新型3D生成方法DMV3D:使用基于Transformer的3D大型重建模型进行去噪
**划重点:**
1. 💡 DMV3D是一种单阶段的、类别不可知的扩散模型,能够通过直接模型推理从文本或单一图像输入条件生成3D神经辐射场(NeRFs),显著缩短了创建3D对象所需的时间。
2. 💡 DMV3D集成了3D NeRF重建和渲染到其去噪器中,创建了一个在没有直接3D监督的情况下训练的2D多视图图像扩散模型,消除了为潜在空间扩散单独训练3D NeRF编码器的需要。
3. 💡 基于大型Transformer模型,研究人员通过近期的3D大型重建模型(LRM)构建了一个新颖的联合重建和去噪模型,能够处理扩散过程中的各种噪声水平。
近期,Adobe研究人员与斯坦福大学团队联合提出了一种名为DMV3D的全新3D生成方法。该方法旨在解决增强现实(AR)、虚拟现实(VR)、机器人技术和游戏等领域中3D资产创建的共同挑战。尽管3D扩散模型在简化复杂的3D资产创建过程方面变得越来越受欢迎,但它们需要访问用于训练的地面真实3D模型或点云,这对于真实图像而言是一项挑战。

现有的解决方案虽然可以解决这一挑战,但通常需要大量手动工作和优化过程。因此,Adobe研究人员与斯坦福大学团队一直致力于使3D生成过程更快、更真实和更通用。他们近期发布的论文介绍了一种新的方法,即DMV3D,这是一种单阶段的、类别不可知的扩散模型。
DMV3D的关键贡献包括使用多视图2D图像扩散模型进行3D生成的开创性单阶段扩散框架。同时,引入了大型重建模型(LRM),这是一种多视图去噪器,可以从嘈杂的多视图图像中重建无噪音的三平面NeRFs。该模型提供了一个通用的概率方法,用于高质量的文本到3D生成和单图像重建,实现了快速的直接模型推理,在单个A100GPU上仅需约30秒。
DMV3D将3D NeRF重建和渲染集成到其去噪器中,创建了一个在没有直接3D监督的情况下训练的2D多视图图像扩散模型。这消除了为潜在空间扩散单独训练3D NeRF编码器的需要,并简化了每个资产的优化过程。研究人员巧妙地使用了围绕物体的四个多视图图像的稀疏集合,有效地描述了一个3D对象,而没有明显的自遮挡问题。
通过利用大型Transformer模型,研究人员解决了稀疏视图3D重建的挑战性任务。基于最近的3D大型重建模型(LRM),他们引入了一种新颖的联合重建和去噪模型,能够处理扩散过程中的各种噪声水平。在大规模合成渲染和真实捕获的数据集上进行训练,DMV3D在单个A100GPU上展示了在约30秒内生成单阶段3D的能力。它在单图像3D重建方面取得了最新的成果。

该研究为通过统一3D重建和生成的2D和3D生成模型的领域之间的鸿沟,以解决3D视觉和图形领域中的各种挑战,提供了新的视角和可能性。
项目网址:https://justimyhxu.github.io/projects/dmv3d/
论文网址:https://arxiv.org/abs/2311.09217
美国参议院公布AI监管路线图 呼吁每年投320亿美元
划重点:🔸参议院AI工作组公布了一份AI监管路线图,呼吁每年至少投入320亿美元用于非国防AI创新。🔸路线图重点指导参议院各委员会在AI立法方面的工作重点,包括AI人才培训、处理AI生成内容、保护隐私信息和版权内容、减少AI的能源消耗等。🔸路线图没有提出具体的立法法案,而是为参议院委员会在AI监管方面提供了指导。站长网2024-05-16 11:09:190000SK 海力士发布全球首款 321 层 NAND 样品 助力生成式人工智能发展
站长之家(ChinaZ.com)8月9日消息:SK海力士今天发布了行业中层数最高的NAND技术,采用321层设计,可达到1TbTLC封装。图片来自skhynix该公司在8月8日至10日于圣克拉拉举办的FlashMemorySummit(FMS)2023上介绍了其321层1TbTLC4DNANDFlash的开发进展。站长网2023-08-09 16:46:510000AI模特商拍工具“摹小仙” 支持一键试装
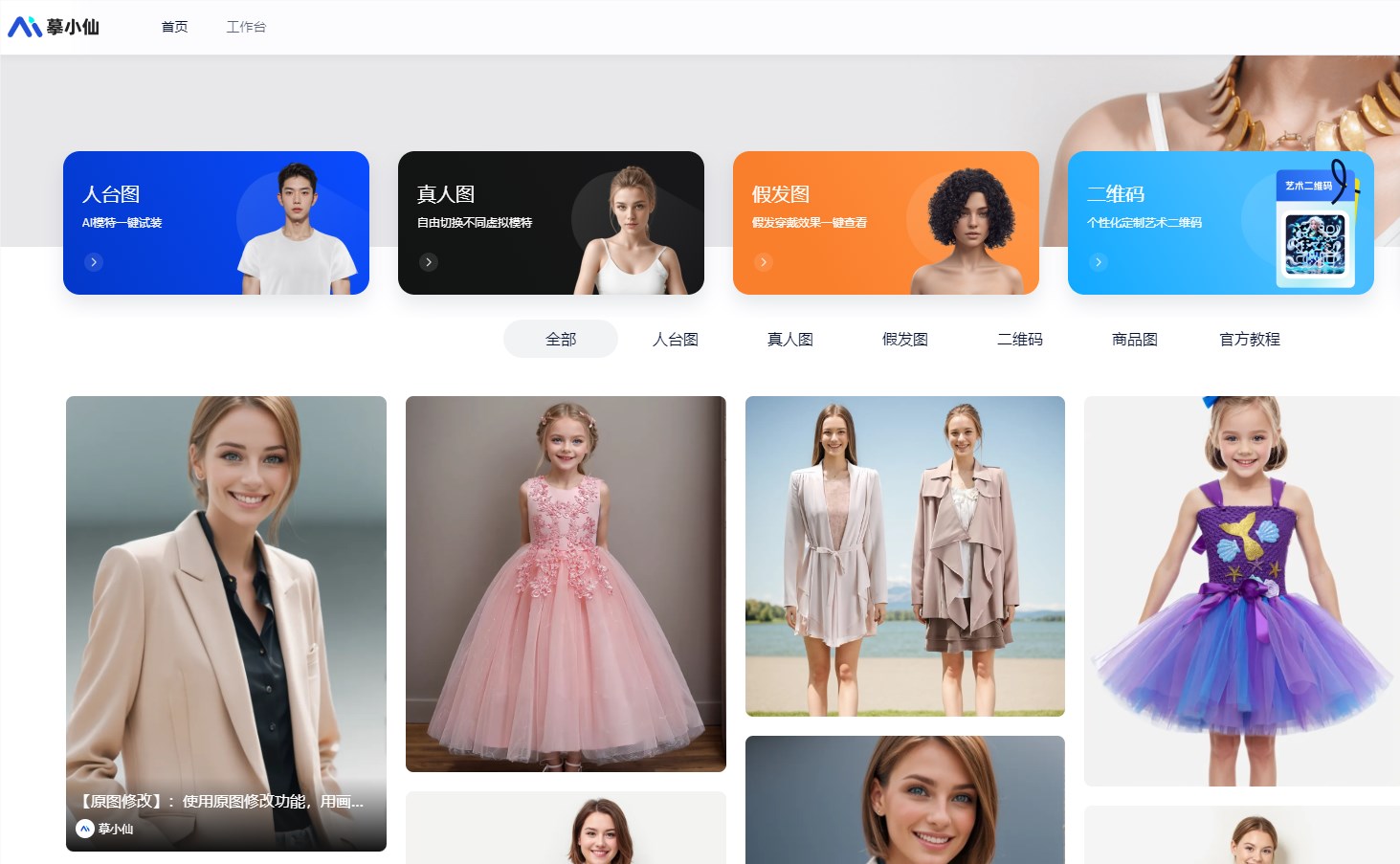
“摹小仙”是一款利用人工智能技术的AI模特商拍工具,能够在线生成AI模特换装图,帮助电商平台降低商品拍摄成本。用户可以通过“摹小仙”在线生成的AI模特进行试衣换装,而无需下载任何软件。此外,“摹小仙”还提供多种功能,包括生成人台图、真人图、假发图、二维码和商品图,以满足不同场景的需求。体验地址:https://www.moxiaoxian.art/站长网2023-11-14 17:11:360000看完Claude 3创作的OpenAI连续剧,我都替马斯克委屈
有的企业官司缠身,有的企业“弯道超车”。3月4日,OpenAI最强竞争对手Anthropic发布Claude3,一夜之间成为“全球最强大模型”。有网友当即就按耐不住了,公开叫嚣OpenAI,“GPT-5呢?”、“Q*在哪里”、“Sora什么时候发布”,压力直接给到SamAltman。Sam你可以发布GPT5了站长网2024-03-07 15:18:480002苹果发布 iPhone 15 Pro/Max、iPhone 15/Plus 和 Apple Watch Series 9 /Ultra 2 四款全新设备:常规性能提升 售价与上代持平
今天,苹果公司发布了最新的旗舰智能手机系列,即iPhone15Pro和iPhone15ProMax和iPhone15和iPhone15Plus,以及新款AppleWatch系列AppleWatchSeries9和AppleWatchUltra2。AppleWatchSeries9站长网2023-09-13 09:25:310000