微软用GPT-4V解读长视频 MM-Vid能看懂电影还能讲给盲人听
站长网2023-11-15 19:25:570阅
要点:
微软Azure AI推出的MM-Vid整合了GPT-4V与专用工具,能解读长达一小时的视频并为视障人士提供解说。
MM-Vid通过将长视频分解成连贯叙述,结合GPT-4V的多模态理解能力,实现对真实世界视频的全面理解。
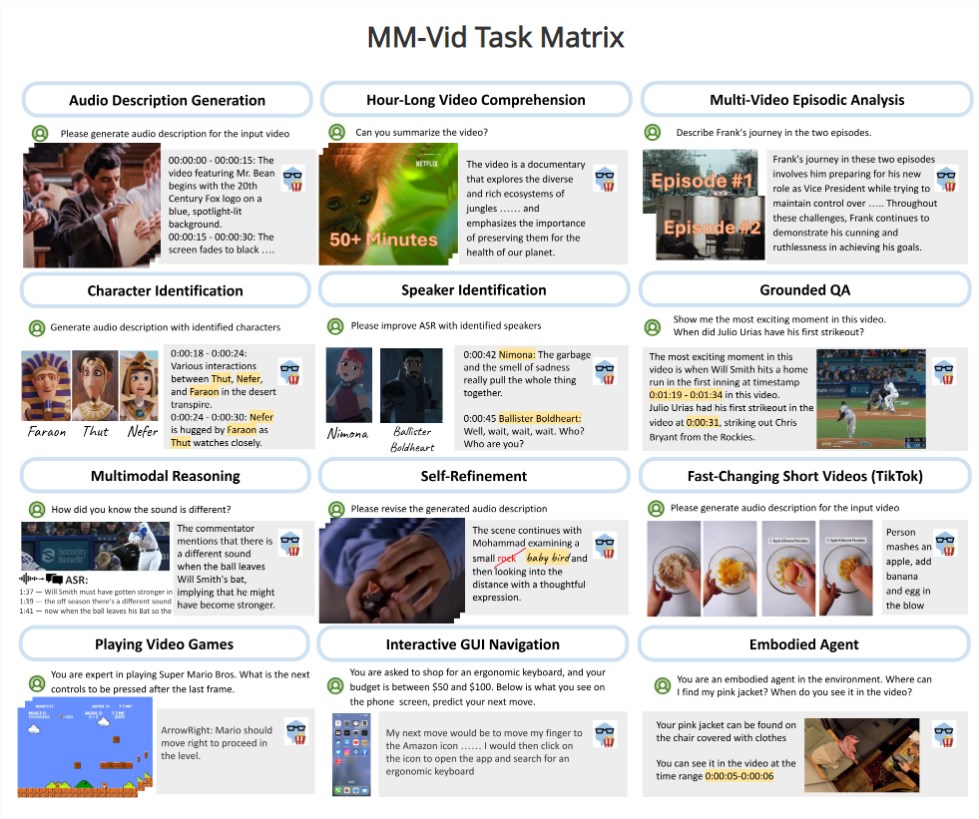
实验证明MM-Vid在任务如问答、多模态推理、人物识别、音频描述等方面表现出色,具备在交互式环境中持续接收流视频帧输入的能力。
近期,微软Azure AI发布了MM-Vid,这是一项结合GPT-4V与专用工具的创新,致力于解读长视频并为视障人士提供更好的体验。
目前,人工智能在长视频理解领域所面临的复杂挑战,包括分析多个片段、提取不同信息源、实时处理动态环境等。而MM-Vid的工作流程,包括多模态预处理、外部知识收集、视频片段描述生成和脚本生成等四个关键模块。通过GPT-4V,MM-Vid能够生成连贯的脚本,为后续任务提供全面的视频理解。
项目地址:https://multimodal-vid.github.io/
实验证明MM-Vid在多个任务上都取得了显著的成果,包括有根据的问答、多模态推理、长视频理解、多视频情景分析等。特别是在人物识别和说话人识别方面,通过采用视觉prompt设计,MM-Vid展现出更高的质量和准确性。
而MM-Vid在交互式环境中的应用,如具身智能体和玩视频游戏,证明其在持续接收流视频帧输入方面的有效性。
综合而言,微软的MM-Vid在大型多模态模型领域取得了显著进展,成功地将GPT-4V与专用工具集成,为视频理解提供了更强大的解决方案,不仅满足了常规视频理解的需求,还为视障人士提供了更丰富的体验。这一创新有望推动视觉领域的发展,使得语言模型在多模态环境下的应用更加广泛。
0000
评论列表
共(0)条相关推荐
ChatGPT、谷歌Bard、微软Bing谁才是AI竞赛的赢家?
六个月前ChatGPT的推出引发了OpenAI、微软和谷歌之间的人工智能聊天机器人竞赛。到目前为止谁才是赢家呢?显然不是谷歌,不过人们对ChatGPT的兴趣正在减弱。美国银行全球研究部的一项调查显示,59%的重度互联网用户使用ChatGPT,其次是51%的人工智能驱动的Bing和34%的谷歌Bard。站长网2023-06-28 18:39:570000Sora竟是用这些数据训练的?OpenAI CTO坦白惹众怒
采访首次揭示出Sora「有所为(比如,将生成效果逼向极限)」和「有所为不为(比如短期内不开放、不生成公众人物)」背后的深层考量——找到一条将AI融入日常生活的正确道路是极其困难的,但也绝对值得一试。站长网2024-03-16 13:45:240000Linux CentOS删除和重命名文件文件夹的命令
Linux、CentOS操作系统下如何删除和重命名文件夹呢?命令如下:一、Linux、CentOS下重命名文件和文件夹mv:move用移动文件命令就可以了,因为linux系统没有专门的重命名命令。基本格式:移动文件:mv文件名移动目的地文件名重命名文件:mv文件名修改后的文件名示例:mvoldfilenewfile(oldfile为旧文件名,newfile为新文件名)000140击败OpenAI,权重、数据、代码全开源,能完美复现的嵌入模型Nomic Embed来了
模型参数量只有137M,5天就能训练好。一周前,OpenAI给广大用户发放福利,在下场修复GPT-4变懒的问题后,还顺道上新了5个新模型,其中就包括更小且高效的text-embedding-3-small嵌入模型。站长网2024-02-04 09:25:080000