时优于先前的压缩技术,保留了推理、摘要和话语技能,展现了弹性、经济性、高效性和可恢复性。
LLMLingua 的有效性已经在一系列闭合 LLMs 和小型语言模型中得到观察。在使用 GPT-2-small 时,LLMLingua 显示出与较大模型相当的性能结果。它还在强大的 LLMs 上表现出色,超出了预期的快速结果。
LLMLingua 的可恢复性是一个值得注意的方面,当用于恢复压缩提示时,GPT-4可以有效地从完整的九步 CoT 提示中检索重要的推理信息,保持原始提示的意义和相似性。这个功能确保了可恢复性,即使在翻译后也能保留关键信息,增加了 LLMLingua 的整体亮点。
,LLMLingua 为 LLM 应用程序中长提示所带来的困难提供了全面的解决方案。该方法表现出色,并提供了一种改善 LLM 应用程序的效果和可负担性的有用方式。
项目网址:https://github.com/microsoft/LLMLingua
论文网址:https://arxiv.org/pdf/2310.05736.pdf
博客网址:https://www.microsoft.com/en-us/research/blog/llmlingua-innovating-llm-efficiency-with-prompt-compression/
张雪峰发文称已安排上Mate 60:信赖华为质量 对iPhone不感兴趣
网红张雪峰又上热搜了,主要还不是自己前脚刚换Mate50,后面立刻华为就推出了Mate60,这也引来不少网友的调侃。随后,华为技术有限公司官微菊厂阿华”在评论中表示,将送给张雪峰一台新机。所以,这才有了张雪峰新动态,他的Mate60手机已经安排,正在等待中。对于张雪峰来说,他对国产手机更加执着,或者是对华为更信赖。站长网2023-09-02 11:37:030000蚂蚁集团CodeFuse-VLM开源 支持多模态多任务预训练/微调
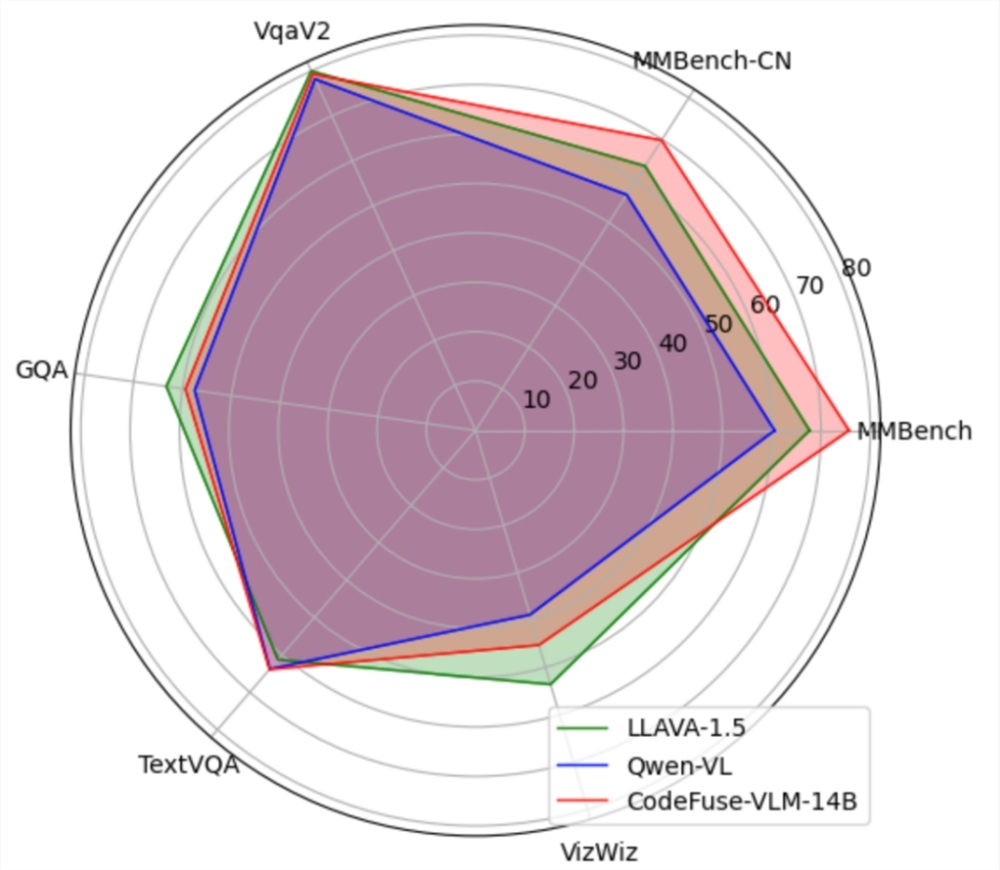
CodeFuse-VLM是一个支持多种视觉模型和语言大模型的框架,用户可以根据自己的需求搭配不同的VisionEncoder和LLM。CodeFuse-VLM-14B模型在多个通用和代码任务上的性能超过LLAVA-1.5和Qwen-VL。该框架还支持高效的PEFT微调,能有效提升微调训练速度并降低对资源的需求。站长网2024-02-05 16:39:370000小米云服务新春活动公布:200GB连续包年 138 元
站长之家(ChinaZ.com)1月15日消息:小米云服务近日宣布,新春活动正式开启,为期14天,即从1月15日至1月28日。在这次活动中,黄金50GB连续包年的价格为39元,白金200GB连续包年价格为138元,而钻石2TB连续包年价格为448元。此次活动仅限中国大陆的小米云服务用户参加,购买连续包年会员方案可以享受5.5折的优惠。站长网2024-01-15 16:04:480000英伟达发布430亿参数大模型ChipNeMo
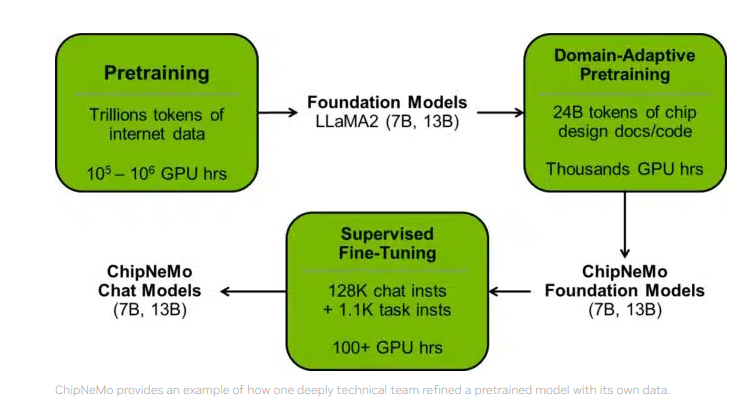
要点:1.英伟达发布了拥有430亿参数的大语言模型ChipNeMo,专注于辅助芯片设计,提高工作效率。2.ChipNeMo支持问答、EDA脚本生成、Bug总结和分析等任务,帮助芯片设计师完成工作。3.ChipNeMo的研发采用了领域自适应技术,提升了性能并减小模型大小。站长网2023-11-01 09:21:040000麦当劳决定炒掉AI员工,用AI点餐这件事不靠谱
从游戏公司的画师到电销公司的客服,被AI影响到工作的人在2023年可谓是一茬接着一茬,甚至“第一批因AI而失业的人出现”更是成为了去年部分媒体最有兴趣的话题。事实上,AI技术的快速发展确实已经开始对人类社会造成影响,但过高估计当下AI的能力也大可不必,因为已经有第一批AI员工开始下岗了。日前,麦当劳方面宣布AI点餐员项目即将终止,这一套与IBM合作的自动点餐系统在测试了3年之后以失败告终。站长网2024-07-17 13:32:360003