中科大联合封神榜团队发布中文医疗领域大模型ChiMed-GPT
站长网2023-11-20 16:46:150阅
中科大和 IDEA 研究院封神榜团队合作开发了一款名为 ChiMed-GPT 的中文医疗领域大语言模型(LLM)。该模型基于封神榜团队的 Ziya2-13B 模型构建,拥有130亿个参数,并通过全方位的预训练、监督微调和人类反馈强化学习来满足医疗文本处理的需求。
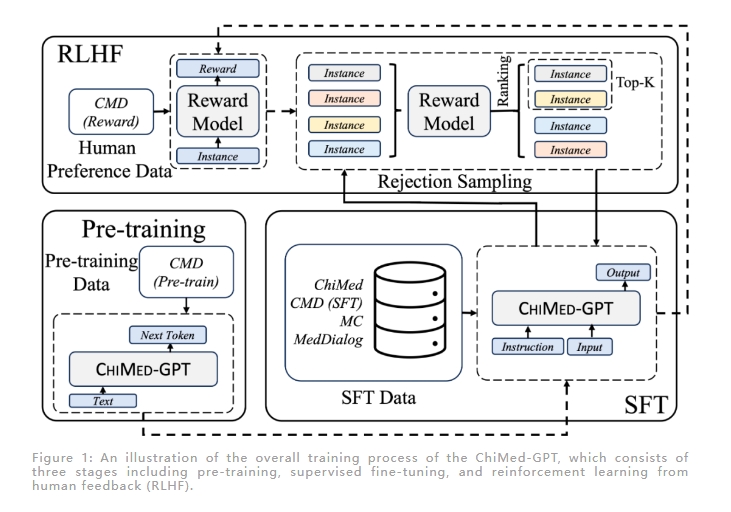
ChiMed-GPT 的训练过程包括三个阶段:预训练、监督式微调和人类反馈强化学习。在预训练阶段,模型使用了2.14亿字的医学百科文档和教科书文章进行继续训练,以扩展医疗领域的知识。在监督式微调阶段,模型利用问答和医患对话数据来提升在真实医疗环境中理解人类指令的能力。在人类反馈强化学习阶段,模型使用拒绝采样技术进行训练,通过奖励模型训练和拒绝采样微调来进一步提高模型性能。
在医疗信息抽取、问答和对话生成等任务上,ChiMed-GPT 的性能优于其他同规模的开源模型,并且在多个指标上超越了 GPT-3.5。在医疗信息抽取任务中,ChiMed-GPT 的性能优于通用和医学领域的开源模型。在问答任务和对话生成任务中,ChiMed-GPT 在多个评估指标上表现出色,展示了其在实际应用中的广泛适用性。
据悉,ChiMed-GPT 的研发对于提升医疗智能的重要性具有重要意义。该模型不仅能够有效处理医疗文本数据,还能生成适合回答患者咨询的内容。
Github:
https://github.com/synlp/ChiMed-GPT
HuggingFace:
https://huggingface.co/SYNLP/ChiMed-GPT-1.0
0000
评论列表
共(0)条相关推荐
抖音打击违规售卖“网红培训课程” 处置典型违规账号31个
抖音发布《关于打击违规售卖“网红培训课程”的公告》称,近期,平台在日常巡查中发现,有部分账号以“不需要才艺颜值,轻轻松松月入过万”“普通人想成为网络主播做网红找我,月入过万的秘诀在此”“直播其实很简单,和别人聊聊天月入轻松过万”等噱头吸引用户关注,并借此向用户售卖虚假、错误的教学内容,甚至有可能对用户实施诈骗行为,从中不当谋取利益。站长网2023-09-06 17:35:570000Alphabet 利润超出预期 将在谷歌改进后的 AI 搜索中引入广告
站长之家(ChinaZ.com)7月26日消息:Alphabet在周二公布的第二季度利润超出华尔街预期,谷歌母公司宣布其长期担任首席财务官的RuthPorat将担任新职务,而公司将寻找新的财务主管。站长网2023-07-26 11:33:160000小米13 Ultra视场解析力优于iPhone 14 Pro Max
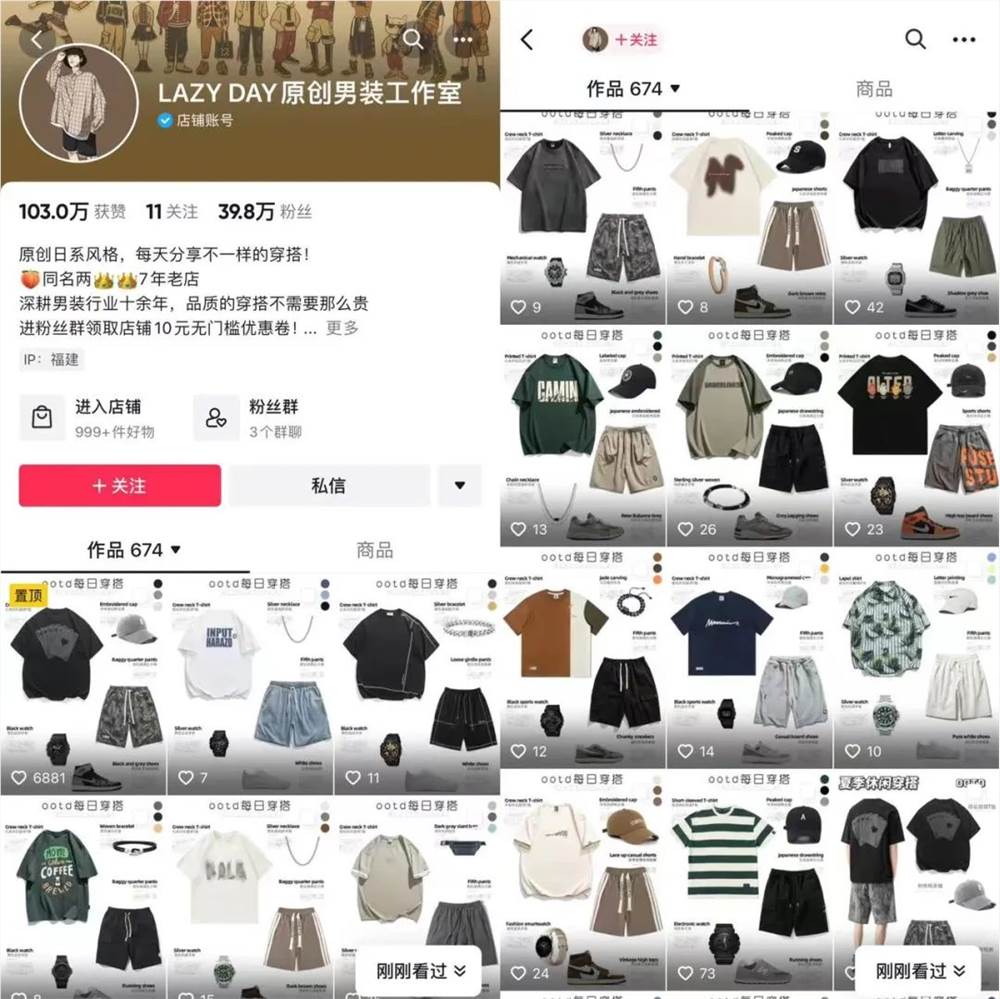
就在刚刚,小米官方对小米13Ultra所配备的徕卡Summicron镜头进行了详细的介绍。小米表示,徕卡Summicron镜头充分利用非球面镜结构,释放光路设计的灵活度,使得四颗镜头都具备惊人的小体积。在设计阶段,每一个非球镜面的形状都由“超高阶偶次多项式”来计算,镜片的拟合精度达到了纳米级别。这样精密的设计加工模具的刀头精度达到了20纳米,镜头的良率甚至不足10%。站长网2023-04-12 16:56:370000不拍视频不直播,揭秘抖音图文男装玩法
各位村民好,我是村长。都说男性消费欲望低,可支配收入少,给男生卖产品挺难。虽然这是一定的事实,但并不代表男性真的没有消费需求、没有购买力。只是相对女性而言,男性的消费需求毕竟单一和低频而已。今天我要和大家分享一个在抖音卖男装的案例,不拍视频、不做直播,也能把产品卖出去。01抖音图文男装这个账号是在抖音上卖男装的,内容形式不是视频和直播,而是图文。站长网2023-07-20 13:42:000000Android 16首度曝光:发布时间提前至明年Q2
谷歌已确认其即将推出的Android16版本将于2025年上半年发布,具体时间定于第二季度。此消息是在Android15兼容性定义文档中发现的"25Q2"字样后透露的。该数字表示Android16将在2025年第二季度发布,而不是传统的下半年时间表。0000