任意文本、视觉、音频混合生成,多模态有了强大的基础引擎CoDi-2
研究者表示,CoDi-2标志着在开发全面的多模态基础模型领域取得了重大突破。
今年5月,北卡罗来纳大学教堂山分校、微软提出一种可组合扩散(Composable Diffusion,简称CoDi)模型,让一种模型统一多种模态成为可能。CoDi 不仅支持从单模态到单模态的生成,还能接收多个条件输入以及多模态联合生成。
近日,UC 伯克利、微软 Azure AI、Zoom、北卡罗来纳大学教堂山分校等多个机构的研究者将 CoDi 升级到了 CoDi-2。
论文地址:https://arxiv.org/pdf/2311.18775.pdf
项目地址:https://codi-2.github.io/
论文一作 Zineng Tang 表示,「CoDi-2遵循复杂的多模态交错上下文指令,以零样本或少样本交互的方式生成任何模态(文本、视觉和音频)。」
图源:https://twitter.com/ZinengTang/status/1730658941414371820
可以说,作为一种多功能、交互式的多模态大语言模型(MLLM),CoDi-2能够以 any-to-any 输入-输出模态范式进行上下文学习、推理、聊天、编辑等任务。通过对齐编码与生成时的模态与语言,CoDi-2使 LLM 不仅可以理解复杂的模态交错指令和上下文示例, 还能在连续的特征空间内自回归地生成合理和连贯的多模态输出。
而为了训练 CoDi-2,研究者构建了一个大规模生成数据集,包含了跨文本、视觉和音频的上下文多模态指令。CoDi-2展示了一系列多模态生成的零样本能力,比如上下文学习、推理以及通过多轮交互对话实现的 any-to-any 模态生成组合。其中在主题驱动图像生成、视觉转换和音频编辑等任务上超越了以往领域特定的模型。
人类与 CoDi-2的多轮对话为图像编辑提供了上下文多模态指令。
模型架构
CoDi-2在设计时旨在处理上下文中的文本、图像和音频等多模态输入,利用特定指令促进上下文学习并生成相应的文本、图像和音频输出。CoDi-2模型架构图如下所示。
将多模态大语言模型作为基础引擎
这种 any-to-any 基础模型可以消化交错式模态输入,理解和推理复杂指令(如多轮对话、上下文示例),并与多模态扩散器交互,实现这一切的前提是需要一个强大的基础引擎。研究者提出将 MLLM 作为这个引擎,它的构建需要为仅文本的 LLM 提供多模态感知。
利用对齐的多模态编码器映射,研究者可以无缝地使 LLM 感知到模态交错的输入序列。具体地,在处理多模态输入序列时,他们首先使用多模态编码器将多模态数据映射到特征序列,然后特殊 token 被添加到特征序列的前后,比如「⟨audio⟩ [audio feature sequence] ⟨/audio⟩」。
基于 MLLM 的多模态生成
研究者提出将扩散模型(DM)集成到 MLLM 中,从而生成多模态输出,这里遵循细致入微的多模态交错指令和提示。扩散模型的训练目标如下所示:
接着他们提出训练 MLLM 以生成条件式特征 c = C_y (y),该特征被馈入到扩散模型中以合成目标输出 x。这样一来,扩散模型的生成损失被用来训练 MLLM。
任务类型
本文提出的模型在以下示例任务类型中显示出强大的能力,它提供了一种独特的方法来提示模型生成或转换上下文中的多模态内容,包括本文、图像、音频、视频及其组合。
1. 零样本提示。零样本提示任务要求模型在没有任何先前示例的情况下进行推理并生成新内容。
2. 一次/少量样本提示。一次或少量样本提示为模型提供了一个或几个示例,以便在执行类似任务之前从中学习。这种方法在以下任务中很明显:模型将学习到的概念从一个图像应用到另一个图像,或者通过理解所提供示例中描述的风格来创建一个新的艺术品。
(1)范例学习在要求模型将此学习应用于新实例之前,向模型显式显示期望输出的示例。
(2)概念学习涉及模型从这些给定示例的共享概念/属性中学习,例如艺术风格或模式,然后创建展示类似概念/属性的新内容。
(3)主题驱动的学习侧重于根据一组提供的图像生成新的内容。
实验及结果
模型设置
本文模型的实现基于 Llama2,特别是 Llama-2-7b-chat-hf。研究者使用 ImageBind ,它具有对齐的图像、视频、音频、文本、深度、thermal 和 IMU 模式编码器。研究者使用 ImageBind 对图像和音频特征进行编码,并通过多层感知器(MLP)将其投射到 LLM(Llama-2-7b-chat-hf)的输入维度。MLP 由线性映射、激活、归一化和另一个线性映射组成。当 LLM 生成图像或音频特征时,他们通过另一个 MLP 将其投射回 ImageBind 特征维度。本文图像扩散模型基于 StableDiffusion2.1(stabilityai/stable-diffusion-2-1-unclip)、AudioLDM2和 zeroscope v2。
对于需要更高保真原始输入的图像或音频,研究者还将原始图像或音频输入到扩散模型中,同时通过连接扩散噪声生成特征。这种方法在保留输入内容的最大感知特征方面尤为有效,添加新内容或改变风格等指令编辑也是如此。
图像生成评估
下图展示了 Dreambench 上主题驱动图像生成的评估结果和 MSCOCO 上的 FID 分数。本文方法实现了极具竞争力的零样本性能,显示了其对未知新任务的泛化能力。
音频生成评估
表5展示了音频处理任务的评估结果,即添加、删除和替换音轨中的元素。从表中可以明显看出,与之前的方法相比,本文方法表现出了卓越的性能。值得注意的是,在所有三个编辑任务中,它在所有指标 — 对数谱距离(LSD)、Kullback-Leibler(KL)发散和 Fréchet Dis- tance(FD)上都取得了最低得分。
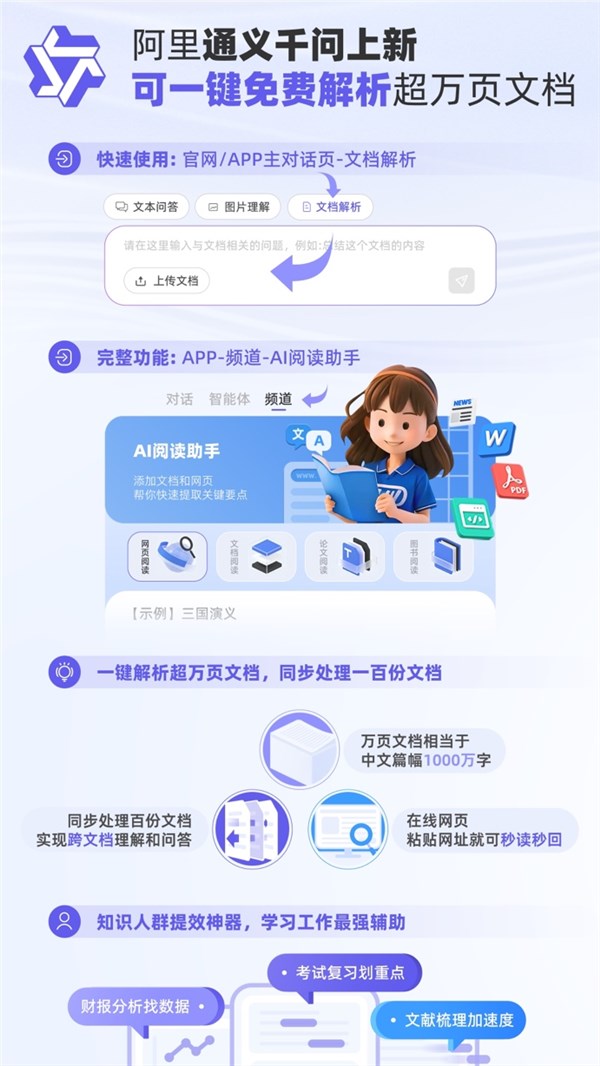
阿里通义千问推出AI阅读助手功能 可一键免费解析超万页文档
阿里通义千问震撼推出全新AI阅读助手功能,不仅完全免费,更能轻松解析网页、文档、论文、图书,一举突破大模型在长文档处理领域的局限。这一功能在通义千问官网和APP同步上线,用户只需点击“文档”按钮,即可上传本地文档并向大模型提问。通义千问支持多种格式,包括PDF、Word、HTML、Markdown、EPUB、Mobi、Excel和Txt等,为用户提供了极大的便利性。站长网2024-03-14 15:21:020000iPhone16Pro显示屏边框或变窄:将采用新显示技术
随着iPhone16系列机型的发布临近,韩国媒体TheElec最新报道显示,苹果已正式批准三星Display和LGDisplay为其旗舰机型iPhone16Pro量产OLED屏幕。此消息不仅为即将发布的iPhone16Pro机型的屏幕量产铺平了道路,也标志着苹果在供应链策略上的进一步多元化。站长网2024-05-29 17:08:400000申通快递对12省份快件提价 以应对恶劣天气
站长之家(ChinaZ.com)2月1日消息:申通快递近日发布通知,为保障末端派送服务质量和消费者体验,结合当前天气情况,将对发往黑龙江、吉林、江西、湖南、湖北、安徽、四川、河南、山东、山西、内蒙古和辽宁等省份的快件进行价格调整。站长网2024-02-01 08:30:530000景德镇调查:抖音头部涌入,视频号越来越挤,有人亏钱也要投流
2014年春天,一只明成化年间的斗彩鸡缸杯在香港苏富比拍出2.8亿港元天价,刷新当时中国瓷器拍卖记录。斗彩鸡缸杯娇巧玲珑,胎薄釉润,背后是景德镇匠人的高超技艺。如今十年过去,这场拍卖的美谈仍在流传。“只有景德镇,才能卖出这么贵的东西。”不久前,一位陶瓷从业者告诉亿邦动力,哪怕是一模一样的东西,大家也更认景德镇,这使其均价比其他产地高出30%左右。0000中兴:今年将发布自研AI大模型以及首款AI旗舰终端
中兴手机宣布,将在今年发布自研AI大模型以及中兴首款AI旗舰终端。此次中兴终端的AI大模型应用架构全面而深入,涵盖了智能场景、交互技术、业务应用大模型以及大模型基础设施等多个方面。在智能场景方面,中兴的AI大模型将深入应用于商务出行、影音娱乐、家庭教育、运动健康以及智能驾驶等多个领域,为用户提供更加智能化的生活体验。站长网2024-02-26 09:39:060000